DOKTORI (PhD) ÉRTEKEZÉS
KIRÁLY ANDRÁS
Pannon Egyetem
2013.
Pannon Egyetem
Vegyészmérnöki és Folyamatmérnöki Intézet
Döntéstámogató rendszerekben alkalmazható számítási intelligencián és adatbányászaton
alapuló algoritmusok
DOKTORI (PhD) ÉRTEKEZÉS Király András
Konzulens
Dr. Abonyi János, egyetemi tanár
Vegyészmérnöki- és Anyagtudományok Doktori Iskola Pannon Egyetem
2013.
Döntéstámogató rendszerekben alkalmazható számítási intelligencián és adatbányászaton
alapuló algoritmusok
Értekezés doktori (PhD) fokozat elnyerése érdekében
a Pannon Egyetem Vegyészmérnöki- és Anyagtudományok Doktori Iskola Doktori Iskolájához tartozóan
Írta:
Király András
Konzulens: Dr. Abonyi János
Elfogadásra javaslom igen / nem ...
(aláírás) A jelölt a doktori szigorlaton ... %-ot ért el.
Az értekezést bírálóként elfogadásra javaslom:
Bíráló neve: ... igen / nem ...
(aláírás)
Bíráló neve: ... igen / nem ...
(aláírás)
A jelölt az értekezés nyilvános vitáján ... %-ot ért el.
Veszprém, ...
a Bíráló Bizottság elnöke
A doktori (PhD) oklevél minősítése ...
University of Pannonia
Department of Process Engineering
Data mining and soft computing algorithms for decision support systems
PhD Thesis András Király
Supervisor János Abonyi, DSc
Doctoral School in Chemical Engineering and Material Sciences University of Pannonia
2013.
Köszönetnyilvánítás
Köszönettel tartozom els®sorban témavezet®mnek Dr. Abonyi Jánosnak a sokszor már végtelennek t¶n® türelméért valamint folyamatos szakmai út- mutatásaiért és baráti támogatásáért.
Hálás vagyok egész családomnak és barátaimnak hogy bármikor számít- hattam szeret® támogatásukra, megteremtve ezzel azt a biztos lelki hátteret mind egyetemi, mind a doktorandusz évek során, mely elengedhetetlen a kreatív munkavégzéshez.
Köszönöm továbbá dr. Gyenesei Attilának hogy lehet®séget teremtett számomra a turkui kutatómunkára, valamint a Finnish Microarray and Se- quencing Centre valamennyi munkatársának hogy szakmai támogatásukkal segítették munkámat, melynek eredményeként létrejöhetett a dolgozat 4. fe- jezete.
Ugyancsak köszönöm a Pannon Egyetem Folyamatmérnöki Intézeti Tan- szék valamennyi munkatársának, különösen Dobos Lacinak és Borsos Ákos- nak az éveken át (és azóta is) tartó szakmai és emberi segítséget.
Kivonat
Döntéstámogató rendszerekben alkalmazható számítási intelligencián és adatbányászaton alapuló algoritmusok
A döntéstámogató rendszerek olyan plusz tudást képesek adni a döntéshozók kezébe, melyek naprakész ismereteket szolgáltatnak mind a vállalat folya- matairól mind a küls® környezetr®l, biztos alapot teremtve ezzel a helyes döntésekhez. A jelen munkában ismertetésre kerül® módszerek és eszközök segítségével pontosabban modellezhet®k a vállalatban lejátszódó folyamatok;
kezelhet®k a rendszerekben fellép® bizonytalanságok; hatékonyabban elemez- het®k a rendelkezésre álló adatok. Az ismertetésre kerül® technikák mind- egyike konkrét ajánlásokat szolgáltat a döntéshozók részére.
A dolgozat komplex rendszerek elemzésével és optimalizálásával foglalko- zik, melyek mindegyike valamilyen gyakorlati probléma megoldását szolgál- tatja. Logisztikai problémák kapcsán olyan útvonalhálózat-tervezési metó- dust ismertet, mely új genetikus algoritmus és reprezentáció alkalmazásával képes egy 600 mobilszerel®t ellátó hálózat optimális felépítésének ajánlásá- ra. Többszint¶ raktározási problémák robosztus optimálására újszer¶ szi- mulátort vezet be, melynek segítségével többféle optimalizációs eljárás kerül tárgyalásra. Továbbá a be- és kimenetek változásai közötti kapcsolatok feltá- rásával újszer¶ döntéstámogató eszközt ismertet. Bioinformatikai eljárások során keletkez® génexpresszió adatokból történ® hasznos információ kinyeré- sére pedig új biclustering algoritmusok és elemzési tevhnikák kerülnek ismer- tetésre.
Az egyes fejezetekben ismertetett metódusok közös vonása a döntéstámo- gató rendszerekbe történ® integrálás lehet®sége, ugyanakkor a köztük lév®
kapcsolat inkább marginálisnak mondható. Így a dolgozat a klasszikus felépí- tés helyett három mer®ben eltér® probléma különböz® módszerekkel történ®
megoldását ismerteti.
Abstract
Data mining and soft computing algorithms for decision support systems
Decision support systems are capable to give additional information for deci- sion makers which represent up to date knowledge about the enterprise pro- cesses as well as about the environment, greatly supporting their work and decreasing the pressure of responsibility. Methods and techniques presented in this work provides up to date knowledge and tools to model enterprise processes more accurately; to handle uncertainties during these processes;
to analyze available data more correctly. The discussed techniques provides concrete support for decision makers.
The thesis presents the analysis and optimization of complex systems pro- viding a solution for real problems. A route planning method is described which is capable to propose optimal vehicle route system supplying 600 mo- bile mechanics of Hungary's leading energy provider, introducing a novel ge- netic representation based eective genetic algorithm. It presents several op- timization techniques for multi-echelon inventory management systems which is based on a novel robust simulation technique using Monte Carlo method.
Furthermore a benecial decision support system is demonstrated by the parameter sensitivity analysis of these systems. To retrieve valuable infor- mation form gene expression data new biclustering algorithms and methods are presented.
Although the possibility of integration into decision support systems are common in methods presented in the chapters of the thesis, but the relation- ship between them is rather marginal. Thus, instead of the classical structure, the dissertation proposes three dierent solutions for three distinct problems.
Auszug
Algorithmen aufgrund der Berechnungsintelligenz und Datenabbau für Decision Support Systeme
Decision Support Systeme stellen den Entscheidungsträgern zusätzliches Wis- sen zur Verfügung, das die Leiter über die Prozesse des Unternehmens, über seine innere Umgebung auf dem Laufenden halten, und legt damit einen sicheren Grund für richtige Entscheidungen. Die in der Arbeit dargestell- ten Methoden und Instrumente bieten aktuelles Wissen, mit dessen Hilfe die Prozesse des Unternehmens besser modelliert werden können; die Ungewis- sheit innerhalb der Systeme besser behandelt werden können; die verfügbaren Daten besser analysiert werden können. Alle darzustellenden Instrumente bi- eten konkrete Empfehlungen an Entscheidungsträger.
Die Arbeit beschäftigt sich mit der Analyse und Optimierung der kom- plexen Systeme, die zur Lösung konkreter, realer Probleme dienen. Eine neue Routenplanung-Methode wird unter logistischen Problemen beschrieben, die mit Anwendung eines neuen genetischen Algorithmus und Repräsentation fähig ist, den optimalen Aufbau eines realen, 600 Mobilinstallateur versor- genden Netzwerkes zu empfehlen. Ein neuer Simulator wird dadurch zur Optimierung der konkreten mehrseitigen Lagerungsprobleme eingeführt, und mit Hilfe des Simulators werden mehrere Optimierungsverfahren erörtert. Im Weiteren werden konkrete Instrumente zur Beschlussfassung klargestellt, mit Aufdeckung der Beziehungen zwischen Ein-und Ausgang. Neue Bicluster- ing -Algorithmen werden zum Gewinn der nützlichen Information aufgrund der in bioinformatischen Verfahren entstehenden Gene Expression Daten dargestellt. Die zur Methode herausentwickelten Instrumente dienen auf in- tegrierter Weise zur Prozessoptimierung und Beschlussfassung.
Obwohl die einzelnen Kapitel einen gemeinsamen Charakter haben, die Möglichkeit der Integration in das die Beschlussfassung unterstützende De- cision Support Systeme, kann die Beziehung zwischen Ihnen lieber marginal genannt werden. So legt die Arbeit die Lösung von drei völlig divergenten Problemen mit verschieden Mitteln dar, statt einen klassischen Aufbau zu haben.
Contents
1 Introduction 1
2 Optimization of multiple traveling salesman problem by a novel representation based genetic algorithm 6 2.1 Motivation, literature review, roadmap . . . 7 2.2 Theoretical background and algorithm development . . . 10 2.2.1 Problem formulation . . . 10 2.2.2 Introduction to traveling salesman specic GAs . . . . 13 2.2.3 A novel way to solve MTSP with GA . . . 19 2.2.4 Numerical analysis of the proposed method . . . 22 2.3 A Google Maps based framework developed to utilize the pro-
posed algorithm . . . 29 2.4 Application study . . . 31 2.5 Conclusions . . . 35 3 Monte Carlo simulation based optimization and analysis of
inventory management systems 36
3.1 Introduction . . . 36 3.2 Determining optimal safety stock level in multi-echelon supply
chains . . . 37 3.2.1 Classic inventory model of a single warehouse . . . 39 3.2.2 The proposed stochastic inventory model . . . 41 3.2.3 A simulation-based multi-echelon warehouse model . . 43 3.2.4 Particle Swarm Optimization Algorithms . . . 48 3.2.5 The proposed Constrained PSO Algorithm . . . 51 3.2.6 Further improvement of PSO algorithm by memory-
based gradient search . . . 53 3.2.7 Stochastic optimization of multi-echelon supply chain
models by improved PSO algorithm . . . 60 3.3 Monte Carlo Simulation based Performance Analysis of Supply
Chains . . . 65
3.3.1 The proposed framework for sensitivity analysis of sup-
ply chains . . . 67
3.3.2 Sensitivity analysis of a multi-echelon supply chain prob- lem . . . 71
3.4 Conclusions . . . 75
4 Biclustering algorithms for Data mining in high-dimensional data 76 4.1 Introduction . . . 76
4.1.1 Literature review . . . 78
4.2 Problem formulation . . . 80
4.2.1 Biclustering . . . 80
4.2.2 Frequent closed itemset mining . . . 82
4.2.3 Connection between biclustering and frequent closed itemset mining . . . 82
4.3 Ecient methods for bicluster mining . . . 83
4.3.1 A novel way to mine closed patterns . . . 84
4.3.2 Transformation of {−1,0,1} data to binary data . . . . 88
4.3.3 Closed pattern based data visualization . . . 89
4.3.4 Method for the aggregation of closed patterns . . . 90
4.3.5 Experimental results . . . 93
4.3.6 Remark for other methods . . . 97
4.4 Bit-table representation based biclustering . . . 97
4.4.1 MATLAB implementation of the proposed algorithm . 102 4.4.2 Computational results . . . 104
4.5 Biological validation of discovered patterns . . . 104
4.5.1 Comparison of biclustering methods . . . 107
4.6 Conclusions . . . 109
5 Summary and Theses 111 5.1. Tézisek . . . 112
5.2 Theses . . . 115
5.3 Publications related to theses . . . 117
List of Figures and Tables 121
Bibliography 126
Chapter 1 Introduction
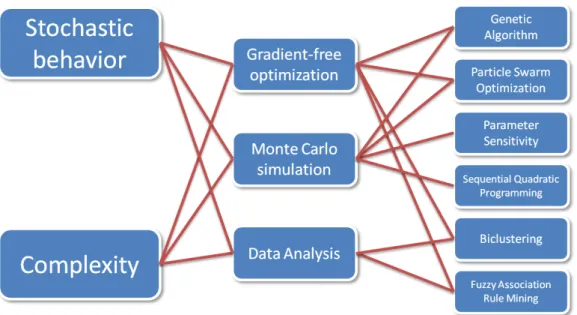
In the last decades, optimization was featured in almost all aspects of human civilization, thus it has truly become an indispensable method. In some aspects, even a local optima can highly improve the eciency or reduce expenses, however, most companies want to keep their operational costs as low as possible, i.e. on global minimum. Most of the problems come up in industrial environment suer some kind of risk or uncertainty, and their complexity is too high for traditional methods to provide acceptable results in applicable time. All three theses presented in the dissertation have a common property in high complexity which requires new or novel methods to handle them. A potential solution of these problems can be addressed as it is depicted in Fig. 1.1 which corresponds to the structure of the dissertation.
Because of the high complexity of problems, gradient based optimization methods are too expensive computationally thus their running times are too long, therefore some gradient-free optimization technique has to be used like Genetic algorithm, (chapter 2) Particle Swarm Optimization (chapter 3) or Biclustering and Frequent Closed Itemset Mining (chapter 4). High complex- ity also necessitates the usage of simulation, as we will see in a minute the application of Monte Carlo simulation has serious advantages (chapter 3), and appropriate analysis of initial data (e.g. transformation) can also help handling complex or high dimensional data (chapter 4).
Although the three thesis has several common properties, they deal with dierent problems and provide dierent approaches for solution. Therefore, the dissertation doesn't follow the traditional way, but presents three dierent problems with three dierent solution procedure and the connection between the chapters is rather fragile.
So the main problems motivated this research can be divided into 3 areas.
First one is a logistical problem derived from an industrial problem, which came up at E.ON Hungária Zrt., the leading energy provider of Hungary.
Figure 1.1. The applied technologies by problem characteristics.
The company installs consumption meters, while it also renovates consump- tion sites, and eliminates malfunctions reported by clients. The activities of the 600 mobile mechanics are controlled by a Field Service Management Sys- tem (FSMS) with the target: dynamic optimization of planned/unplanned maintenance tasks in the power/gas network. Since the travel for material of mobile mechanics is a non-productive task within the FSMS, the supply of the 600 mobile mechanics from 20 warehouses (regional, central) represents a complex and economically important problem of the E.ON Network Services Kft. Stochastic behavior and high complexity appearing together requires the application of a computer-based decision support tool using advanced searching, simulation or analysis tools. Because of their transparency, natu- ral behavior and ecient searching capabilities, evolutionary techniques are often used providing useful results to help decision makers in their judgment.
Researchers have recognized that traditional analytical (linear programming, exhaustive enumeration) and heuristic approaches are inecient and inexi- ble when solving highly complex tasks. Heuristic rules can perform well over several problems, but the optimal solution is not guaranteed. Mathemati- cal models can guarantee the optimal solution but it can be meaninglessly complicated to build the model and the solution requires extensive computa- tional eorts. To overcome above problems, evolutionary computation (EC) [42] can provide a viable alternative. Genetic Algorithms (GAs) belong to the class of EC methods and have been used in several research area to support
decision making, like for the solution of various synthesis [55] or for support- ing multi-objective economic decisions [33]. Therefore we present a novel genetic algorithm to solve the supply problem of mobile mechanics. The new dynamic approach presented in chapter 2 aims a signicant reduction of ac- tivities regarding material handling for the mobile teams with extending of serving locations from 20 to 100. The design of the supply system can be considered as a complex combinatorial optimization problem, where the goal is to nd a route plan with minimal route cost, which services all the de- mands from three central warehouses while satisfying the capacity and other constraints.
The second problem is also derived from E.ON Hungária Zrt., where the average holding cost in warehouses has to be minimized. This inventory man- agement problem includes uncertainty in daily consumption from warehouses and in replenishment lead times which is the time between orders and actual transportation of goods. Decision makers need to know the eects of risk during business processes and this uncertainty is often described by prob- abilistic models. The Monte Carlo (MC) method is a robust technique to handle these uncertainties and thus to reduce decision making problems. A detailed explanation of the usage of Monte Carlo estimators can be found in [142], where authors solve stochastic programming problems by nite series of Monte Carlo samples and applies the results to support decision making as well.
Another probability to handle the uncertainties is the analysis of the sen- sitivities of the parameters. The goal of sensitivity analysis is to describe how much model outputs are aected by the inputs of the model [102]. In chap- ter 3, a novel visualization technique for sensitivity analysis will be described through the analysis of a multi-echelon inventory management system.
The presented Monte Carlo method based simulator in chapter 3 is capa- ble to handle these risks providing a robust and modular modeling technique.
Using simulation, the average holding cost can be calculated in each ware- houses, and the overall expenses can be optimized while constraints for ser- vice level has to be taken into account. Managers of the previously mentioned company necessitates a robust tool to support their decisions. In chapter 3 a novel visualization technique will also be presented to provide easily in- terpretable representation of relationship between a multi-echelon warehouse system's inputs and target variables.
The third research area is the eld of cell biology, where the task is to nd co-regulated gene proles in microarray Gene Expression Data (GED). Data is presented as a huge matrix with real numbers representing the expression levels of genes in given samples. Data are retrieved from DNA microarrays
which contains the measurement of mRNA levels in particular cells or tissues for many genes at once. These data are generated e.g. in Finnish Microar- ray and Sequencing Centre in Turku. Firstly data has to be cleaned and discretized, and some clustering method needs to be used to identify similar genes or samples i.e. subparts of the matrix containing strongly correlated values. Two methods will be presented in chapter 4 for this task which is called biclustering.
The main motivation of the work is to develop novel techniques which are robust, ecient and transparent enough to solve highly complex problems in reasonable time in an easily interpretable way. A large part of the eorts was expended to model a complex industrial problem as realistic as possible.
The second chapter realizes these expectations with the usage of real trans- portation data and a novel, more realistic genetic representation, using them during the optimization process. As it will be presented in the third chapter, a novel simulator was built to provide simulation of inventory management much more close to reality which can handle uncertainty in consumption data. The fourth chapter deals with fast algorithm which is extremely easily interpretable, using simple matrix operations and working on real biologi- cal data. As another important objective, theses present software solutions realizing the novel methods, providing user-friendly implementations to col- lect or generate input data, handle uncertainty, optimize complex tasks or analyze the results.
According to the motivations and objectives described above, the struc- ture of the thesis is the following. Chapter 2 describes a complete opti- mization framework to solve the modied multiple traveling salesman prob- lem which corresponds to the logistical problem of EON Hungária Kft. As we saw during the literature review, using evolutionary computation, these problems can be handled eectively. Therefore, the chapter proposes a new genetic representation and a novel genetic algorithm which can handle ad- ditional constraints and an integrated Google Maps based software package for the maintenance of the whole optimization process providing a complete DSS.In chapter 3 the determination of optimal safety stock level in multi- echelon supply chains is presented as well as the sensitivity analysis of the system parameters. Handling uncertainty has a wide literature, and most of them use Monte Carlo method as a robust simulation technique. Thus, the chapter describes a novel novel component based simulator, SIMWARE to handle uncertainty in the model using Monte Carlo method and applies two optimization methods to determine the optimal safety stock and minimize overall costs. A novel performance analysis framework is also presented here,
where by the help of the new visualization technique an eective decision support tool is proposed.
Since our third problem derived from the analysis of high dimensional data, novel data mining techniques are presented in Chapter 4. The chapter introduces novel algorithms for biclustering and for closed frequent pattern mining in binary or in {−1,0,1} data and oers several techniques to com- pose a complete framework in frequent closed itemset mining.
Chapter 2
Optimization of multiple traveling salesman problem by a novel
representation based genetic algorithm
The aim of logistics is to get the right materials to the right place at the right time, while optimizing a given performance measure (e.g. minimizing total operating cost) and satisfying a given set of constraints (e.g. time and capacity constraints) [53]. Supply chain management includes the planning and management of all activities involved in sourcing, procurement, conver- sion, and logistics management as well as crucial components of coordination and collaboration. It deals with several problems, like Distribution Network Conguration, Trade-Os in Logistical Activities, Inventory Management or Distribution Strategy [56]. In most distribution systems goods are trans- ported from various origins to various destinations. For example, many retail chains manage distribution systems in which goods are transported from a number of suppliers to a number of retail stores. It is often economical to consolidate the shipments of various origin-destination pairs and transport such consolidated shipments in the same truck at the same time. There are many ways in which such consolidation can be accomplished. Obviously the challenge is to nd the optimal i.e. the best consolidation according to some objective functions [35]. This is a numerical optimization problem, com- monly an NP-hard task. In logistics, several types of problems could come up; one of the most remarkable is the set of route planning problems.
2.1 Motivation, literature review, roadmap
The major motivation of the work presented in this chapter is derived from a real industrial problem, which came up at E.ON Hungária Zrt., the leading energy provider of Hungary. E.ON Network Services Kft. provides services primarily to the electricity and gas supply companies of the E.ON Hungária Group. This service includes the full range of operations management activi- ties carried out with a view to ensuring uninterrupted energy supply, regular maintenance of network objects, and the elimination of disruptions associ- ated with malfunctions. In addition, the company installs consumption me- ters, while it also renovates consumption sites, and eliminates malfunctions reported by clients.
As it will be presented later in sec. 2.4, this industrial problem can be modeled as an mTSP problem with time windows and additional constraints, therefore, the mTSP related literature will be reviewed here. In the last two decades the traveling salesman problem (TSP) received a large amount of interest, and various approaches have proposed to solve the problem, e.g.
branch-and-bound [60], cutting planes [111], neural network [39] or tabu search [67]. Some of these methods are exact algorithms, while others are near-optimal or approximate algorithms. The exact algorithms usually use integer linear programming approaches with additional constraints.
Although TSP has received a great deal of attention, the research of mTSP is limited. [36] gives a comprehensive review of the known approaches.
There are several exact algorithms of the mTSP with relaxation of some constraints of the problem, like [96], which is the rst approach to solve the mTSP directly, without any transformation of the TSP. In this problem, each salesman has a xed initial costf, which is activated whenever a salesman is included in the solution. The solution in [30] is based on Branch-and-Bound algorithm, which is applicable for asymmetric, as well as symmetric problems.
Another exact solution method is in [73]. The approach of Gromicho et al.
is based on a quasi-assignment relaxation obtained by relaxing the subtour elimination constraints (SECs).
Recent research can be found in [59], where mTSP is optimized by a mixed method. Feng et al. combined Particle Swarm Optimization with Ant Colony Optimization to nd the best solution of the problem. Another recent solution is presented in [118] where Nallusamy et al. used K-Means Clustering, Shrink Wrap Algorithm and Meta-Heuristics to solve the mTSP.
A multi-objective approach can be found in [62], where the multiple objective ant colony optimization is used for the bi-criteria TSP. Ant colony optimiza- tion for mTSP is used very recently in [66], where Ghafurian and Javadian provide a solution for the multi-depot mTSP. In [64] a xed destination vari-
ant of mTSP is solved by the help of simulated annealing.
Lately GAs are also used for optimization of mTSP. The previous GA- based solutions will be discussed later in the article. In the literature there are several examples that a good problem-specic representation can dra- matically improve the eciency of genetic algorithms. A problem-specic individual design can reduce the search-space, and in this case, it is needed to implement special operators which can simulate the nature of the prob- lem. These properties can make the problem-specic genetic algorithm more eective for the given task, and it becomes more easily interpretable.
GAs are direct, random search algorithms, based on the evolutionary model [68, 42], related with Darwin's evolutionary theory. The researches of GAs have begun in the sixties by J.H. Holland [81]. GAs belong to the evo- lutionary computation (EC) methods [32], thus their terminology is closely related to biology. Each solution of the problem, or equivalently, each point in the search space is represented by an individual who consists of chromo- somes, while chromosomes are composed of genes. Individuals constitute a population, which contains all possible solutions. The method is based on the collective learning process of the population. The individuals are im- proved in the course of iterations by the partway forthcoming operators, like selection, crossover and mutation.
Recently, GAs are successfully implemented to solve TSP [63]. Potvin presents a survey of GA approaches for the general TSP [130]. In case of mTSP, due to its combinatorial complexity, it is necessary to apply some heuristic in the solution, especially in real-sized applications. One of the rst heuristic approach were published by Russell [140] and another procedure is given by Potvin et al. [131]. The algorithm of Hsu et al. [82] presented a Neural Network-based solution. Lately GAs are used for the solution of mTSP too. The rst result can be bound to Zhag et al. [173]. Most of the work on solving mTSPs using GAs has focused on the Vehicle Scheduling Problem (VSP) [107, 122]. VSP typically includes additional constraints, like the capacity of a vehicle (it also determines the number of cities each vehicle can visit), or time windows for the duration of loadings. Recent application can be found in [157], where GAs were developed for hot rolling scheduling. There are no constraints on the route lengths of the salesmen, and it introduces a lot of dummy nodes and some additional binary variable, thus it can convert the mTSP into a single TSP and apply a modied GA to solve the problem. You et al. [169] use GAs to solve the mTSP in path planning. A dierent approach of chromosome representation, the so-called two-part chromosome technique can be found in [49], which reduces the size of the search space by the elimination of redundant solutions.
As we mentioned earlier, our work is derived from an industrial problem, where an eective, easy-to-use and fast application is needed to oer a feasi- ble and near-optimal solution for the redesign of supply of mobile mechanics.
The main motivation of our research was the lack of an algorithm which is
"intelligent" enough to handle constraints on tour length, asymmetric dis- tances, or where the number of salesmen is not predened, and can vary during the evolution of individual solutions. As we have become familiar with a real industrial problem, these features are required for an optimiza- tion tool to provide a solution which can be used in practice. To satisfy these conditions, a rened mathematical representation is needed, which re- ects the compound character of the cost function. Furthermore, almost all previous solutions of mTSP with GA have used a single chromosome to rep- resent the whole solution, i.e. to represent each salesman, although salesmen in mTSP are separated from each other physically. Our main expectations were to research a novel genetic method, which can support not only the implementation, but the initialization and heuristic ne-tuning of the indi- vidual routes easily. To satisfy this expectation, we have developed a novel genetic algorithm using a dierent representation to solve mTSP. Based on this representation, a set of novel genetic operators are dened to modify the individuals accurately enough. To improve the eciency of the operators, we have developed complex operators, which combine multiple simple operators.
To prove the necessity and accuracy of the novel representation, a compre- hensive analysis is presented comparing our method with the best published approaches, and supplementary resources are published on our website, de- tailing further tests. Furthermore a novel automated tool was developed to provide a complete solution for the redesign of the supply of mobile mechan- ics at Hungary's leading energy provider. The implemented tool is capable to optimize a logistic problem necessitating only a map dened on the Google Maps web interface. We used the automated tool to support our detailed tests also, wherewith the necessity of the research is proven.
In the next sections, rstly, the mathematical denition of the problem will be given together with the current problem's cost function. Thereafter an introduction of genetic algorithms will be presented followed by the dis- cussion of previous genetic representations for mTSP. It is manifest from the earlier approaches, that single-chromosome representations could not repre- sent the nature of mTSP suciently, thus multi-chromosome representation should be used. A novel GA-based solution will be presented using this chromosome type, which is realized by an algorithm written in MATLAB.
Thereafter, the complexity analysis of the multi-chromosome representation, and detailed statistical analysis of the novel algorithm will be presented in
Sec. 2.2.4. Sec. 2.3 discusses the concept of the automated Google Maps based framework, while Sec. 2.4 gives a comprehensive view about the main motivation of the article, a real optimization problem and application for one of the biggest Hungarian companies. The application study in this section presents to automated Google Maps based framework in details, which allows users to dene the input, retrieve the coordinates, run the optimization and visualize the results in a straightforward, user-friendly way. The last section contains concluding remarks and future plans.
2.2 Theoretical background and algorithm de- velopment
The motivating problem can be modeled as an mTSP problem with time windows. In this section the problem's mathematical formulation will be given and the novel genetic operators and algorithm will be presented. In this section we will present the eciency of multi-chromosomal genetic repre- sentation and how this projection can be further developed by novel complex operators. Therefore, a short overview of the used genetic representation will be followed by the description of the novel operators and the eciency of the resulted algorithm will be illustrated by simulation results.
2.2.1 Problem formulation
As it was mentioned earlier, the main problem what this work based on is derived from the industry, where the supply of mobile mechanics is very unprotable, thus it's needed to redesign the whole supply chain. As far as we know, there is no standard tool that can solve mTSP related optimization tasks and can easily handle map based visualization of inputs and outputs.
This absence of usable tool makes the mTSP problem presented in this section an unanswerable question for most companies.
In case of mTSP, a set of n nodes (locations or cities) are given and m salesmen are located at a single depot node. The remaining nodes or cities that are to be visited are the intermediate nodes. Then, the goal is to nd tours for all m salesmen, who all start and end at the central depot, such that each intermediate city is visited exactly once, and the total travelling cost (the cost of visiting all nodes) is minimized. The cost metric can be dened in terms of distance, time, etc. The possible variations of the problem can be found in [36] and [74]. In our case, the problem can be dened as an asymmetric multiple Traveling Salesman Problem with Time Windows (mTSPTW) with additional special constraints, where the number
of salesmen is an upper bounded variable. The determined constraints are the following: maximum number of salesmen; maximum travelling time / distance of each salesman; time window at each location.
Usually, mTSP is formulated by dierent type of integer programming formulations. Before presenting the model of the modied mTSP mentioned above, some technical denitions will be given. The mTSP is dened on a graph G = (V, A), where V is the set of n nodes (vertices) and A is the set of arcs (edges). Let C = (cij) be a cost (distance or duration) matrix associated with A. The matrix C is symmetric when cij = cji,∀(i, j) ∈ A and asymmetric otherwise. Ifcij +cjk ≥cik,∀i, j, k∈V, C is said to satisfy the triangle inequality.
The problem which is analyzed in this article is more complex than the traditional mTSP problem. It is a so-called mTSPTW [36] with additional constraints, which can be formulated as follows. Let us dene the following binary variable:
xijk =
1 if arc (i, j)is used on the tour of the kth salesman 0 otherwise
Let's deneM as the maximum number of salesmen, andS as the maximum length of any tour in the solution. Furthermore, let's dene the cost (distance or duration) matrix associated with A as Ct = (ctij), where ctij = cij +ctwj , and cij is the ordinary cost (e.g. the driver's wage, which is proportional to distance) of the arcij, and ctwj is the cost of the time window. Time window means, that every salesman has to wait in each location, which can be e.g. the duration of loading the goods. Obviously, Ct can't be a symmetric matrix, since in a real life applicationcij 6=cji,∀(i, j)∈A, because of there can exist e.g. one-way roads. Thus, the optimization problem can be given as follows.
If we use the newly introduced binary variable, the usual assignment- based objective function is altered into equation (2.1), where the cost of the involvement of a salesmen appears too (cm). (2.2) - (2.5) are the usual assignment constraints, using the binary variablexijk, and (2.7) ensures that the tour length of each salesmen is under the specied bound, S.
minimize
n
X
i=0 n
X
j=0
ctij ·
m
X
k=1
xijk+m·cm (2.1) s.t. n
X
j=1 m
X
k=1
x1jk =m, (2.2)
n
X
j=1 m
X
k=1
xj1k =m, (2.3)
n
X
i=0 m
X
k=1
xijk = 1, i= 2, . . . , n, (2.4)
n
X
j=0 m
X
k=1
xijk = 1, j = 2, . . . , n, (2.5) + sub tour elimination constraints, (2.6)
n
X
i=0 n
X
j=0
ctij ·xijk≤S, k= 1, . . . m, (2.7) xijk ∈ {0,1},∀(i, j)∈A,1≤k≤m,1≤m ≤M (2.8) In most of real applications the cost of a delivery has to include several factors, thus the cost function in (2.1) becomes more complicated. So we can express the cost of a transport in the following way: ctij = cij +ctwj , where cij =Pn
q=1wq∗c(q)ij andctwj =Pn
q=1wqtw∗ctw(q)j , wherews are weights. These factors can be e.g. the wage of the driver, the consumption of the truck, or the toll on a highway. Dierent drivers' wage can be dierent, and obviously, the consumption of the truck can be dissimilar, thus we have to use weights for these costs. This approach can be associated with a multi objective model, as it can be seen in several works in the literature, like in [145] and in [85].
However the aggregation of these cost factors is self-evident enough, because every part of the denoted cost function can be expressed in currency, e.g. in USD or in HUF. Thus, the main task remains a single-objective optimization problem, which can be solved by the help a novel approach, which will be proposed by the authors in the next sections.
Furthermore, if we want to add penalty for the salesperson who reaches the maximal tour length, the above formalism will change slightly. Let
n
X
i=0 n
X
j=0
ctij ·xijk =Ek, k = 1, . . . m, (2.9)
Thus, equation (2.1) is changed in the following way:
minimize
m
X
k=1
(Ek+λ·max(Ek−S,0)) +m·cm (2.10) In (2.10), the penalty is proportional to the tour length of a salesmen above the upper bound S, while the degree of the punishment is determined by the constantλ, which value much depends on the range ofcij. Note that another sort of penalty could be a cuto of the route of a salesman who reaches the upper bound.
2.2.2 Introduction to traveling salesman specic GAs
Since the main novelties of the research are the new genetic operators and the novel genetic algorithm using these operators, a short introduction of GAs and an overview of the most related approaches to solve TSP and mTSP problem using GAs are presented here.
GA starts with an initial solution set, which contains individuals created randomly. This is called initial population. The initial step can mightily improve the eciency of the algorithm, thus a good starting strategy can be momentous. The new population is always generated from the actual population's participants by the genetic operators. The generation of new populations is continued until a predened stop criteria is satised.
Figure 2.1 shows the general case of GA's life cycle. Obviously in a spe- cic problem, this process can be much more complicated, almost in every step specic realization can be required. The rst important task is to choose the encoding of the chromosomes, considering crossover and mutation oper- ators. A very important problem is the determination of parents. Several opportunities exist, but most often the algorithm selects the participants with a better attribute with bigger probability (or with better tness value).
The reason of this consideration is that individuals with better tness could produce descendants with better properties.
If the new population was composed from the newly created descendants only, the old population's best individual could lost. To eliminate this de- ciency, a new approach, the so-called elitism was introduced. This method ensures that the previous population's best individual will get into the new population without any modication, thus the best found solution will sur- vive during the whole evolutionary process.
Figure 2.1. The life cycle of genetic algorithms.
Encoding
The encoding of the problem is the mapping of the phenotype to the geno- type, while decoding is the inverse operator, calculating the parameters of phenotype from the genotype. Genotype codes the genetic information of the individual, which is the representation of the problem. The crossover and mutation operators operates on the genotype. The related encoding techniques to mTSP is reviewed below.
Permutation encoding Permutation encoding is only used in ordering problems, such as Traveling Salesman Problem or task ordering problem.
Every chromosome is a string of numbers, which represents number in a se- quence. This technique can be useful for ordering problems, however, special operators are needed to keep the new individuals consistent after crossover and mutation (see Fig. 2.2).
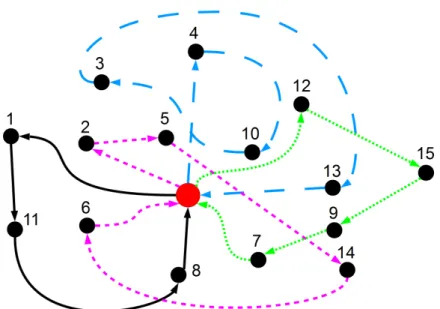
Encoding related to mTSP Every previous representation for mTSP uses permutation encoding. A simple example route-system is represented on Fig. 2.3. The following representations will encode this problem into the genes of the chromosomes.
The rst approach was the so-called one chromosome technique [173],
which is illustrated on Fig. 2.4. It uses a single chromosome of length (n+m−1) (n is the number of locations and m is the number of sales- men). The cities are represented by a permutation of integers from 1 to n. This permutation is divided intom subtours by the insertion of m−1nega- tive integer values, which represents the turn from one salesmen to the next.
The cities in a subtour is in the order of the visitation of the salesman. Using this chromosome representation, there are (n+m−1)! possible solutions of the problem.
Fig. 2.5 illustrates another approach for chromosome representation of solutions in mTSP (with n = 15 and m = 4), the so-called two chromosome technique. This method requires 2 chromosomes, each of length n. The rst chromosome contains a permutation of the n cities, and the second one assigns a salesperson to each locations in the same position of the rst chromosome. Using this representation, the search space (i.e. the number of possible solutions) is n!·mn.
A quite new approach of chromosome representation, the so-called two- part chromosome technique can be found in [49] which reduces the size of the search space by the elimination of redundant solutions. As Fig. 2.6 shows this approach represents a solution by a single chromosome. The rst part is a permutation of integers from 1 to n (number of locations), representing the n cities, and the second part of the chromosome represents the number of cities assigned to each of the m salesperson.
Evaluation of population
The evaluation of population is done by calculating the tness value for each individual, which is a real number. Each individual has an objective- score which is calculated by the algorithm. The tness is calculated from the objective score with a possibility of taking the other individuals into account.
The objective score is an intrinsic parameter to the optimization problem, thus it could not be modied to enhance the evolution process. However, the mapping of objective score to tness value makes it available to adjust the goodness of an individual for selection.
Figure 2.2. Permutation encoded chromosomes.
Figure 2.3. Example route-system with 15 cities and with 4 salesmen.
Figure 2.4. Example of one chromosome representation for a 15 city mTSP with 4 salesperson ([49]).
The type of objective-score to tness mapping is either scaling or ranking.
In case of scaling, the tness is a function of the objective-score, while in the case of ranking, the population are sorted according to the objective- score, and the tness value of the individuals depend on the position in the ranking. Note that in many cases, objective-score and tness value are identical (f(x) =x).
In case of mTSP usually the objective-score and equivalently the tness value of an individual is the sum of distances (durations) travelled by each salesman. The additional constraints like maximal overall travelling distance refers to this value. If a solution exceeds this constraints, some punishment will be applied, like a proportionately huge tness value, or the application of a special penal operator.
Figure 2.5. Example of two chromosome representation for a 15 city mTSP with four salesperson ([49]).
Figure 2.6. Example of two-part chromosome representation for a 15 city mTSP with 4 salesmen ([49]).
Operators
A big number of genetic operators can be found in the literature, general ideas are presented in [40, 63, 68], operators for sequencing problems are in [61]. Expressly multi-chromosomal approach can be found in [127], and operators refer to TSP is presented in [109]. In the following sections only a theoretical overview will be given.
Selection During GA, two kind of selection exist: selection for reproduc- tion and selection for survival. The former selects the individuals form the population for reproduction (parents), and the latter selects the individuals of the new population. This section presents a widely used selection tech- niques for reproduction, which is used by the novel algorithm presented in later sections. A detailed description of selection schemes is presented in [40].
Using tournament selection, individuals are chosen from the popula- tion randomly for the so-called tournament, in which the individual with best tness is selected as the winner. The number of chosen members for
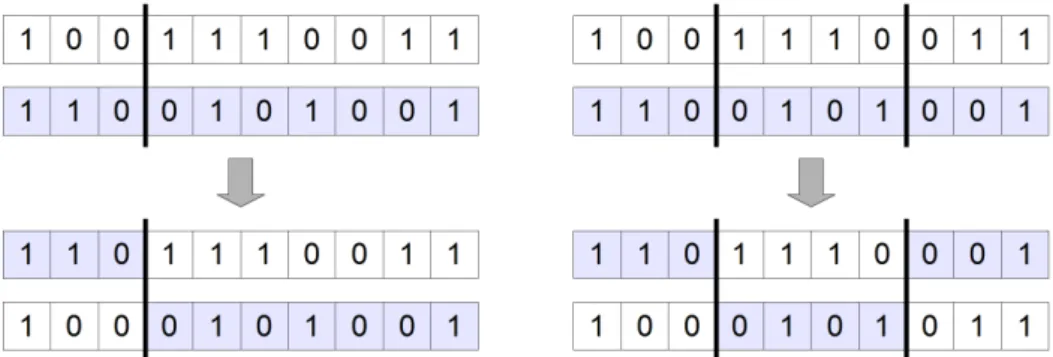
Figure 2.7. One-, and two-point crossover of binary encoded individuals.
Figure 2.8. Mutation of binary encoded individuals.
the tournament is determined by the tournament size(t), which is between 2 and µ, where µ is the size of the population. The winner can either be removed from, or kept in the population, if it is allow or disallow to select an individual multiple times. Tournament selection has a time complexity of O(N). The selection pressure is adjustable by the size of the tournament.
Crossover Crossover or recombination creates new individuals from the genes of the parents. The easiest way is the one-point crossover, which is shown on the left hand side of gure 2.7. One crossover point is randomly selected (the 3th gene in the example), and the two descendants are created by interchanging the parents' genes after the crossover point. Similarly, dur- ing two-point crossover (right hand side of gure 2.7) two crossover point is randomly selected, and the genes of the parents are interchanged before and after the crossover points.
Mutation After crossover happened, during the mutation randomly chosen genes are selected and the operator changes their value into an other possible value. An example can be seen on gure 2.8. Mutation can prevent the algorithm from the convergence to a local extrema. Mutation as same as crossover largely depends on the encoding of the problem.
Genetic algorithms have further parameters, which could eects the e- ciency of the GA. Crossover probability determines how often the crossover occurs. If no crossover happens, descendants will be equivalent with their parents, otherwise the descendant will consist of the copy of the parents' ge- netic parts. If the crossover probability is 100%, every ospring will created by crossover, however if it is 0%, the new individuals will be the exact copy of the old population's members (note that it doesn't mean that the two population is equal). It is advisable to transmit the best individuals into the new population without any modication.
Mutation probability determines how often the mutation is used on the osprings. If no mutation happens, the ospring will be the result of the crossover, or of the copy. If mutation happens, some part of the chromosome will change, in case of 100%, every descendant will change, otherwise (0%) no modication will occur.
The population size denes the number of individuals in the population.
If it is too small, the algorithm couldn't cover the whole search space. When population size is too big, the GA will slow down.
2.2.3 A novel way to solve MTSP with GA
The proposed algorithm is based on a novel multi-chromosome representation of mTSP problem we presented recently [3]. This representation is similar to the representation used for vehicle scheduling in [158]. However, the crossover operators proposed by Tavares et al. do not produce feasible children, thus additional improvement steps have to be performed. In contrast, our op- erators always generate proper recombination, i.e. further correction is not necessary. Therefore, in the following a short description of the used repre- sentation will be presented, and the description of novel crossover operators will receive the main focus. The results and analysis of a novel GA-based algorithm is also presented in this section. The algorithm was developed in MATLAB, and the cooperation between the web-based framework and the optimization tool is straightforward and user-friendly.
The main motivation to use multi-chromosome genetic representations was the recognition, that although salesmen in mTSP are separated from each other "physically", almost every previous solutions of mTSP with GA has used a single chromosome to represent a whole solution, i.e. to represent each salesman like the one chromosome technique [173], the two chromosome technique [107, 122] or the most aective single-chromosome one so far, the so-called two-part chromosome technique [49]. A recent novel grouping GA is used a representation very close to multi-chromosome approach [149] and
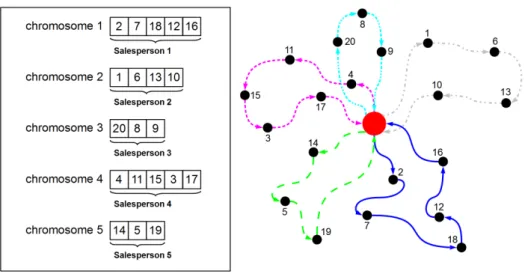
Figure 2.9. Example of the multi-chromosome representation for a 20 city mTSP (n= 20) with 5 salesperson (m= 5).
and Baghel proposes the best computational results so far, thus a comparison with our novel method will be discussed in the next section.
We can nd several works in the literature where the multi-chromosome approach is used to solve notoriously dicult problems decomposing into simpler subproblems. It was used in mixed integer problem [127] or in order problems [168]. A usage of routing problem optimization can be seen in [137]
and a lately solution of a symbolic regression problem in [50]. In Fig. 2.9, we represent how multi-chromosomal genetic programming can be used in the solution of mTSP with twenty cities (n = 20) and with ve salesmen (m= 5). Further discussion can be found in [158].
As we saw earlier, many examples can be found in the literature for genetic operators. Most of these operators can be derived from other operators, for example, a multi-chromosomal mutation can be constructed from a sequence of single-chromosomal mutations. The operators described below also can be created from other simple operators, but the new representation necessitates the introduction of new genetic operators also. There are two sets of mutation operators, the so-called In-route mutations and the Cross-route mutations.
Several operators have been implemented for the novel representation, but only an overview of them is given in this section.
The so-called in-route mutation operators work inside one chromosome, like the "Gene sequence inversion", which chooses a random subsection of a chromosome and inverts the order of the genes inside it or "Flip", which just
Figure 2.10. In-route mutations - "Gene sequence inversion" (upper part) and "Flip" (lower part)
Figure 2.11. Cross-route mutation - gene sequence transposition - "Swap"
swaps 2 randomly chosen genes inside a chromosome (see Fig. 2.10).
A cross-route mutation operator modies multiple chromosomes at once.
Note that using classical nomenclature and considering chromosomes as indi- viduals, this operator could be very similar to the regular crossover operator.
Fig. 2.11 illustrates the operator when randomly chosen sequences of genes from two chromosomes are transposed, i.e. the "Swap" operator. If one of the gene sequences contains zero genes, the operator is transformed into an interpolation. "Crossover" operator is also a cross-route mutation, which does a one-point crossover between two salespersons. Authors have applied a so-called "Local Optimization" operator, which is a simple TSP using ge- netic algorithm. This operator operates on each salesmen and optimizes their routes separately. The benets of this operator will be discussed in the next section.
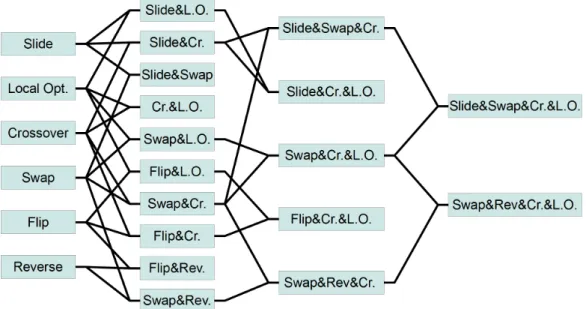
Combining simple operators like the ones in Fig. 2.11, we can create com- plex operators. Using these, the variability of the newly created individuals can be increased. Fig. 2.12 illustrates the method when two cross-route oper- ators are applied one after the other, composing a complex mutation. Firstly, a slide operator is applied, which moves the last gene from each chromosome to the beginning of another one; thereafter a gene sequence transposition or
Figure 2.12. Cross-route mutation - complex operator - Slide + Swap.
Swap is applied producing the new oset.
Using simple mutations to produce complex ones, a hierarchy of the op- erators can be constructed. Fig. 2.13 shows a tree, which represents the operators used for testing the novel representation and algorithm. Using these and other simple operators, much more complex ones can be gener- ated. An almost complete list of the used genetic operators can be found on our website1.
2.2.4 Numerical analysis of the proposed method
Using the multi-chromosome technique for the mTSP reduces the size of the overall search space of the problem. Let the length of the rst chromosome be k1, let the length of the second bek2 and so on. Of course Pm
i=1ki = n. Determining the genes of the rst chromosome is equal to the problem of obtaining an ordered subset of k1 element from a set of n elements. There are n!
(n−k1)! distinct assignment. This number is (n−k1)!
(n−k1−k2)! for the second chromosome, and so on. So the total search space of the problem can be formulated as equation (2.11).
n!
(n−k1)! ∗ (n−k1)!
((((((((
(n−k1−k2)!∗. . .∗((((((((((((
(n−k1−. . .−km−1)!
(n−k1−. . .−km)! = n!
(n−n)! =n!
(2.11) It is necessary to determine the length of each chromosome too. It can be represented as a positive vector of the lengths(k1, k2, . . . , km)that must sum ton. There are
n−1 m−1
distinct positive integer-valued vectors that satisfy this requirement [138]. Thus, the solution space of the new representation
1http://pr.mk.uni-pannon.hu/Research/eaai-mtsp/
Figure 2.13. The hierarchy of mutation operators. Each level indicates the number of simple operators used to produce the compound operator. The acronyms used in the gure are the following: L.O. - Local Opt. (i.e. Local Optimization); Cr. - Crossover; Rev. - Reverse; A & B - the combine operator, i.e. applying operator "B" after "A".
is n!
n−1 m−1
. It is equal with the solution space in [49], but this approach is more suitable to model an mTSP, so it is more problem-specic therefore more eective, as it will be proven in following sections.
To analyze the new representation, a GA using this multi-chromosomal technique was developed in MATLAB, and the new method was compared with the best known one-chromosome approach (the two-part chromosome technique). To make a fair comparison, we have developed two dierent algo- rithm, both of them are based on the implementation available on MATLAB Central2. The complete actual MATLAB code of the algorithms is available on our website.
The algorithms use two matrices as inputs, the set of coordinates of the locations (for visualization) and the distance matrix which contains the trav- elling distances between any two cities (in kilometers or in minutes). Of course, genetic parameters have to be specied also, like population size, number of iterations, or the constraints for the novel algorithm. As we men- tioned earlier in Sect. 2.2.4, the depot is not presented because of complexity
2
Figure 2.14. An example from the test set, with 100 locations.
reduction. First, the initial population is generated which consist of indi- viduals containing randomly permuted genes. The tness function simply computes the sum of overall route length (or duration) of each salesmen in- side an individual. The selection is tournament selection, where tournament size (i.e. the number of individuals who compete for survival) is 8. There- fore population size must be divisible by 8. The individual with the smallest tness value wins the tournament, thus it will be selected for generating new individuals, and this member will be transferred into the new population without any modication.
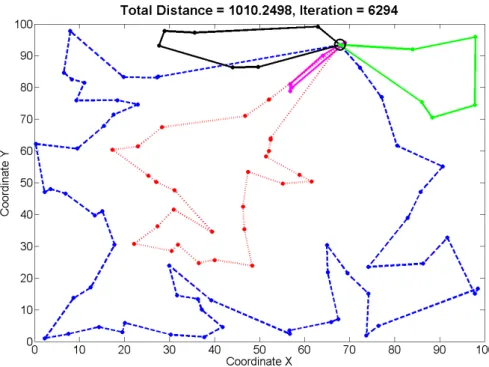
To analyze the eectiveness of the new representation, it was tested by several examples, only one is presented here in details. The example is a quite realistic problem, where the number of input locations is high enough;
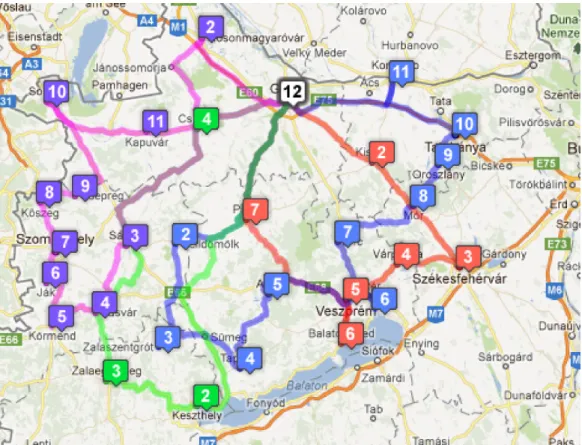
it contains 1 depot and 100 additional locations. The visualization of the problem with a possible result can be seen in Fig. 2.14.
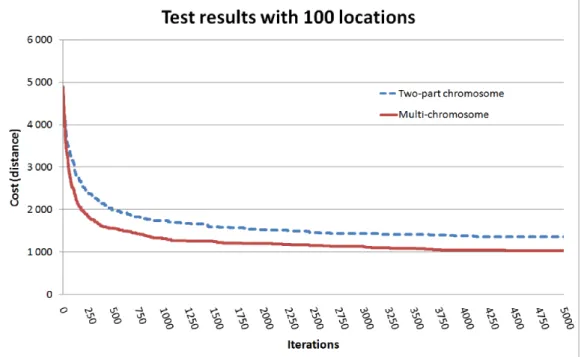
The results are presented in Fig. 2.15. The new representation was com- pared with the so-called two-part chromosome approach [49], which is the best technique to optimize mTSP using a single chromosome so far. It is ev- ident, that two dierent genetic algorithms can't be compared totally fairly, because the performance of these stochastic methods greatly depends on
Figure 2.15. Result of eciency analysis.
their parameters, thus it is impossible to nd a parameter set which results optimal performance for both algorithms. However, we aspired to make the representations fairly comparable, therefore 2 dierent algorithms were de- veloped, but both of them are based on the same MATLAB implementation, which is available on MATLAB Central. The two methods are almost the same, only the genetic representation and the applied operators are dierent.
In each case the population size was 80 and iteration number was 20000.
The gures below show an average result of 100 runs of the algorithm. Dur- ing a single run, the initial population of the two variety of the algorithm was the same. The gure shows unambiguously that the new approach pro- duces better results in these cases. The founded minimum is better in the multi-chromosome case, and this technique can converge to the optima faster.
In the example above (Fig. 2.15) multi-chromosome approach needed only 7411 iterations to nd the optimal value (996), while two-part chromosome technique required 18861 iterations. Execution times of the algorithms were almost equal, which is due to the equal complexity of the representations.
Thus, the representations can be comparable only in case of best objective function value per iteration. These test results conrm that the proposed representation is the most more eective for the solution of mTSP problems.
We tested the novel method with several randomly generated synthetic ex-
amples, varying the number of input locations, the population size and the number of iterations. Some of them are presented in Table 2.1. The results in the table present a fair comparison, while the algorithms were very simi- lar, both were implemented in MATLAB and run on the same machine. A nearly complete list of the test cases, and the algorithms are available on our website.
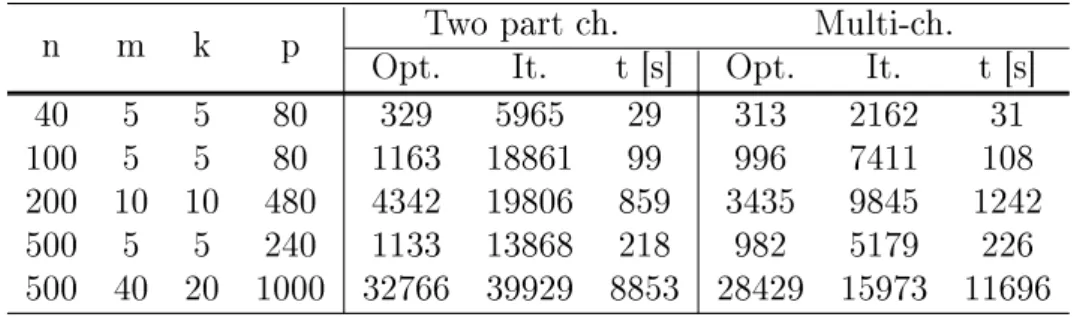
Table 2.1. Synthetic test results. Average of 100 runs. n: size of the problem, i.e. number of locations; m: number of salesmen; k: minimum tour length;
p: population size; Opt.: best found solution (overall distance); It.: iteration number when the best solution found; t: running time in seconds.
n m k p Two part ch. Multi-ch.
Opt. It. t [s] Opt. It. t [s]
40 5 5 80 329 5965 29 313 2162 31
100 5 5 80 1163 18861 99 996 7411 108
200 10 10 480 4342 19806 859 3435 9845 1242
500 5 5 240 1133 13868 218 982 5179 226
500 40 20 1000 32766 39929 8853 28429 15973 11696
Table 2.1 summarizes the results of our tests using synthetic data sets.
All the results presented during the paper were generated on a PC with a Core i5, 2.66 GHz processor with 3 GB of RAM. Table 2.1 shows clearly, that the novel approach can nd solutions with smaller overall distance, and it can nd this solution during fewer iterations. The time needed to nd the optima were almost identical, thus the novel approach can be considered more eective in these test cases.
Table 2.2. Test results using complex operators and initialization. Average of 100 runs. n: size of the problem, i.e. number of locations; m: number of salesmen; k: minimum tour length; p: population size; Opt.: best found so- lution (overall distance); It.: iteration number when the best solution found;
t: running time in seconds.
n m k p Multi-ch. & initialization Multi-ch. & complex ops.Opt. It. t [s] Opt. It. t [s]
40 5 5 80 314 1819 25 1000 2898 40
100 5 5 80 320 423 130 1150 1811 583
Table 2.2 represents the results of our tests using initialization on the ini-
tial population, and using complex mutation operators (see Sect. 2.2.3 and Fig. 2.12, Fig. 2.13). The initialization was done by a local optimization process, namely a TSP on each salesmen in every individual of the popula- tion. After initialization, the simple operators were used (see the 1st row).
Complex operators using Local opt. or L.O. in Fig. 2.13 apply the same method. Row 2 indicates the case when the optimization was done without the initialization step, using the complex operators (see the 3rd level of the operators' hierarchy in Fig. 2.13). Our tests highlight that the usage of initial local optimization can improve the process' accuracy and speed, while the application of complex operators results much stronger convergence, but it makes the approach slower, and the accuracy is slightly worse too. These result implies the necessity of initialization by local optimization (e.g. us- ing TSP solver) but indicates that we should be careful with the usage of too complex operators. However, because these operators can produce much higher variability in the population than simple ones, thus, they can produce better results in highly complex search spaces. Of course, the selection of proper operators may dier from problem to problem.
To analyze the performance and scalability of our method, further tests were performed using well-known test problems from TSPLIB [80] and the test data of Carter and Ragsdale [49] which were used in [44] and [149]. Since the programming languages and the running environments dier greatly, we disregard the presentation of running times in the following tables.
Table 2.3 represents the tests with ve instances of TSPLIB with increas- ing size, using 5 salesmen. Our results are compared to the Ant Colony Optimization algorithm which was proved to perform better than GAs in [88]. Results show unambiguously that our novel method performs better especially in huge problems.
Table 2.3. Test results using complex operators and initialization. Average of 10 runs. n: size of the problem, i.e. number of locations; m: number of salesmen; l: maximum tour length; Best: best found solution (overall distance); Avg: Average of 10 runs.
Problem n m l ACO Proposed
Best Avg Best Avg
pr76 76 5 20 178597 180690 158754 163424 pr152 152 5 40 130953 136341 135446 144244 pr226 226 5 50 167646 170877 160418 165966 pr299 299 5 70 82106 83845 81959 86284 pr439 439 5 100 161955 165035 135095 142214
Singh and Bagel in [149] proposed a very powerful grouping genetic algo- rithm for mTSP, namely GGA-SS. This method was analyzed using the data of Carter and Ragsdale [49] compared with their algorithm, GGA2PC (using two-part chromosome representation). Our performance tests are presented in table 2.4 using the same data as Singh and Bagel. Although GGA-SS performs better in most cases, our approach can nd better solutions using huge number of salesmen.
Table 2.4. Test results using complex operators and initialization. Average of 10 runs. n: size of the problem, i.e. number of locations; m: number of salesmen; Best: best found solution (overall distance); Avg: Average of 10 runs.
Instance GA2PC GGA-SS Proposed
num n m Avg Avg Avg Best
1 51 3 543 449 458 452
2 51 5 586 479 483 478
3 51 10 723 584 591 581
4 100 3 26,653 22,051 23,334 22,676 5 100 5 30,408 23,678 24,864 24,214 6 100 10 31,227 28,488 28,819 27,929 7 100 20 54,700 40,892 39,705 38,694 8 150 3 47,418 38,434 41,107 40,497 9 150 5 49,947 39,962 42,015 41,252 10 150 10 54,958 44,274 45,881 44,941 11 150 20 73,934 56,412 57,091 56,555 12 150 30 99,547 72,783 72,405 71,531
2.3 A Google Maps based framework developed to utilize the proposed algorithm
We will present a complete methodology in this section, which demonstrates a novel component-based framework using web technologies and MATLAB.
An application study will be presented in the next section which will guide the reader trough an industrial project from the denition of the problem to the visualization of results. The web-based framework presented in this section relies heavily on the Google Maps API, which is unique in the literature so far.Based on the novel genetic representation, we have developed a novel algorithm, which is capable to optimize the traditional mTSP problems, fur- thermore, it can handle the additional constraints and time windows (see Sect. 2.2.1). The algorithm can minimize the number of salesmen included in the solution also, considering their initial cost. In this section we passes over the presentation of source codes; the whole MATLAB implementation of the algorithm is accessible on our website. Note that the penalization of routes exceeding constraints is realized as a split using the chromosome partition operator [3] instead of the assignment of proportionally high tness value. Since the algorithm minimizes the number of salesmen involved, this penalty has a remarkable eect on the optimization process. Furthermore, the algorithm can handle the constraints for the routes and the time windows for the locations too, and we adjudge that the applied representation is more similar for the characteristic of the problem than the ones until now, thus it can be more easily understandable and realizable.
The problem itself which has motivated this research can be addressed as an mTSP problem, which should be solved by an automated system. A schematic owchart of such a system is represented in Fig. 2.16. The baseline should be a map (e.g. dened on Google Maps) and the distances between the locations can be calculated by a web based service like Google Maps.
Since in the real application, the amount of goods delivered is much less than the capacity of vehicles, the volume or mass constraints can be ignored (which denes the problem as mTSP instead of VRP). The result of the system has to be a route plan which can be dened on a web-based map or on a GPS Device. The calculation of cost, time and material ows are also necessary. we decided to use the free and publicly available Google Maps API, because it provides a fast and reliable web-service for dening user-friendly maps, computing traveling distances and time, and visualizing routes. Furthermore, it is the most used mapping service nowadays.
Based on Google's services, we have developed a complete and automated
Figure 2.16. The workow of the desired application
framework to provide an automated system like in Fig. 2.16. By the help of this program, users are capable of optimize an mTSP problem dened on a Google Maps map in a few minutes, and the result of the computation is visualized in a really easily interpretable way. A complete example will clarify these statements in the next section.
In Fig. 2.17 the component diagram of the proposed solution is illus- trated. First of all, a denition of input data (Map) is needed. This rst object on the gure represents the determination of locations on a Google Maps map. We have chosen the service of Google Maps, because it is one of the most common worldwide and it oers a reliable API. The second component (Coordinates Retrieval) provides a handy automatic tool for the retrieval of longitude and latitude values of the locations on the Map. Dis- tance Table component involves the computation of distances and duration between each pair of locations and uses the data determined by the previous component. The next step is the determination of optimal routes (Route Planning Algorithm) which is presented by the proposed GA discussed ear- lier. This component requires the distance table provided by the previous component and the parameters of the GA. Leaving aside the technical de- tails, it should be mentioned that the computation behind this component is done by the MATLAB Webserver running in background, which can get the parameters and send back the result over HTTP protocol. Thus, users can manage the optimization in their browser window. The last component (Visualiser) is a visualizer, which can show the resulted routes in an easily interpretable form on a Google Maps map, and computes the overall costs of routes using predened parameters, like per km cost or wage of the driver.
The presented method implements a novel approach in all stages, i.e. the coordinates retrieval from a Google Maps, the distance table calculation, the optimization and the visualization are all automated processes, which make