DOKTORI (PhD) ÉRTEKEZÉS
PACH FERENC PÉTER
Pannon Egyetem
Pannon Egyetem
Vegyészmérnöki és Folyamatmérnöki Intézet
Folyamatadatok szabálykeresésen alapuló elemzése
DOKTORI (PhD) ÉRTEKEZÉS
Pach Ferenc Péter
Konzulens
Dr. Abonyi János, egyetemi docens
Pannon Egyetem, Vegyészmérnöki Tudományok Doktori Iskola
Köszönetnyilvánítás
Köszönetet szeretnék mondani elsõsorban feleségemnek, Vikinek, hogy mindenben támogatott és mellettem állt, még akkor is, amikor már legszívesebben "leültem"
volna. "Felrázó" hatással voltak rám gyermekeim is, Zsófi és Dóri, akik - azon felül, hogy szeretetükkel sok erõt kaptam - jelenlétükkel (és szorgos tevékenységükkel) sok olyan dologra megtanítottak, amelyekben korábban elég gyengén teljesítet- tem (türelem, kitartás, idõ- és energia beosztás). Köszönetet szeretnék mondani szüleimnek, testvéreimnek is, akik nagyon sokszor, nagyon sok dologban segítettek az elmúlt három évben.
Köszönetet szeretnék mondani a Folyamatmérnöki Tanszék összes dolgozójá- nak, Dr. Szeifert Ferenc korábbi, illetve Dr. Abonyi János jelenlegi tanszékveze- tõnek, hogy lehetõséget biztosítottak a számomra, illetve, hogy segítettek, bármikor, bármilyen (technikai, adminisztrációs, oktatási, kutatási) problémával is fordultam hozzájuk. Külön köszönöm Jánosnak a rengeteg segítségét, javaslatát, tanácsát, tanításait, támogatását, illetve azt a sok idõt és energiát amit lelkes témavezetõmként rám fordított. Nagyon sokat tanulhattam Tõle, köszönöm. Köszönöm Dr. Németh Sándor VIKKK-en belüli témavezetését, támogatását, illetve tanácsait, a sok segít- ségét. Dr. Chován Tibornak nagyon hálás vagyok, hogy a nyári szünetébõl áldozott idõt a dolgozat (fõként nyelvtani) lektorálására, köszönet érte. Köszönöm Móricz Ágnes lektori segítségét is. Köszönet Dr. Gyenesei Attilának a rengeteg hasznos tanácsért, a sok segítségért.
A tanszék PhD hallgatóinak, Dr. Madár Jánosnak, Dr. Feil Balázsnak, Ba- laskó Balázsnak, Varga Tamásnak és Kenesei Tamásnak is köszönettel tartozom, hogy segítették munkámat, illetve hogy jó kollegáim voltak. Nekik és a szom- széd kutatómûhelybõl Gál Gábornak és Fekete Tamásnak is köszönöm a sok értékes eszmecserét.
Köszönöm a VIKKK támogatását és a TVK-PP4 üzem dolgozóinak segítségét.
Továbbá köszönetet szeretnék mondani Béres Zsuzsának, Bittmann Gábornénak a sok adminisztrációs segítségükért.
Contents
1 Introduction 10
1.1 Introduction to process data mining . . . 10
1.2 Soft Computing in data mining . . . 15
1.3 Fuzzy Rule-Based Systems . . . 17
1.4 Motivations, goals . . . 19
2 Process Data Warehousing for Complex Production Systems 22 2.1 Introduction . . . 22
2.2 Process data warehouse . . . 24
2.3 Exploratory Data Analysis (EDA) . . . 26
2.4 Discussion and conclusion . . . 29
3 Supervised Clustering Based Compact Decision Tree Induction 31 3.1 Introduction to pattern recognition . . . 31
3.2 Decision tree based classification . . . 34
3.3 Structure of classifiers . . . 37
3.3.1 Structure of decision tree based classifiers . . . 37
3.3.2 General structure of rule-based classifiers . . . 39
3.4 Supervised clustering based discretization . . . 40
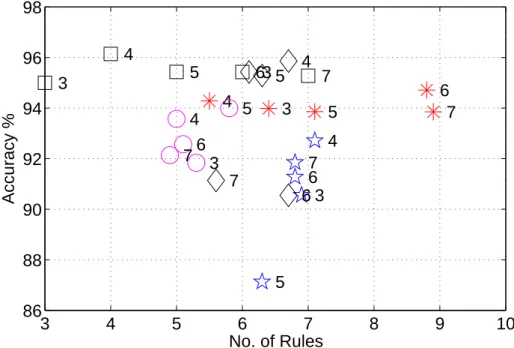
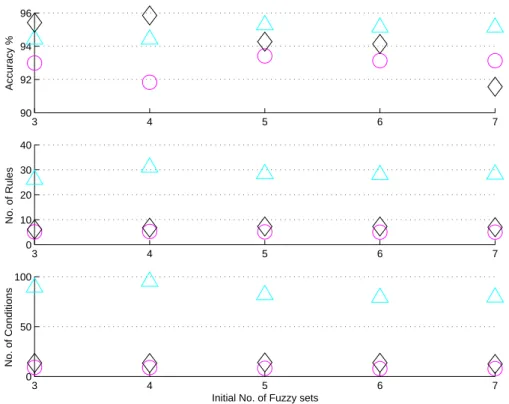
3.5 Experimental study . . . 44
3.5.1 Experimental methodology . . . 44
3.5.2 Wisconsin breast cancer problem . . . 44
3.5.3 Further examples . . . 50
3.5.4 Discussion . . . 52
3.6 Conclusion . . . 52 4 Fuzzy Association Rule Mining in Process Data 54
4.1.1 Related works . . . 57
4.1.2 Fuzzy association rule mining on classification data: basic definitions and notations . . . 60
4.1.3 The classification models . . . 62
4.1.4 CFARC: Compact Fuzzy Association Rule based Classifier . 65 4.1.5 Experimental results . . . 71
4.1.6 Conclusion . . . 76
4.2 Fuzzy Association Rule Mining for Model Structure Identification . 77 4.2.1 MOSSFARM - Model Structure Selection by Fuzzy Asso- ciation Rule Mining . . . 78
4.2.2 Experimental results . . . 79
4.2.3 Conclusions . . . 86
4.3 Visualization of Frequent Item Sets and Fuzzy Association Rules . . 87
4.3.1 Introduction . . . 87
4.3.2 Visualization of Fuzzy Association Rules . . . 88
4.3.3 Application Examples . . . 91
4.3.4 Conclusion . . . 96
4.4 Discussion and conclusion . . . 96
5 Data Warehousing and Mining for the Analysis of Polypropylene Pro- duction 97 5.1 Development of the process data warehouse . . . 99
5.1.1 Front-end applications . . . 103
5.2 Product classification based on process variables . . . 114
5.3 Feature and model structure selections . . . 117
5.4 Visualization of association rules . . . 120
5.5 Conclusion . . . 123
6 Summary 125 6.1 Conclusion . . . 125
6.2 Thesis . . . 126
6.3 Tézisek . . . 132
Kivonat
Folyamatadatok szabálykeresésen alapuló elemzése
Hatalmas mennyiségben állítunk elõ adatokat az élet minden területén nap, mint nap. Az adatok tárolásának, visszakereshetõségének megoldása nagy feladatot je- lent az informatikai szakembereknek, másrészt viszont érdemes figyelemmel kísérni a letárolt adatok felhasználást is. Becslések szerint a letárolt adatoknak csak kis hányadát használjuk fel valamilyen elemzésre, így jelentõs mértékben korlátozzuk az azokból kinyert információ mennyiségét. Ennek a pazarlásnak fõ okai a nagy méretû, nem megfelelõ struktúrájú (elemzéseket nem támogató) adatbázisokban, és a megfelelõ elemzõ eszközök hiányában keresendõ.
A korszerû vegyipari gyártástechnológiák magas fokú automatizáltságának kö- szönhetõen, a gyártás során nagy mennyiségben tárolhatunk le technológiai ada- tokat. A folyamatadatokban rejlõ információkat csak hatékony adatelemzési mód- szerekkel tudjuk feltárni. Az adatok elemzésénél azonban problémát jelent, hogy azok elérhetõsége idõben (3-4 hónapra) korlátozott, továbbá gondot okoz a lehet- séges információforrások heterogenitása (információ típusa, adattárolás módja, esz- köze, tartalom) is.
A probléma megoldásához a dolgozat egy a vegyipari folyamatadatok elemzését lehetõvé tevõ, költséghatékony folyamat adattárház kiépítési módszert ismertet. Az új módszer alkalmazásával a hisztorikus adatelemzést, illetve a folyamat moni- torozást is támogató információs rendszereket lehet kialakítani komplex, többter- mékes (polimerizációs) technológiák esetében.
Az információs rendszerekhez kapcsolódó új adatelemzõ módszerek és eszközök (statisztikák, adatbányászati algoritmusok, modellek) közös tulajdonsága, hogy a folyamat adatokból áttekinthetõ szabályok formájában nyerhetõk ki hasznos infor- mációk a gyártásokra, termékekre vonatkozóan.
Abstract
Rule-based knowledge discovery for process data mining
In modern chemical production systems large amount of technological data can be stored during the productions. However there are problems in the analysis of these process data, namely the access to data is limited in time and information sources have heterogeneities. The thesis introduces a new process data warehouse building method which can be the basis of an information system that supports historical data analysis or process-monitoring in case of multi-product (polymerization) tech- nologies. In relation to the information system new data analysis methods and tools (statistics, data mining algorithms, models) are also developed. The main feature of these methods that the discovered relationships about the productions or products are represented by interpretable rules. The new methods can be applied not only for process data but also to more general problems.
Auszug
Die Analyse der, auf die Regelforschung beruhende Prozessdaten
Dem hohen Grade der Automatisation zeitgenössischen chemischen Technologien Danke, können wir technologische Daten beim Betriebsvorgang im hohen Anzahl abspeichern. Bei der Analyse der Prozessdaten bedeuten die zeitlich begrenzte Zugänglichkeit der Daten, und die Heterogenität der wahrscheinlichen Information- squellen das grösste Problem. Die These legt eine neue Methode für den Prozess der Ausbau einer Datenwarehouse dar. Diese Methode hilft mit der Entwicklung solcher Informationssysteme die die geschichtlichen Datenanalysen und Prozess Monitoring der komplexen, mehrproduktlichen Technologien unterstützen. Die neuen datenanalysierende Methoden und Mitteln (Statistiken, Datamining Algo- rythmen, Modellen) vervandt mit den Informationssystemen haben gemeine Eigen- schaften. Das bedeutet, dass von den Prozessdaten, im Form von übersichtlichen Normen, nützliche Informationen aufgedeckt werden können. Die erarbeiteten Meth- oden können für industrielle, sowie auch allgemaine Datenanalyse Zielen benutzt werden.
Chapter 1 Introduction
1.1 Introduction to process data mining
In modern production systems, technological databases store huge amount of pro- duction data. Such technological data is collected and generated by automatic log- ging and the operating personnel. It consists of many information about the normal and abnormal operations, significant changes in operational and control strategies.
Therefore, technological databases are potentially useful information sources for operators and engineers in the process monitoring and performance analysis.
Traditional analyzes of technological databases involve human experts who man- ually analyze the data, or specially coded applications that search for patterns of in- terest. Traditional database management systems (DBMS, e.g. MS ACCESS) and analyzer tools (EXCEL) could help in process monitoring and analysis, but the most of them are inefficient where data come from a distributed, heterogeneous and com- plex system (such as a chemical production factory). Beside the structure and data sources, the characteristics of process operational data are also must be considered.
Typical characteristics are the followings:
• Large volume of data
• High dimensionality
• Process uncertainty and noise
• Dynamics
• Difference in sampling time of variables
• Incomplete data
Uniform data structure
(laboratory, automatic measurements)
Process monitoring
(long time horizon - years) Quality management
Comparisons
(products, parameters)
Discovering relationships
Documentations
(automatic reports)
Front-end tools Data mining
Technology development
Figure 1.1: Facilities in the analysis of a production process
• Small and stale data
• Complex interactions between process variables
• Redundant measurements.
As the volume and complexity of process data continue to grow, general approaches are no longer adequate. New data integration techniques and analyzer tools are needed to satisfy all these demands.
In [105] a literature survey is presented on intelligent systems for monitoring, control, and diagnosis of process systems. Fig. 1.1 shows a new framework to dis- cover and use information related to a technological process. The key of the method is a data pre-processing step where an uniform data structure is proposed in consid- eration of heterogeneous data sources (laboratory data, automatic measurements, parameters, technological boundaries, etc.). Based on that, process monitoring, documentation and comparison of productions (over a long time horizon) can be the main functions of the analyzer front-end tools. Moreover, data mining algo- rithms can be also applied to discover relationships between variables, events and productions. This can support the technology development and quality manage- ment. [18] demonstrated that data mining can provide a powerful tool for process
Data
Target data
Preprocessed data
Transformed data
Patterns Selection
Preprocessing
Transformation
Data mining
Interpretation
Knowledge
Figure 1.2: The Knowledge Discovery in Databases (KDD) process
Knowledge discovery in databases
Data mining, sometimes known as Knowledge Discovery in Databases (KDD), gives users tools to sift through vast data stores to learn and recognize patterns, make classifications, verify hypotheses, and detect anomalies. These findings can highlight previously undetected correlations, influence strategic decision-making, and identify new hypotheses that warrant further investigation. A typical KDD process involves several steps that take the user along the path from data source to knowledge (Fig. 1.2). KDD is an iterative process where each of the steps may be repeated several times:
• Data selection, preprocessing and transformation activities compose what is often referred to as the data preparation step.
• The next step, data mining is the extraction of interesting (non-trivial, im- plicit, previously unknown and potentially useful) information or patterns from data in large databases. It is an information processing method that gives answers for the questions which we can not even consider or define precisely.
Frequently, data mining is the most emphasized step of KDD, but for a successful discovery project all the steps have large significance, because the selection and preparation of data has a decisive influence on the set of discoverable and adequate knowledge. The effort for the various steps is illustrated in Fig. 1.3.
The results of a successful KDD activity include not only the identification of structural patterns in data (recognition), but also descriptions of the patterns (learn-
Objectives Data preparation Data mining Interpretation 0
10 20 30 40 50 60
Effort [%]
Figure 1.3: Required effort for the main steps of KDD process Value
Decisions Knowledge Information
Data
Technological knowledge +
Volume
Figure 1.4: From volume to value
ing) that can impart knowledge, not just yield predictions [109]. The integration of the obtainable knowledge during a KDD process and the technological knowl- edge could help in decision situations (Fig. 1.4) to solve problems and improve the performance of the production. Different kinds of decision making activities are represented in Fig. 1.5 [98]. Data mining models and methods could help decisions, primarily in levels of strategic, logistics-planning and supervisory control.
DM tools can be categorized in different ways. According to functions and application purposes a possible categorization is represented in Fig. 1.6. The most frequently used techniques are summarized in the followings:
• Classification: learning a function that maps (classifies) a data item into one of several predefined classes.
Levels of decision making Scope of application
Strategic Decisions
Logistics & planning Supervisory control
Regulatory control
Plant
Overall plant Plant departments
Plant area Operating unit
Single loop Sensors Seconds/minutes
Seconds/minutes Days/week Hours/shifts Week/month
Year
Figure 1.5: Levels, time scales, and application scopes of decision making activities
Predictive Modeling
- Classification - Value prediction
Database Segmentation
- Demographic clustering - Neural clustering
Link Analysis
- Associations discovery - Sequential pattern discovery - Similar time sequence discovery
Deviation Detection
- Visualization - Statistics
Figure 1.6: Data mining models and methods
diction variable and the discovery of functional relationships between vari- ables.
• Clustering: identifying a finite set of categories or clusters to describe the data. Closely related to clustering is the method of probability density es- timation which consists of techniques for estimating the joint multivariate probability density function of all of the variables/fields in the database.
• Summarization: finding a compact description of a subset of data, e.g. the derivation of summary or association rules and the use of multivariate visual- ization techniques.
• Dependency Modeling: finding a model which describes significant depen- dencies between variables (eg. learning of belief networks)
• Change and Deviation Detection: discovering the most significant changes in the data from previously measured or normative values.
KDD process can serve as an efficient technique to the analyze and represent of real-time and historical process data in order to get deeper insight into the behav- ior of complex systems. One of the main requirements of a successful and useful knowledge integration step is that the discovered knowledge must be well inter- pretable for users. Soft computing systems help knowledge discovering processes to get interpretable results. In the following, the basics of soft computing systems are introduced according to [22].
1.2 Soft Computing in data mining
What is Soft Computing?
Physical systems, described by multiple variable and multiple parameter models having non-linear coupling, frequently occur in the fields of physics, engineering, technical applications, economy, etc. The conventional approaches based on analyt- ical techniques for understanding and predicting the behavior of such systems can be very difficult, even at the initial stages of establishing an appropriate mathemat- ical model. The computational environment used in such an analytical approach is perhaps too categoric and inflexible to cope with the intricacy and the complexity of the real physical systems. It turns out that in dealing with such systems, one has to face a high degree of uncertainty and tolerate imprecision. Trying to increase precision can be very costly [50].
Soft computing differs from conventional (hard) computing, because it is tolerant to imprecision, uncertainty and partial truth. In effect, the role model for soft com- puting is the human mind. The guiding principle of soft computing is: exploit the tolerance for imprecision, uncertainty and partial truth to achieve tractability, ro- bustness and low solution cost. At this juncture, the principal constituents of soft computing (SC) are fuzzy logic (FL), neural network theory (NN) and probabilis- tic reasoning (PR), with the latter subsuming belief networks, genetic algorithms, chaos theory and parts of learning theory. What is important to note is that SC is not a melange of FL, NN and PR. Rather, it is a partnership in which each of the
In this perspective, the principal contributions of FL, NN and PR are complemen- tary rather than competitive (definition adapted from Prof. Lotfi A. Zadeh).
The basic ideas underlying soft computing in its current incarnation have links to many earlier influences, among them Zadeh’s 1965 paper on fuzzy sets [118]; the 1973 paper on the analysis of complex systems and decision processes [119]; and the 1979 report (1981 paper) on possibility theory and soft data analysis [120]. The inclusion of neural computing and genetic computing in soft computing came at a later point.
The strengths of main constituents of SC are the following:
• Fuzzy logic - knowledge representation by interpretable IF...THEN rules
• Neural network - skill of learning and adaptation
• Probabilistic reasoning - aid for decision making under uncertainty
The "integration" of constituents provides complementary reasoning and search- ing methods that allow us to combine domain knowledge and empirical data to de- velop flexible computing tools and solve complex problems. The logical IF...THEN rule structure is a good selection to store and represent knowledge, because reason- ing with rules is more comprehensible to humans (for example, "if temperature is high, then pressure is high", or "if density of slurry is high and reactor temperature is high then quality of product is good").
Various types of logical rules can be discussed in the context of the decision borders these rules create in multidimensional feature space. Standard crisp propo- sitional IF...THEN rules provides overlapping hyper rectangular covering areas, threshold logic rules are equivalent to separating hyper planes, while fuzzy rules based on real-valued predicate functions (membership functions, see later) provide more complex decision borders [33].
This thesis is focused on the extraction and the use of fuzzy rules as fuzzy rule- based systems for process data analyzes. The following section introduces the ba- sics of fuzzy logic and the main type of possible fuzzy rule based systems (FRBS) based on [22].
1
190 Height [cm]
150 160 170 180 200
Membership
A
Figure 1.7: Crisp (line) vs. fuzzy (dashed line) sets
1.3 Fuzzy Rule-Based Systems
Basics of fuzzy set theory
Conventional set theory is based on the premise that an element either belongs to or does not belong to a given set. Contrarily, fuzzy set theory allows elements to have degrees of membership of a particular set. For example, consider that one de- termines the set of tall people (Fig. 1.7). In conventional set theory where a distinct range of height are designated such as 190 cm and over as belonging to the set tall (represented by set A in Fig. 1.7). In such cases the set A is a crisp set. In fuzzy set theory, a fuzzy set is a set with fuzzy boundaries, or with formal definition: a fuzzy set A in X is expressed as a set of ordered pairs: A = {(x, µA(x))|x ∈ X}, whereµAis a membership function andXis the universe of discourse. A fuzzy set is totally characterized by a membership function, because membership function describes the relationship between a variable and the degree of memberships (for example the fuzzy set A in Fig. 1.7). This degree of membership is usually defined in terms of a number between 0 and 1.
A numerical variable takes numerical values, for example: Height = 187. A linguistic variable takes linguistic values, for example: Height is tall. A linguistic value is a fuzzy set. Linguistic values form a term set: T(Height) = {small, very small, not small, tall, very tall, not tall, etc.}.
Linguistic Fuzzy Rule-Based Systems
lowing structure:
If X1 IsA1And . . . AndXnIsAnThen (1.1) Y1 IsB1 And . . . AndYmIsBm
withXiandYj being input and output linguistic variables respectively, and withAi andBj being linguistic labels of the corresponding fuzzy sets defining their mean- ing. These linguistic labels will be taken from a global semantic defining the set of possible fuzzy sets used for each variable (example: triangular membership func- tions). This structure provides a natural framework to include expert knowledge in the form of fuzzy rules. In these systems, the knowledge base (KB) - the compo- nent of the FRBS that stores the knowledge about the problem being solved - is composed of:
• the rule base (RB), constituted by the collection of linguistic rules themselves joined by means of the connective also, and
• the data base (DB), containing the term sets and the membership functions defining their semantics.
Takagi-Sugeno-Kang-type (TSK) FRBS
While linguistic rules consider a linguistic variable in the consequent, TSK-type fuzzy rules are based on representing the output variables as polynomial functions of the input variables, i.e.,
If X1 IsA1 And . . . AndXnIsAnThen (1.2) Y1 Isp1(X1, . . . , Xn)And . . . AndYm Ispm(X1, . . . , Xn)
withpj(·)being the polynomial function defined for the jth output variable. Using this fuzzy rule structure, the human interpretation on the action suggested by each rule is garbled, but on the other side, the approximation capability is significantly increased. For this reason, TSK-type FRBSs are very useful in precise fuzzy mod- eling (PFM).
Other Kinds of FRBSs
• The Singleton FRBS: where the consequent takes a single real-valued number, can be considered as a particular case of the linguistic FRBS (the consequent is a fuzzy set where the membership function is one for a specific value and zero for the remaining ones) or of the TSK-type FRBS (the polynomial func- tion of the consequent is a constant). Since the single consequent seems to be more easily interpretable than a polynomial function, the singleton FRBS can be used to develop linguistic fuzzy models (LFM).
• The fuzzy rule-based classification system, which is an automatic classifi- cation system that uses fuzzy rules as knowledge representation tool. The classical fuzzy classification rule structure is the one that has a class label in the consequent part instead of the considered fuzzy set. Other alternative representations that consider a certainty degree for each rule or that include all the possible class labels with their corresponding certainty degrees in the consequent part are usually also considered.
• The approximate FRBS differs from the linguistic one in the direct use of fuzzy variable. Each fuzzy rule thus presents its own semantic, i.e., the vari- ables take different fuzzy sets as values and not linguistic terms from a global term set. The fuzzy rule structure is then as follows:
If X1 IsAb1And . . . AndXnIsAbnThen (1.3) Y1 IsBb1 And . . . AndYmIsBbm
with Abi and Bbj being fuzzy sets. Since no global semantic is used in ap- proximate FRBSs, these fuzzy sets can not be interpreted. This more flexible structure allows the model to be more accurate, being very appropriate to develop PFM.
1.4 Motivations, goals
The formulated products (e.g. plastics, polymer composites) are generally produced from many ingredients. The large number of interactions between components and processing conditions all have the effect on final product quality. This feature of the complex production systems defines an important motivation factor to develop
Operators SP’s
SP’s PV’s
Production process
Distributed Control
System OP’s
PV’s PV’s Graphical User Interface
SP’s
Process Computer
SP’s Calculated
PV’s
PROCESS DATA WAREHOUSE Statistical tools
Data mining tools
Model of process control Analytical level
Operating level
I.
IV.
II.
III.
Figure 1.8: Scheme of process analysis methodology
formalized in fuzzy rule base system (FRBS) which could support the monitoring and analysis work of operators or engineers. To the efficient process analysis an ap- propriate methodology is also necessary beside the analysis tools. Fig. 1.8 presents the scheme of the designed process analysis methodology, the interface between operation and knowledge discovery levels.
At operation level, the distributed control system (DCS) assures locally the se- cure and safety operation of the technology. The measurements serve the values of the process variables (PV’s) to DCS which forwards the information to the graphi- cal user interface (GUI). The operators of the technology can get information about the system via the GUI and (if it is necessary) they control the process by changing the set points (SP’s). An advanced model based process control (Process Com- puter) computer calculates among others the operation set points (OP’s) for the DCS. Moreover, it calculates many special PV’s which provide more information about the production. Most of the DCS have functions for data storing. These data definitely have the potential to provide information for product and process design, monitoring and control, but the access to data is limited in time on the process con- trol computers, since they are archived retrospective for about 1-2 months.
If we want to store technology data for longer time interval, it is expedient to store data in a database, or especially in a process data warehouse (DW). Process DW is a data analysis-decision supporting and information processing unit, which
is operated separately from the databases of the DCS. It is an information environ- ment in contrast to the data transfer-oriented environment, which contains trusted, processed and collected data (see the characteristic of process data) for historic ana- lyzes. Therefore, it makes possible to get relevant information from the technology.
Consequently, the two main goals of this thesis are the followings:
1. Develop a general, easy to use, but efficient process analysis methodology for (polymerization) production technologies based on data warehousing. The methodology should be applicable for different (polymerization) technolo- gies.
2. Develop new data mining tools to discover important relationships (repre- sented by fuzzy rules) in data of productions. The new algorithms have to be applied not only for process data but also to more general problems.
Structure of the thesis
In accordance with the main goals, the thesis is structured into three main parts.
• In the first part, a process data warehouse building mechanism is introduced (Chapter 2). It is based on the data handling steps (selection, preprocess- ing, transformation) of the knowledge discovery process (Fig. 1.2) and the resulted process data warehouse could be the main data source for analysis by descriptive statistics and various data mining tools (Fig. 1.8).
• The second part of my thesis discusses two new data mining tools. First, a new fuzzy decision tree based classification method is introduced (Chapter 3), then a fuzzy association rule mining technique is presented (Chapter 4). This technique is applied to develop three new methods, namely a fuzzy associative classification (Section 4.1), a model structure selection(Section 4.2) and a rule base visualization (Section 4.3) algorithms.
• The developed tools are applied for several benchmark and real-world prob- lems from data mining and chemical engineering literature, moreover in the third main part of the thesis an industrial application study is also showed (Chapter 5).
Chapter 2
Process Data Warehousing for Complex Production Systems
2.1 Introduction
Process manufacturing is increasingly being driven by market forces, customer needs and perceptions, resulting in more and more complex multi-product manu- facturing technologies. It is globally accepted that information is a very powerful asset that can provide significant benefits and a competitive advantage to any or- ganization, including complex production technologies. The complex production processes consist of several physically distributed production units and these units represent heterogenous information sources (e.g. real-time process data, product quality data, financial data, etc.). Therefore, for the effective operation and im- provement of complex technological systems an integrated information system (in- cluding advanced process automation and operator support systems) is essential.
Such information system must be able to handle heterogeneities in terms of:
• Type of information, like:
– Prior knowledge arising from natural sciences and engineering - formu- lated by mathematical equations, or data
– Heuristical, empirical knowledge expressed by linguistical rules, stored and handled by expert systems,
– Sampled and calculated process data;
• Data format:
– Manually logged data (reports reside in many different file and database structures developed by different vendors),
– Databases in different platforms and formats, including the historical databases of distributed process control system (DCS);
• Content:
– Product features - measured in laboratory, – Process features - measured by the DCS.
The complex organizations have vast amounts of such heterogenous data and it is difficult to access and use them. Thus, large organizations have had to write and maintain perhaps hundreds of programs that are used to extract, prepare, and consolidate data for use by many different applications for analysis and reporting.
Also, decision makers often want to dig deeper into the data once initial findings are made. This would typically require more intensive and effective integration of the information sources.
Several works deal with the problem of heterogeneous data(base) integration. In [124] Zhao discussed the problem of detecting semantically corresponding records from heterogeneous data sources, because it can be a critical step in integrating the data sources. Many researches focus on how data structured in different ways can be handled. Considering databases, XML files, other structured text files or web services as information supplier, the complexity of integrating the informa- tion with their various describing models is not easy to handle. Different solution methods have been worked out (e.g. in [27, 108]). In [14] a new object-oriented lan- guage, with an underlying description logic, was introduced for information extrac- tion from both structured and semi-structured data sources based on tool-supported techniques. [81] presented a framework for the comparison of systems, which can exploit knowledge based techniques to assist with information integration. Integra- tion of heterogeneous data sources is also related to knowledge discovery and data mining, see e.g. [41, 93].
Beside the database integration within a particular production unit, there is a need for information integration in the level of the whole enterprize for the pur- pose of optimal operation. This task cannot be fully automated, there is a need for permanently improved methods and approaches for creation, storage and dissemi-
Since this solution cannot be fully automated, it is costly, inefficient, and very time consuming.
The aim of this chapter is to illustrate that data warehousing offers a better ap- proach. Data warehousing implements the process to access heterogeneous data sources: clean, filter, transform and store the data in a structure that is easy to ac- cess, understand, and use. The data is then used for query, reporting, and data analysis to extract relevant information about the current state of the production, and support decision making process related to the control and optimization of the operating technology.
The basics of process data warehousing are detailed in the next section (Sec- tion 2.2) and an introduction to exploratory data analysis (EDA) is given in Sec- tion 2.3. A case study is presented at the end of the thesis (Chapter 5), where the full development process of an information system for multi-product technology analysis in a polypropylene plant is detailed. The central element of the developed information system is a process data warehouse. It can be used not only for gen- erating report and executing queries, but it supports the analysis of historical data, process monitoring and data mining, knowledge discovery too. Before the applica- tion study is showed some new data mining methods and algorithms are presented in Chapters 3-4.
2.2 Process data warehouse
In modern industrial technologies the application of a distributed control system (DCS) is a basic requirement. This system is responsible for the safe operation of the technology at the local level. At the coordination level of the DCS many com- plex tasks are handled, like controller tuning, process optimization, model identifi- cation and error diagnostic. These tasks are based on process models.
As new products are required to be introduced to the market over a short time period to ensure competitive advantage, the development of process models ne- cessitates the use of empirical model based techniques rather than first-principles models, since phenomenological model development is un-realizable in the time available [60]. Hence, the mountains of data that computer-controlled plants gen- erate, must be effectively used. For this purpose most of the DCSs are able to store operational process data. However, DCS has limited storage capacity because this is not it’s main function, only data logged in the last one or two months are stored in these computers. Since data measured in a longer time period have to be used for
DCS relational database Process Data Warehouse Function day to day data storage decision supporting Data actual, daily, detailed, in-
cluded in relation, isolated
historical, summarized, in- tegrated, consolidated
Using iterative ad-hoc
Unit of work short, general transactions complex queries
User operator engineer, operator, plant
manager
Design application oriented subject oriented
Access read-write many queries
Number of accessed records
decimal order million order
Size 100 MB-GB 100 GB-TB
Degree transactional time inquiry time
Region process unit whole production line
Table 2.1: The main differences between the DCS relational database and the Process Data Warehouse.
sophisticated process analysis, quality control, and model building, it is expedient to store data in a historical database that is useful to query, group and analyze the data related to the production of different products and different grade transitions. Today several software products in the market provide the capability of integration of his- torical process data of DCS’s: e.g. Intellution I-historian [21], Siemens SIMATIC [94], the PlantWeb system of Fisher-Rosemount [36] and the Wonderware Factory- Suite 2000 MMI software package [8].
In this study a new information system is showed where a data warehouse con- tains only consistent, non-violate, pre-processed, historical data [49], and it is work- ing independently from the DCS. This type of data warehouse has the features pre- sented in Table 2.1, and it is called as Process Data Warehouse. The fact that the integration of historical process data taken from various production units requires data warehousing functions has been already realized by the developers of modern DCSs (e.g. Honeywell PHD module or the i-Historian module of Intellution).
The process data warehouse can be the basis of a technology support infor- mation system that provides relevant information for the engineers about the pro- duction process. Considering the application scopes of decision making activities (Fig. 1.5), two main types of possible information systems can be distinguished:
ator Support System (OSS) based on data warehouse utilizing of enterprize and process modeling tools is presented. For human-computer interaction, front-end tools have been worked out that support the dynamic monitoring of the process and prediction of product quality (primarily for the operators of the plant).
• Information system for historical data analysis. The integration of het- erogeneous historical data taken from the various production units into a DW with focus on the specialities of the technology serves information sources for decision makers (engineers, plant manager). Considering the process analysis scheme presented in Fig. 1.8, the DW is the central element of the informa- tion system. It makes possible the exploratory analysis and data mining of process data, moreover helps the identification of first principle models of the technology (and control system).
The theses focuses only the second type of information systems, namely informa- tion system for historical data analysis. While basics of data mining (and KDD) have been already discussed in Section 1.1, the following section introduces the exploratory data analysis.
2.3 Exploratory Data Analysis (EDA)
Process monitoring based on multivariate statistical analysis of process data has re- cently been investigated by a number of researchers [67, 106, 20, 105]. The aim of these approaches is to reduce the dimensionality of the correlated process data by projecting them onto a lower dimensional latent variable space where the op- eration can be easily visualized. These approaches use the techniques of principal component analysis (PCA) or projection to latent structure (PLS). Beside process performance monitoring, these tools can be used for system identification [67], en- suring consistent production [69] and product design [59]. For these classical data analysis approaches, the collection of the data is followed by the construction of a model and the analysis, estimation, and testing focused on the parameters of the model.
Pearson suggested using Exploratory Data Analysis (EDA) tools for both of these reasons [82]. For EDA, the data collection is not followed by a model con- struction, it is rather followed immediately by analysis with a goal of inferring what model would be appropriate. EDA is an approach/philosophy for data analysis that
employs a variety of techniques (mostly graphical) to maximize insight into a data set, uncover underlying structure, extract important variables, detect outliers and anomalies, test underlying assumptions, develop parsimonious models, and deter- mine optimal factor settings. The seminal work in EDA is written by Tukey [103].
Over the years it has benefited from other noteworthy publications such as Data Analysis and Regression by Mosteller and Tukey [75], and the book of Velleman and Hoaglin [104].
Most EDA techniques are graphical in nature with a few quantitative techniques [74]. The reason for the heavy reliance on graphics is that by its very nature the main role of EDA is to open-mindedly explore, and graphics gives the analysts unparalleled power to do so, enticing the data to reveal its structural secrets, and being always ready to gain some new, often unsuspected, insight into the data. In combination with the natural pattern-recognition capabilities that we all possess, graphics provides, of course, unparalleled power to carry this out. The particular graphical techniques employed in EDA are often quite simple, consisting of various techniques of:
1. Plotting the raw data (such as data traces and histograms).
2. Plotting simple statistics (such as mean plots, standard deviation plots and box plots).
3. Positioning such plots so as to maximize our natural pattern-recognition abil- ities (such as using multiple plots per page).
The key step for any process data analysis method is to collect all available (het- erogenic) data and technology information (a priori knowledge) and integrate them into a process data warehouse. To analyze the enormous amount of data, trends, ex- ploratory data analysis (box plots, quantile-quantile plots, etc.) and data mining al- gorithms (association rule mining, clustering, classification, etc.) can be applied to get relevant information about the technology. A detail application study is showed in Chapter 5, now let’s see the basics of box-plots.
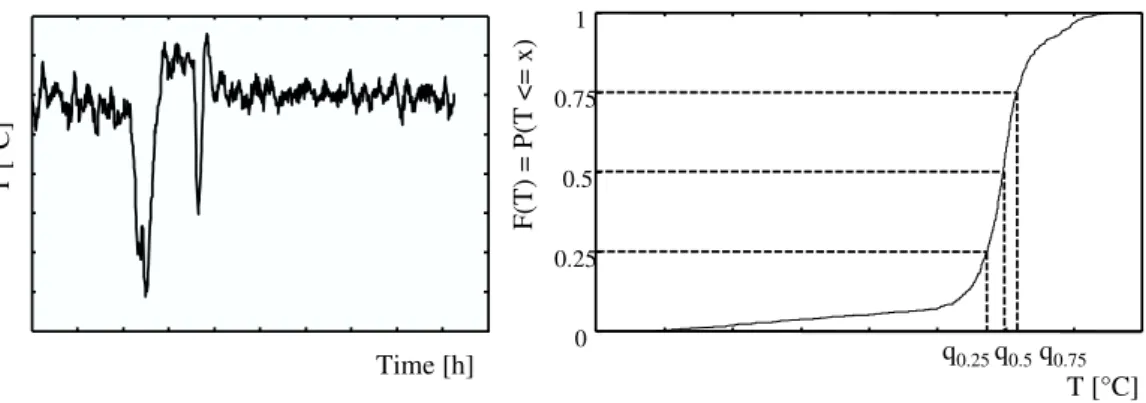
Suppose that X is a real-valued variable (e.g. the reactor temperature - T) and the analysis of process and product quality variables is considered. Hence, the variables are X ∈ {zk,yk}. An example of the behavior of a process variable (reactor temperature) is given in Fig. 2.1. The (cumulative) distribution function of
T [°C]
Time [h]
0 0.25
0.5 0.75 1
T [°C]
F(T) = P(T <= x)
q0.25q0.5q0.75
Figure 2.1: Example of the change of a process variable reactor temperature (T, left) and it’s cumulated distribution function, the q0.25, q0.5 and q0.75 quintile are also depicted (right)
x. For a discrete random variable, the cumulative distribution function is found by summing up the probabilities. For a continuous random variable, the cumulative distribution function is the integral of its probability density function (Fig. 2.1 on the right). Suppose thatp∈ [0,1]. A value of x such thatF(x) = P(X < x) ≤ p and F(x) = P(X ≤ x) ≥ p is called a quantile of order p for the distribution.
Roughly speaking, a quantile of orderpis a value where the cumulative distribution crossesp. Hence, by a quantile, we mean the fraction (or percent) of points below the given value. That is, the 0.25 (or 25 %) quantile is the point at which 25 % percent of the data fall below and 75 % fall above that value. Note that there is an inverse relation of sorts between the quantiles and the cumulative distribution values. A quantile of order 1/2 is called a median of the distribution. When there is only one median, it is frequently used as a measure of the center of the distribution.
A quantile of order 1/4 is called a first quartile and the quantile of order 3/4 is called a third quartile. A median is a second quartile. Assuming uniqueness, letq0.25,q0.5, andq0.75denote the first (lower), second, and third (upper) quartiles of X.
Note that the interval fromq0.25toq0.75gives the middle half of the distribution, and thus the interquartile range is defined to be IQR =q0.75-q0.25, and is sometimes used as a measure of the variance of the distribution with respect to the median. Let q0 and q1 denote the minimum and maximum values of X, respectively (assuming that these are finite). The five parametersq0, q0.25, q0.5, q0.75, q1 are often referred to as the five-number summary. Together, these parameters give a great deal of information about the distribution in terms of the center, spread, and skewness.
Tukey’s five number summary is often displayed as a box plot. Box plots are
69.8 69.85 69.9 69.95 70 70.05 70.1 70.15 70.2
°C
Figure 2.2: Single box-plot of a variable (e.g. reactor temperature)
excellent tools for conveying location and variation information in data sets, partic- ularly for detecting and illustrating location and variation changes between different groups of data [74]. An example for box plot is presented in Fig. 2.2. The box plot consists of a line extending from the minimum valueq0 to the maximum value q1, with a rectangular box fromq0.25toq0.75, and tick marks at the medianq0.5. Hence, the lower and upper lines of the "box" are the 25th and 75th percentiles of the sam- ple. The distance between the top and bottom of the box is the interquartile range.
The line in the middle of the box is the sample median. If the median is not cen- tered in the box that is an indication of skewness. Thus the box represents the body (middle 50 %) of the data.
A single box plot can be drawn for one batch of data with no distinct groups. It is an easy, but very useful descriptive statistical tool for process data analysis. Special cases for using box plots (e.g. multiple plots) are demonstrated at the industrial application study in Chapter 5.
2.4 Discussion and conclusion
The extremely massive growth of data created at any industrial process ( process data) has become one the main overwhelming problems that most industrial plants and companies have to deal with. In order to be able to solve process failures and
stored. All sort of chemical process in chemical plants generate a constantly grow- ing amount of data such as the output and input variables, historical time record- ing, process stability statistics and more. Therefore, an automated way of storing is needed, moreover in order to deal with all the information that this constantly growing process data is able to provide, several analysis methods can be utilized.
For this purpose the basics of process data warehouse and exploratory data analysis were introduced in this chapter.
Beside the exploratory data analysis, data mining is also a very useful analytic process designed to explore and to extract hidden predictive information, either from databases or data warehouses by searching for consistent patterns and/or sys- tematic relationships or rules between the (process) variables [97]. In the followings (Chapter 3-4) some new data mining tools are introduced.
Chapter 3
Supervised Clustering Based
Compact Decision Tree Induction
3.1 Introduction to pattern recognition
Machine learning is concerned with the design and development of algorithms and techniques that allow computers to learn. There are two main types of machine learning: inductive and deductive. Inductive learning methods extract rules and patterns out of massive data sets. Deductive learning works on existing facts and knowledge and deduces new knowledge from the old one. There are many factors that influence the choice and efficacy of a learning system, such as the amount of domain knowledge used by the system.
A typical machine learning method consists of three phases [89]:
1. Training: a training set of examples of correct behavior is analyzed and some representation of the new knowledge is stored. This is often represented by some form of rules.
2. Validation: the rules are checked and, if necessary, additional training is given. Sometimes additional test data are used, or a human expect may vali- date the rules or some other automatic knowledge based component may be used. - The role of tester is often called the critic.
3. Application: the rules are used in responding to some new situations.
start
collect data
choose features prior
knowledge
choose model
train classifier
evaulate classifier
end
Figure 3.1: Design cycle of a pattern recognition system
egories or classes. Depending on the application, these objects can be images or signal waveforms or any type of measurements that need to be classified. Pattern recognition has a long history, but before the 1960s it was mostly the output of the- oretical research in the area of statistics. Today the main application areas of the pattern recognition are machine vision, character recognition, computer-aided di- agnosis, speech recognition, fingerprint identification, signature authentication, text retrieval, face and gesture recognition, etc. [101].
The design of a pattern recognition system usually entails the repetition of a number of different activities as data collection, feature choice, model choice, train- ing and evaluation (Fig. 3.1). The following description of the steps is adopted from [34].
• Data collection can account for surprisingly large part of the cost of develop- ing a pattern recognition system. It may be possible to perform a preliminary feasibility study with a small set of typical examples, but much more data will usually be needed to assure good performance in the fielded system. The main question is that how do we know when we have collected an adequately large and representative set of examples for training and testing the system?
• Feature choice: The choice of the distinguishing features is a critical design
step and depends on the characteristic of the problem domain. Incorporating prior knowledge can be far more subtle and difficult. In some applications the knowledge ultimately derives from information about the production of pat- terns. In others the knowledge may be about the form of the underlying cate- gories, or specific attributes of the patterns. In selecting or designing features, we obviously would like to find features that are simple to extract, invariant to irrelevant transformations, insensitive to noise, and useful for discriminating patterns in different categories. How do we combine prior knowledge and empirical data to find relevant and effective features?
• Model choice: how do we know when a hypothesized model differs signif- icantly from the true model underlying our patterns, and thus a new model is needed? In short, how are we to know to reject a class of models and try another one?
• Training: in general, the process of using data to determine the classifier is re- ferred to as training the classifier. No universal methods have been developed to solve the problems that arise in the design of patter recognition system.
However, the most effective methods for developing classifiers involve learn- ing from example patterns.
• Evaluation is important both to measure the performance of the system and to identify the need for improvements in its components. While an overly com- plex system may allow perfect classification of training samples, it is unlikely to perform well on new patterns. This situation is known as over-fitting. One of the most important areas of research in statistical pattern classification is determining how to adjust the complexity of the model. It should be not too simple to explain the differences between the categories, yet not too complex to give poor classification on novel patterns. Are there principled methods for finding the optimal (intermediate) complexity of classifier?
In the last decades many types of classifiers were developed for the classification problems (model based techniques: decision tree, Bayes [62, 87, 55, 111], or model independent methods, as for example the k-nearest neighbor [19, 110, 70, 40]). This chapter is focused on decision tree based classification, therefore in the followings, first the basics of decision trees, then the related works of the topic are reviewed.
x1 D1 C1
x1> D1 x1
x2
x2D2 x2> D2
C1 C2
C1
C1 C2
D1 D2
x1 x2
Figure 3.2: Example for a decision tree
3.2 Decision tree based classification
The decision tree induction is a classical method for classification problems. The samples in the learning data set belong to {ci}i≤C classes and the goal of tree in- duction method is to get an input attribute partitioning which warrants the accurate separation of the samples. A decision tree has two types of nodes (internal and terminal) and branches between the nodes. During a top-down run in the tree, the internal nodes represent the decision situations for data attributes, therefore the in- ternal nodes are called as cut (test) nodes. The possible outputs for a cut are rep- resented by the branches. The terminal nodes of the tree are called leaves where the class labels are represented. The pathes from the root to the leaves (sequences of decisions, or cuts) represent the classification rules. Therefore a decision tree is a representation of the data partitioning, it defines a hyper-rectangle. Fig. 3.2 represents a decision tree and the defined three hyper-rectangle where the decision attributes arex1, x2, the cut points areD1, D2 and the classes areC1 andC2. Each leaves of the tree represent a region which is equivalent to a classification rule. See for example the leaf at the outside right which represents the following rules: If x1 > D1 Andx2 > D2 ThenC2 (For example, if the temperature of the reactor is higher thanD1 and the pressure is higher than D2 then product has good quality).
The most of the decision tree induction algorithms (e.g. ID3, C4.5) are based on the divide and conquer strategy. In every iteration steps the cut which serves topically the highest information gain (greedy algorithms) is realized.
The crisp and fuzzy decision trees are similar in structural point of view (nodes, branches, etc.), but in the case of fuzzy trees, the cuts, the decision situations are fuzzy. The most frequently used types of attribute partitioning are the Gauss, the sigmoid and the fractionally linear dichotomies. For more than two partitions,
x2
x1
x1
C1(PC1) C2(PC2) C1(PC1)
C2(PC2)
x2
1 0
1 0
Figure 3.3: Fuzzy decision tree and fuzzy partitions
Gauss, triangular or trapezoidal fuzzy sets can be constructed from the basic func- tions. The fuzzy sets as membership functions determine the membership values of the data points. Thanks to the fuzzy logic, the membership values of a data point can be calculated for all the fuzzy membership functions (fuzzy sets) at the given attribute. Accordingly it is possible that the samples belong to many classes (with several membership values) simultaneously. The Fig. 3.3 shows an example for the fuzzy partitioning (by trapezoids) and the fuzzy decision tree. The quality of the partitioning is very important at the decision tree induction algorithms which apply a priori partitioning, because the partitions have a key role in the classification per- formance.
Related works
As a result of the increasing complexity of classification problems it becomes nec- essary to deal with structural issues of the identification of classifier systems. The input attributes of a classification problem can be basically continuous or discrete in values. Also the interpretability of models and the nature of some learning al- gorithms require effectively discretized (partitioned) features. Hence, the effective partitioning of input domains of continuous input variables is an important aspect regarding the accuracy and transparency of classifier systems. Moreover consider- ing the characterization of process data (most of the process variables is continuous in value) an efficient discretization is a very important part of the classifier system.
A discretization method can be a priori or dynamic. In a priori partitioning methods the attributes are partitioned before to the induction of the tree. Contrarily,
most known decision tree induction methods that utilize a priori partitions are the ID3 [84] and the AQ [73] algorithms. The most current dynamic methods are the CART [16], the Dynamic-ID3 [38], the Assistant [56] and the C4.5 [85] algorithms.
Fuzzy partitioning of continuous features can increase the flexibility of the clas- sifier since it has the ability to model fine knowledge details. The particular draw- back of discretization into crisp sets (intervals) is that small variations of the inputs (e.g., due to noise) can cause large changes of the output. This is because the tests are based on Boolean logic and, as a result, only one branch can be followed after a test. By using fuzzy predicates, decision trees can be used to model vague deci- sions. The basic idea of fuzzy decision trees is to combine data-based learning of decision trees with approximate reasoning of fuzzy logic [52]. In fuzzy decision trees, several branches originating from the same node can be simultaneously valid to a certain degree, according to the result of the fuzzy test (see the example in Fig. 3.4). The path from the root node to a particular leaf model therefore defines a fuzzy operating range of that particular model. The output of the tree is obtained by interpolating the outputs of the leaf models that are simultaneously active. Be- side fuzzy decision trees represent discovered rules far natural for human, fuzzy logic serves more robust classifiers in case of false, inconsistent, and missing data.
Fuzzy logic, however, is not a guarantee for interpretability, as was also recognized in [96, 28]. Real effort must be made to keep the resulting rule-base transparent [95, 76].
Since the 80’s years many fuzzy decision tree induction algorithm have been introduced [3, 37, 61]. The paper [116] analyzes the cognitive doubtfulness attached to the classification problem and propose a fuzzy decision tree method for solution.
In [102] and [117] genetic algorithms are introduced for tree induction. The Neuro- fuzzy ID3 algorithm is introduced in [48], where linear programming is used to tree induction. The FILM (fuzzy inductive learning method) method has been proposed in [53]. This method converts a general decision tree to a fuzzy one. Boyen and Wehenkel introduced a new induction algorithm for problems where input variables are continuous and the output is fuzzy [15].
(Fuzzy) decision trees based on the original ID3 algorithm assume discrete do- mains with small cardinalities. Another important feature of ID3 trees is that each attribute can provide at most one condition on a given path. It is great advantage as they increases comprehensibility of the induced knowledge, but may require a good a priori partitioning, because the first discretization step of the data mining procedure especially affects the classification performance. Hence, for this purpose
Janikow introduced a genetic algorithm to optimize this partition step [51], while Pedrycz proposed an environment dependent clustering algorithm to get adequate partitions [83].
Motivations and goals
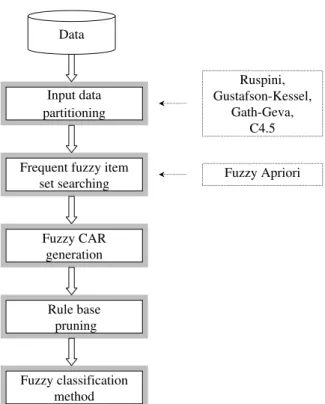
As previous papers illustrate, decision tree and rule induction methods often rely on a priori discretized continuous features. However, advantages of the supervised and fuzzy discretization of attributes have not been shown yet. This chapter shows a study which proposes a supervised clustering algorithm for providing informative input information for decision tree induction algorithms. For the tree induction the FID algorithm is applied [52]. It has the advantage that the resulted fuzzy decision tree can be transformed into a fuzzy rule based classifier and in this way the per- formance and complexity of classification model can fine-tuned by a rule pruning algorithm.
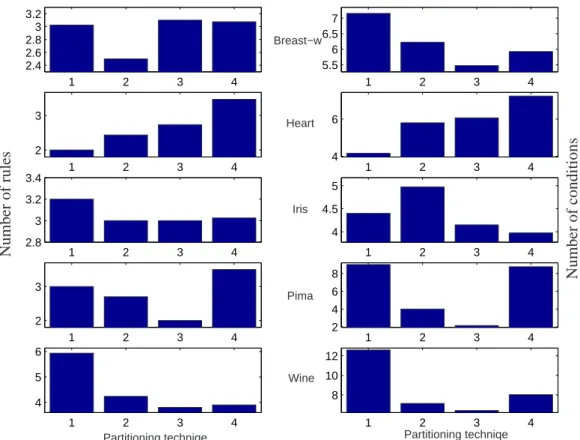
The new method has been implemented as a fuzzy classification toolbox in MATLAB, it is called FIDMAT (Fuzzy decision tree Induction in MATlab). With the FIDMAT toolbox the classification performance of the original FID program can be easily analyzed. The toolbox makes possible to compare several partitioning techniques as the FID partitioning method, Ruspini-type partition and the new clus- tering based approach. Moreover performances and complexities of classifiers can also be compared with other well known decision tree based classifiers, for example with the C4.5 algorithm.
The rest of the chapter is structured in the following sections. Section 3.3 intro- duces the structure of the fuzzy classifier. In Section 3.4 the proposed supervised a priori partitioning algorithm is presented. In Section 3.5 an experimental study illustrates that compact, perspicuous and accurate fuzzy classification models can be identified by the new approach.
3.3 Structure of classifiers
3.3.1 Structure of decision tree based classifiers
Decision tree induction is the most important discriminative learning algorithm working by recursive partitioning. The basic idea is to partition the sample space
x3
large small
medium C1=0.13
C2=7.89
C1=0
C2=4.50 x2
small medium
C1=0
C2=1.95 x1
small
x5
small
medium large
C1=0.23 C2=0.16
C1=1.31 C2=0
C1=0.44 C2=0.10 medium
C1=0.11 C2=0
large
x4
small
medium
C1=0 C2=0.49
C1=0.72 C2=1.16
x3
1
small med large
x2
1
small med large
x1
1
small med large
x5
1
small med large
l1 l2
l3
l4 l5 l6
l7
l8 l9
Figure 3.4: A fuzzy decision tree and classification rules as partitions of attributes, xj is the jth attribute,Ci represents the ith class, the number afterCi is related to a probability measure (class with higher value is more important)
decision tree is presented in Fig. 3.4.
An important property of this type of algorithms is that they attempt to mini- mize the size of the tree and at the same time they optimize some quality measure.
Afterwards, they use the same inference mechanism. Features of a new sample are matched against the conditions of the tree. Hopefully, there will be exactly one leaf node whose conditions (on the path) will be satisfied. For example, a new sam- ple with the following features: x3 is large andx2 is small matches the conditions leading to theC2class (for examplex3 is the temperature,x2 is the pressure of the reactor andC2 is the resulted product).
Decision trees are in the first place suited for categorical attributes. Various methods have been introduced to handle numerical attributes by discretized their domains [16]. For example, Dynamic-ID3 clusters multi-valued ordered domains [31], and Assistant produces binary trees by clustering domain values (limited to domains of small cardinality) [73]. However, most research has concentrated on a priori partitioning techniques [83]. This work focuses on the application of a priori fuzzy partitions. Decision trees based on this kind of input data can be generated