SemEval 2021
The 15th International Workshop on Semantic Evaluation (SemEval-2021)
Proceedings of the Workshop
August 5 - 6, 2021
Bangkok, Thailand (online)
©2021 The Association for Computational Linguistics
and The Asian Federation of Natural Language Processing
Order copies of this and other ACL proceedings from:
Association for Computational Linguistics (ACL) 209 N. Eighth Street
Stroudsburg, PA 18360 USATel: +1-570-476-8006 Fax: +1-570-476-0860 acl@aclweb.org ISBN 978-1-954085-70-1
ii
Introduction
Welcome to SemEval-2021!
The Semantic Evaluation (SemEval) series of workshops focuses on the evaluation and comparison of systems that can analyze diverse semantic phenomena in text, with the aims of extending the current state of the art in semantic analysis and creating high quality annotated datasets in a range of increasingly challenging problems in natural language semantics. SemEval provides an exciting forum for researchers to propose challenging research problems in semantics and to build systems/techniques to address such research problems.
SemEval-2021 is the fifteenth workshop in the series of International Workshops on Semantic Evaluation.
The first three workshops, SensEval-1 (1998), SensEval-2 (2001), and SensEval-3 (2004), focused on word sense disambiguation, each time expanding in the number of languages offered, the number of tasks, and also the number of teams participating. In 2007, the workshop was renamed to SemEval, and the subsequent SemEval workshops evolved to include semantic analysis tasks beyond word sense disambiguation. In 2012, SemEval became a yearly event. It currently takes place every year, on a two- year cycle. The tasks for SemEval-2021 were proposed in 2020, and next year’s tasks have already been selected and are underway.
SemEval-2021 is co-located (virtually) with The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021) on August 5–6. This year’s SemEval included the following 11 tasks:
• Lexical semantics
– Task 1: Lexical Complexity Prediction
– Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation – Task 4: Reading Comprehension of Abstract Meaning
• Social factors & opinion
– Task 5: Toxic Spans Detection
– Task 6: Detection of Persuasive Techniques in Texts and Images – Task 7: HaHackathon: Detecting and Rating Humor and Offense
• Information in scientific & clinical text
– Task 8: MeasEval: Counts and Measurements
– Task 9: Statement Verification and Evidence Finding with Tables – Task 10: Source-Free Domain Adaptation for Semantic Processing – Task 11: NLPContributionGraph
• Other phenomena
– Task 12: Learning with Disagreements
This volume contains both task description papers that describe each of the above tasks and system description papers that present the systems that participated in the tasks. A total of 11 task description papers and 175 system description papers are included in this volume.
SemEval-2021 features two awards, one for organizers of a task and one for a team participating in a task.
The Best Task award recognizes a task that stands out for making an important intellectual contribution to empirical computational semantics, as demonstrated by a creative, interesting, and scientifically rigorous dataset and evaluation design, and a well-written task overview paper. The Best Paper award recognizes a system description paper (written by a team participating in one of the tasks) that advances our understanding of a problem and available solutions with respect to a task. It need not be the highest- scoring system in the task, but it must have a strong analysis component in the evaluation, as well as a clear and reproducible description of the problem, algorithms, and methodology.
2021 has been another particularly challenging year across the globe. We are immensely grateful to the task organizers for their perseverance through many ups, downs, and uncertainties, as well as to the large number of participants whose enthusiastic participation has made SemEval once again a successful event! Thanks also to the task organizers who served as area chairs for their tasks, and to both task organizers and participants who reviewed paper submissions. These proceedings have greatly benefited from their detailed and thoughtful feedback. Thousands of thanks to our assistant organizers Julia R.
Bonn and Abhidip Bhattacharyya for their extensive, detailed, and dedicated work on the production of these proceedings! We also thank the members of the program committee who reviewed the submitted task proposals and helped us to select this exciting set of tasks, and we thank the ACL 2021 conference organizers for their support. Finally, we most gratefully acknowledge the support of our sponsor: the ACL Special Interest Group on the Lexicon (SIGLEX).
The SemEval-2021 organizers: Guy Emerson, Aurelie Herbelot, Alexis Palmer, Natalie Schluter, Nathan Schneider, and Xiaodan Zhu
iv
Organizing Committee
SemEval Organizers:
Alexis Palmer, University of Colorado Boulder Nathan Schneider, Georgetown University
Natalie Schluter, IT University of Copenhagen & Google Brain Guy Emerson, University of Cambridge
Xiaodan Zhu, Queen’s University Aurelie Herbelot, University of Trento Assistant Organizers:
Julia R. Bonn, University of Colorado Boulder
Abhidip Bhattacharyya, University of Colorado Boulder Task Selection Committee:
Eneko Agirre, Francesco Barbieri, Alberto Barrón-Cedeño, Valerio Basile, Steven Bethard, Geor- geta Bordea, Davide Buscaldi, Tanmoy Chakraborty, Wanxiang Che, Colin Cherry, Keith Cortis, Giovanni Da San Martino, Amitava Das, Tobias Daudert, Franck Dernoncourt, Luis Espinosa Anke, André Freitas, Dimitris Galanis, Michael Gamon, Goran Glavaš, Ivan Habernal, Simon Hengchen, Nabil Hossain, Filip Ilievski, Els Lefever, Alessandro Lenci, Shuailong Liang, Nedim Lipka, Shervin Malmasi, Jonathan May, Tristan Miller, Ashutosh Modi, Saif Mohammad, Preslav Nakov, Roberto Navigli, Mohammad Taher Pilehvar, Manfred Pinkal, Maria Pontiki, Soujanya Poria, Marten Postma, Matthew Purver, Alan Ritter, Marko Robnik-Sikonja, Francesco Ronzano, Michael Roth, Mohammad Salameh, Juliano Efson Sales, Dominik Schlechtweg, Fabrizio Sebas- tiani, Ekaterina Shutova, Vered Shwartz, Sasha Spala, Karin Verspoor, Cunxiang Wang, Xiaoyu Yang, Marcos Zampieri, Qiong Zhang, Arkaitz Zubiaga
Task Organizers:
Task 1: Matthew Shardlow, Richard Evans, Gustavo Henrique Paetzold, Marcos Zampieri Task 2: Federico Martelli, Najla Kalach, Gabriele Tola, Roberto Navigli
Task 4: Boyuan Zheng, Xiaoyu Yang, Yu-Ping Ruan, Quan Liu, Zhen-Hua Ling, Si Wei, Xiaodan Zhu
Task 5: John Pavlopoulos, Ion Androutsopoulos, Jeffrey Sorensen, Léo Laugier Task 6: Giovanni Da San Martino, Hamed Firooz, Preslav Nakov, Fabrizio Silvestri Task 7: J. A. Meaney, Steven Wilson, Walid Magdy, Luis Chiruzzo
Task 8: Corey Harper, Jessica Cox, Ron Daniel, Paul Groth, Curt Kohler, Antony Scerri Task 9: Nancy Xin Ru Wang, Sara Rosenthal, Marina Danilevsky, Diwakar Mahajan Task 10: Steven Bethard, Egoitz Laparra, Timothy Miller, Özlem Uzuner
Task 11: Jennifer D’Souza, Sören Auer, Ted Pedersen
Task 12: Alexandra Uma, Tommaso Fornaciari, Tristan Miller, Barbara Plank, Edwin Simpson, Massimo Poesio
Invited Speakers:
Diyi Yang, Georgia Institute of Technology (shared speaker with *SEM) Hannah Rohde, University of Edinburgh
Table of Contents
SemEval-2021 Task 1: Lexical Complexity Prediction
Matthew Shardlow, Richard Evans, Gustavo Henrique Paetzold and Marcos Zampieri. . . .1 OCHADAI-KYOTO at SemEval-2021 Task 1: Enhancing Model Generalization and Robustness for Lex- ical Complexity Prediction
Yuki Taya, Lis Kanashiro Pereira, Fei Cheng and Ichiro Kobayashi . . . .17 SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation (MCL-WiC)
Federico Martelli, Najla Kalach, Gabriele Tola and Roberto Navigli. . . .24 SemEval-2021 Task 4: Reading Comprehension of Abstract Meaning
Boyuan Zheng, Xiaoyu Yang, Yu-Ping Ruan, Zhenhua Ling, Quan Liu, Si Wei and Xiaodan Zhu37 TA-MAMC at SemEval-2021 Task 4: Task-adaptive Pretraining and Multi-head Attention for Abstract Meaning Reading Comprehension
Jing Zhang, Yimeng Zhuang and Yinpei Su. . . .51 SemEval-2021 Task 5: Toxic Spans Detection
John Pavlopoulos, Jeffrey Sorensen, Léo Laugier and Ion Androutsopoulos . . . .59 SemEval-2021 Task 6: Detection of Persuasion Techniques in Texts and Images
Dimitar Dimitrov, Bishr Bin Ali, Shaden Shaar, Firoj Alam, Fabrizio Silvestri, Hamed Firooz, Preslav Nakov and Giovanni Da San Martino . . . .70 Alpha at SemEval-2021 Task 6: Transformer Based Propaganda Classification
Zhida Feng, Jiji Tang, Jiaxiang Liu, Weichong Yin, Shikun Feng, Yu Sun and Li Chen . . . .99 SemEval 2021 Task 7: HaHackathon, Detecting and Rating Humor and Offense
J. A. Meaney, Steven Wilson, Luis Chiruzzo, Adam Lopez and Walid Magdy . . . .105 LangResearchLab NC at SemEval-2021 Task 1: Linguistic Feature Based Modelling for Lexical Com- plexity
Raksha Agarwal and Niladri Chatterjee . . . .120 Complex words identification using word-level features for SemEval-2020 Task 1
Jenny A. Ortiz-Zambrano and Arturo Montejo-Ráez . . . .126 TUDA-CCL at SemEval-2021 Task 1: Using Gradient-boosted Regression Tree Ensembles Trained on a Heterogeneous Feature Set for Predicting Lexical Complexity
Sebastian Gombert and Sabine Bartsch . . . .130 JCT at SemEval-2021 Task 1: Context-aware Representation for Lexical Complexity Prediction
Chaya Liebeskind, Otniel Elkayam and Shmuel Liebeskind . . . .138 IAPUCP at SemEval-2021 Task 1: Stacking Fine-Tuned Transformers is Almost All You Need for Lexical Complexity Prediction
Kervy Rivas Rojas and Fernando Alva-Manchego . . . .144 Uppsala NLP at SemEval-2021 Task 2: Multilingual Language Models for Fine-tuning and Feature Extraction in Word-in-Context Disambiguation
Huiling You, Xingran Zhu and Sara Stymne . . . .150
SkoltechNLP at SemEval-2021 Task 2: Generating Cross-Lingual Training Data for the Word-in-Context Task
Anton Razzhigaev, Nikolay Arefyev and Alexander Panchenko. . . .157 Zhestyatsky at SemEval-2021 Task 2: ReLU over Cosine Similarity for BERT Fine-tuning
Boris Zhestiankin and Maria Ponomareva . . . .163 SzegedAI at SemEval-2021 Task 2: Zero-shot Approach for Multilingual and Cross-lingual Word-in- Context Disambiguation
Gábor Berend . . . .169 ReCAM@IITK at SemEval-2021 Task 4: BERT and ALBERT based Ensemble for Abstract Word Predic- tion
Abhishek Mittal and Ashutosh Modi. . . .175 ECNU_ICA_1 SemEval-2021 Task 4: Leveraging Knowledge-enhanced Graph Attention Networks for Reading Comprehension of Abstract Meaning
Pingsheng Liu, Linlin Wang, Qian Zhao, Hao Chen, Yuxi Feng, Xin Lin and liang he. . . .183 LRG at SemEval-2021 Task 4: Improving Reading Comprehension with Abstract Words using Augmen- tation, Linguistic Features and Voting
Abheesht Sharma, Harshit Pandey, Gunjan Chhablani, Yash Bhartia and Tirtharaj Dash . . . .189 IIE-NLP-Eyas at SemEval-2021 Task 4: Enhancing PLM for ReCAM with Special Tokens, Re-Ranking, Siamese Encoders and Back Translation
Yuqiang Xie, Luxi Xing, Wei Peng and Yue Hu . . . .199 NLP-IIS@UT at SemEval-2021 Task 4: Machine Reading Comprehension using the Long Document Transformer
Hossein Basafa, Sajad Movahedi, Ali Ebrahimi, Azadeh Shakery and Heshaam Faili . . . .205 IITK@Detox at SemEval-2021 Task 5: Semi-Supervised Learning and Dice Loss for Toxic Spans Detec- tion
Archit Bansal, Abhay Kaushik and Ashutosh Modi . . . .211 UniParma at SemEval-2021 Task 5: Toxic Spans Detection Using CharacterBERT and Bag-of-Words Model
Akbar Karimi, Leonardo Rossi and Andrea Prati . . . .220 UPB at SemEval-2021 Task 5: Virtual Adversarial Training for Toxic Spans Detection
Andrei Paraschiv, Dumitru-Clementin Cercel and Mihai Dascalu . . . .225 NLRG at SemEval-2021 Task 5: Toxic Spans Detection Leveraging BERT-based Token Classification and Span Prediction Techniques
Gunjan Chhablani, Abheesht Sharma, Harshit Pandey, Yash Bhartia and Shan Suthaharan. . . . .233 UoB at SemEval-2021 Task 5: Extending Pre-Trained Language Models to Include Task and Domain- Specific Information for Toxic Span Prediction
Erik Yan and Harish Tayyar Madabushi . . . .243 Cisco at SemEval-2021 Task 5: What’s Toxic?: Leveraging Transformers for Multiple Toxic Span Ex- traction from Online Comments
Sreyan Ghosh and Sonal Kumar . . . .249
viii
MedAI at SemEval-2021 Task 5: Start-to-end Tagging Framework for Toxic Spans Detection
Zhen Wang, Hongjie Fan and Junfei Liu . . . .258 HamiltonDinggg at SemEval-2021 Task 5: Investigating Toxic Span Detection using RoBERTa Pre- training
Huiyang Ding and David Jurgens. . . .263 WVOQ at SemEval-2021 Task 6: BART for Span Detection and Classification
Cees Roele. . . .270 HumorHunter at SemEval-2021 Task 7: Humor and Offense Recognition with Disentangled Attention
Yubo Xie, Junze Li and Pearl Pu . . . .275 Grenzlinie at SemEval-2021 Task 7: Detecting and Rating Humor and Offense
Renyuan Liu and Xiaobing Zhou . . . .281 abcbpc at SemEval-2021 Task 7: ERNIE-based Multi-task Model for Detecting and Rating Humor and Offense
Chao Pang, Xiaoran Fan, Weiyue Su, Xuyi Chen, Shuohuan Wang, Jiaxiang Liu, Xuan Ouyang, Shikun Feng and Yu Sun . . . .286 Humor@IITK at SemEval-2021 Task 7: Large Language Models for Quantifying Humor and Offensive- ness
Aishwarya Gupta, Avik Pal, Bholeshwar Khurana, Lakshay Tyagi and Ashutosh Modi. . . .290 RoMa at SemEval-2021 Task 7: A Transformer-based Approach for Detecting and Rating Humor and Offense
Roberto Labadie, Mariano Jason Rodriguez, Reynier Ortega and Paolo Rosso . . . .297 SemEval-2021 Task 8: MeasEval – Extracting Counts and Measurements and their Related Contexts
Corey Harper, Jessica Cox, Curt Kohler, Antony Scerri, Ron Daniel Jr. and Paul Groth . . . .306 SemEval-2021 Task 9: Fact Verification and Evidence Finding for Tabular Data in Scientific Documents (SEM-TAB-FACTS)
Nancy X. R. Wang, Diwakar Mahajan, Marina Danilevsky and Sara Rosenthal . . . .317 BreakingBERT@IITK at SemEval-2021 Task 9: Statement Verification and Evidence Finding with Tables Aditya Jindal, Ankur Gupta, Jaya Srivastava, Preeti Menghwani, Vijit Malik, Vishesh Kaushik and Ashutosh Modi . . . .327 SemEval-2021 Task 12: Learning with Disagreements
Alexandra Uma, Tommaso Fornaciari, Anca Dumitrache, Tristan Miller, Jon Chamberlain, Barbara Plank, Edwin Simpson and Massimo Poesio . . . .338 SemEval-2021 Task 10: Source-Free Domain Adaptation for Semantic Processing
Egoitz Laparra, Xin Su, Yiyun Zhao, Özlem Uzuner, Timothy Miller and Steven Bethard . . . . .348 BLCUFIGHT at SemEval-2021 Task 10: Novel Unsupervised Frameworks For Source-Free Domain Adaptation
Weikang Wang, Yi Wu, Yixiang Liu and Pengyuan Liu . . . .357 SemEval-2021 Task 11: NLPContributionGraph - Structuring Scholarly NLP Contributions for a Re- search Knowledge Graph
Jennifer D’Souza, Sören Auer and Ted Pedersen . . . .364
UIUC_BioNLP at SemEval-2021 Task 11: A Cascade of Neural Models for Structuring Scholarly NLP Contributions
Haoyang Liu, M. Janina Sarol and Halil Kilicoglu . . . .377 KGP at SemEval-2021 Task 8: Leveraging Multi-Staged Language Models for Extracting Measurements, their Attributes and Relations
Neel Karia, Ayush Kaushal and Faraaz Mallick . . . .387 DPR at SemEval-2021 Task 8: Dynamic Path Reasoning for Measurement Relation Extraction
Amir Pouran Ben Veyseh, Franck Dernoncourt and Thien Huu Nguyen . . . .397 CLaC-np at SemEval-2021 Task 8: Dependency DGCNN
Nihatha Lathiff, Pavel PK Khloponin and Sabine Bergler . . . .404 CLaC-BP at SemEval-2021 Task 8: SciBERT Plus Rules for MeasEval
Benjamin Therien, Parsa Bagherzadeh and Sabine Bergler . . . .410 THiFly_Queens at SemEval-2021 Task 9: Two-stage Statement Verification with Adaptive Ensembling and Slot-based Operation
Yuxuan Zhou, Kaiyin Zhou, Xien Liu, Ji Wu and Xiaodan Zhu . . . .416 TAPAS at SemEval-2021 Task 9: Reasoning over tables with intermediate pre-training
Thomas Müller, Julian Eisenschlos and Syrine Krichene . . . .423 BOUN at SemEval-2021 Task 9: Text Augmentation Techniques for Fact Verification in Tabular Data
Abdullatif Köksal, Yusuf Yüksel, Bekir Yıldırım and Arzucan Özgür . . . .431 IITK at SemEval-2021 Task 10: Source-Free Unsupervised Domain Adaptation using Class Prototypes
Harshit Kumar, Jinang Shah, Nidhi Hegde, Priyanshu Gupta, Vaibhav Jindal and Ashutosh Modi 438
PTST-UoM at SemEval-2021 Task 10: Parsimonious Transfer for Sequence Tagging
Kemal Kurniawan, Lea Frermann, Philip Schulz and Trevor Cohn . . . .445 Self-Adapter at SemEval-2021 Task 10: Entropy-based Pseudo-Labeler for Source-free Domain Adap- tation
Sangwon Yoon, Yanghoon Kim and Kyomin Jung . . . .452 The University of Arizona at SemEval-2021 Task 10: Applying Self-training, Active Learning and Data Augmentation to Source-free Domain Adaptation
Xin Su, Yiyun Zhao and Steven Bethard . . . .458 KnowGraph@IITK at SemEval-2021 Task 11: Building Knowledge Graph for NLP Research
Shashank Shailabh, Sajal Chaurasia and Ashutosh Modi . . . .467 YNU-HPCC at SemEval-2021 Task 11: Using a BERT Model to Extract Contributions from NLP Schol- arly Articles
Xinge Ma, Jin Wang and Xuejie Zhang . . . .478 ITNLP at SemEval-2021 Task 11: Boosting BERT with Sampling and Adversarial Training for Knowl- edge Extraction
Genyu Zhang, Yu Su, Changhong He, Lei Lin, Chengjie Sun and Lili Shan . . . .485
x
Duluth at SemEval-2021 Task 11: Applying DeBERTa to Contributing Sentence Selection and Depen- dency Parsing for Entity Extraction
Anna Martin and Ted Pedersen . . . .490 INNOVATORS at SemEval-2021 Task-11: A Dependency Parsing and BERT-based model for Extracting Contribution Knowledge from Scientific Papers
Hardik Arora, Tirthankar Ghosal, Sandeep Kumar, Suraj Patwal and Phil Gooch . . . .502 MCL@IITK at SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation using Augmented Data, Signals, and Transformers
Rohan Gupta, Jay Mundra, Deepak Mahajan and Ashutosh Modi . . . .511 HITSZ-HLT at SemEval-2021 Task 5: Ensemble Sequence Labeling and Span Boundary Detection for Toxic Span Detection
Qinglin Zhu, Zijie Lin, Yice Zhang, Jingyi Sun, Xiang Li, Qihui Lin, Yixue Dang and Ruifeng Xu 521
SarcasmDet at SemEval-2021 Task 7: Detect Humor and Offensive based on Demographic Factors using RoBERTa Pre-trained Model
Dalya Faraj and Malak Abdullah . . . .527 UPB at SemEval-2021 Task 8: Extracting Semantic Information on Measurements as Multi-Turn Ques- tion Answering
Andrei-Marius Avram, George-Eduard Zaharia, Dumitru-Clementin Cercel and Mihai Dascalu534 IITK@LCP at SemEval-2021 Task 1: Classification for Lexical Complexity Regression Task
Neil Shirude, Sagnik Mukherjee, Tushar Shandhilya, Ananta Mukherjee and Ashutosh Modi . .541 LCP-RIT at SemEval-2021 Task 1: Exploring Linguistic Features for Lexical Complexity Prediction
Abhinandan Tejalkumar Desai, Kai North, Marcos Zampieri and Christopher Homan. . . .548 Alejandro Mosquera at SemEval-2021 Task 1: Exploring Sentence and Word Features for Lexical Com- plexity Prediction
Alejandro Mosquera . . . .554 CompNA at SemEval-2021 Task 1: Prediction of lexical complexity analyzing heterogeneous features
Giuseppe Vettigli and Antonio Sorgente. . . .560 PolyU CBS-Comp at SemEval-2021 Task 1: Lexical Complexity Prediction (LCP)
Rong Xiang, Jinghang Gu, Emmanuele Chersoni, Wenjie Li, Qin Lu and Chu-Ren Huang . . . .565 LAST at SemEval-2021 Task 1: Improving Multi-Word Complexity Prediction Using Bigram Association Measures
Yves Bestgen . . . .571 DeepBlueAI at SemEval-2021 Task 1: Lexical Complexity Prediction with A Deep Ensemble Approach
Chunguang Pan, Bingyan Song, Shengguang Wang and Zhipeng Luo . . . .578 CS-UM6P at SemEval-2021 Task 1: A Deep Learning Model-based Pre-trained Transformer Encoder for Lexical Complexity
Nabil El Mamoun, Abdelkader El Mahdaouy, Abdellah El Mekki, Kabil Essefar and Ismail Berrada 585
Cambridge at SemEval-2021 Task 1: An Ensemble of Feature-Based and Neural Models for Lexical Complexity Prediction
Zheng Yuan, Gladys Tyen and David Strohmaier. . . .590 hub at SemEval-2021 Task 1: Fusion of Sentence and Word Frequency to Predict Lexical Complexity
Bo Huang, Yang Bai and Xiaobing Zhou . . . .598 Manchester Metropolitan at SemEval-2021 Task 1: Convolutional Networks for Complex Word Identifi- cation
Robert Flynn and Matthew Shardlow . . . .603 UPB at SemEval-2021 Task 1: Combining Deep Learning and Hand-Crafted Features for Lexical Com- plexity Prediction
George-Eduard Zaharia, Dumitru-Clementin Cercel and Mihai Dascalu . . . .609 UTFPR at SemEval-2021 Task 1: Complexity Prediction by Combining BERT Vectors and Classic Fea- tures
Gustavo Henrique Paetzold . . . .617 RG PA at SemEval-2021 Task 1: A Contextual Attention-based Model with RoBERTa for Lexical Com- plexity Prediction
Gang Rao, Maochang Li, Xiaolong Hou, Lianxin Jiang, Yang Mo and Jianping Shen . . . .623 CSECU-DSG at SemEval-2021 Task 1: Fusion of Transformer Models for Lexical Complexity Prediction Abdul Aziz, MD. Akram Hossain and Abu Nowshed Chy . . . .627 CLULEX at SemEval-2021 Task 1: A Simple System Goes a Long Way
Greta Smolenska, Peter Kolb, Sinan Tang, Mironas Bitinis, Héctor Hernández and Elin Asklöv632 RS_GV at SemEval-2021 Task 1: Sense Relative Lexical Complexity Prediction
Regina Stodden and Gayatri Venugopal . . . .640 UNBNLP at SemEval-2021 Task 1: Predicting lexical complexity with masked language models and character-level encoders
Milton King, Ali Hakimi Parizi, Samin Fakharian and Paul Cook . . . .650 ANDI at SemEval-2021 Task 1: Predicting complexity in context using distributional models, behavioural norms, and lexical resources
Armand Rotaru . . . .655 JUST-BLUE at SemEval-2021 Task 1: Predicting Lexical Complexity using BERT and RoBERTa Pre- trained Language Models
Tuqa Bani Yaseen, Qusai Ismail, Sarah Al-Omari, Eslam Al-Sobh and Malak Abdullah . . . .661 BigGreen at SemEval-2021 Task 1: Lexical Complexity Prediction with Assembly Models
Aadil Islam, Weicheng Ma and Soroush Vosoughi . . . .667 cs60075_team2 at SemEval-2021 Task 1 : Lexical Complexity Prediction using Transformer-based Lan- guage Models pre-trained on various text corpora
Abhilash Nandy, Sayantan Adak, Tanurima Halder and Sai Mahesh Pokala . . . .678 C3SL at SemEval-2021 Task 1: Predicting Lexical Complexity of Words in Specific Contexts with Sen- tence Embeddings
Raul Almeida, Hegler Tissot and Marcos Didonet Del Fabro . . . .683
xii
Stanford MLab at SemEval-2021 Task 1: Tree-Based Modelling of Lexical Complexity using Word Em- beddings
Erik Rozi, Niveditha Iyer, Gordon Chi, Enok Choe, Kathy J. Lee, Kevin Liu, Patrick Liu, Zander Lack, Jillian Tang and Ethan A. Chi . . . .688 archer at SemEval-2021 Task 1: Contextualising Lexical Complexity
Irene Russo . . . .694 katildakat at SemEval-2021 Task 1: Lexical Complexity Prediction of Single Words and Multi-Word Expressions in English
Katja Voskoboinik . . . .700 GX at SemEval-2021 Task 2: BERT with Lemma Information for MCL-WiC Task
Wanying Xie . . . .706 PALI at SemEval-2021 Task 2: Fine-Tune XLM-RoBERTa for Word in Context Disambiguation
Shuyi Xie, Jian Ma, Haiqin Yang, Lianxin Jiang, Yang Mo and Jianping Shen . . . .713 hub at SemEval-2021 Task 2: Word Meaning Similarity Prediction Model Based on RoBERTa and Word Frequency
Bo Huang, Yang Bai and Xiaobing Zhou . . . .719 Lotus at SemEval-2021 Task 2: Combination of BERT and Paraphrasing for English Word Sense Disam- biguation
Niloofar Ranjbar and Hossein Zeinali . . . .724 Cambridge at SemEval-2021 Task 2: Neural WiC-Model with Data Augmentation and Exploration of Representation
Zheng Yuan and David Strohmaier . . . .730 UoB_UK at SemEval 2021 Task 2: Zero-Shot and Few-Shot Learning for Multi-lingual and Cross-lingual Word Sense Disambiguation.
Wei Li, Harish Tayyar Madabushi and Mark Lee . . . .738 PAW at SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation : Ex- ploring Cross Lingual Transfer, Augmentations and Adversarial Training
Harsh Goyal, Aadarsh Singh and Priyanshu Kumar . . . .743 LU-BZU at SemEval-2021 Task 2: Word2Vec and Lemma2Vec performance in Arabic Word-in-Context disambiguation
Moustafa Al-Hajj and Mustafa Jarrar . . . .748 GlossReader at SemEval-2021 Task 2: Reading Definitions Improves Contextualized Word Embeddings
Maxim Rachinskiy and Nikolay Arefyev . . . .756 UAlberta at SemEval-2021 Task 2: Determining Sense Synonymy via Translations
Bradley Hauer, Hongchang Bao, Arnob Mallik and Grzegorz Kondrak . . . .763 TransWiC at SemEval-2021 Task 2: Transformer-based Multilingual and Cross-lingual Word-in-Context Disambiguation
Hansi Hettiarachchi and Tharindu Ranasinghe . . . .771 LIORI at SemEval-2021 Task 2: Span Prediction and Binary Classification approaches to Word-in- Context Disambiguation
Adis Davletov, Nikolay Arefyev, Denis Gordeev and Alexey Rey . . . .780
FII_CROSS at SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation Ciprian Bodnar, Andrada Tapuc, Cosmin Pintilie, Daniela Gifu and Diana Trandabat . . . .787 XRJL-HKUST at SemEval-2021 Task 4: WordNet-Enhanced Dual Multi-head Co-Attention for Reading Comprehension of Abstract Meaning
Yuxin Jiang, Ziyi Shou, Qijun Wang, Hao Wu and Fangzhen Lin . . . .793 UoR at SemEval-2021 Task 4: Using Pre-trained BERT Token Embeddings for Question Answering of Abstract Meaning
Thanet Markchom and Huizhi Liang. . . .799 Noobs at Semeval-2021 Task 4: Masked Language Modeling for abstract answer prediction
Shikhar Shukla, Sarthak Sarthak and Karm Veer Arya . . . .805 ZJUKLAB at SemEval-2021 Task 4: Negative Augmentation with Language Model for Reading Compre- hension of Abstract Meaning
Xin Xie, Xiangnan Chen, Xiang Chen, Yong Wang, Ningyu Zhang, Shumin Deng and Huajun Chen 810
PINGAN Omini-Sinitic at SemEval-2021 Task 4:Reading Comprehension of Abstract Meaning
Ye Wang, Yanmeng Wang, Haijun Zhu, Bo Zeng, Zhenghong Hao, Shaojun Wang and Jing Xiao 820
NEUer at SemEval-2021 Task 4: Complete Summary Representation by Filling Answers into Question for Matching Reading Comprehension
Zhixiang Chen, yikun lei, Pai Liu and Guibing Guo . . . .827 WLV-RIT at SemEval-2021 Task 5: A Neural Transformer Framework for Detecting Toxic Spans
Tharindu Ranasinghe, Diptanu Sarkar, Marcos Zampieri and Alexander Ororbia . . . .833 YNU-HPCC at SemEval-2021 Task 5: Using a Transformer-based Model with Auxiliary Information for Toxic Span Detection
Ruijun Chen, Jin Wang and Xuejie Zhang . . . .841 UIT-ISE-NLP at SemEval-2021 Task 5: Toxic Spans Detection with BiLSTM-CRF and ToxicBERT Com- ment Classification
Son T. Luu and Ngan Nguyen . . . .846 GHOST at SemEval-2021 Task 5: Is explanation all you need?
Kamil Pluci´nski and Hanna Klimczak . . . .852 GoldenWind at SemEval-2021 Task 5: Orthrus - An Ensemble Approach to Identify Toxicity
Marco Palomino, Dawid Grad and James Bedwell . . . .860 LISAC FSDM USMBA at SemEval-2021 Task 5: Tackling Toxic Spans Detection Challenge with Super- vised SpanBERT-based Model and Unsupervised LIME-based Model
Abdessamad Benlahbib, Ahmed Alami and Hamza Alami . . . .865 HITMI&T at SemEval-2021 Task 5: Integrating Transformer and CRF for Toxic Spans Detection
Chenyi Wang, Tianshu Liu and Tiejun Zhao . . . .870 AStarTwice at SemEval-2021 Task 5: Toxic Span Detection Using RoBERTa-CRF, Domain Specific Pre- Training and Self-Training
Thakur Ashutosh Suman and Abhinav Jain . . . .875
xiv
NLP_UIOWA at Semeval-2021 Task 5: Transferring Toxic Sets to Tag Toxic Spans
Jonathan Rusert . . . .881 S-NLP at SemEval-2021 Task 5: An Analysis of Dual Networks for Sequence Tagging
Viet Anh Nguyen, Tam Minh Nguyen, Huy Quang Dao and Quang Huu Pham . . . .888 UAntwerp at SemEval-2021 Task 5: Spans are Spans, stacking a binary word level approach to toxic span detection
Ben Burtenshaw and Mike Kestemont . . . .898 hub at SemEval-2021 Task 5: Toxic Span Detection Based on Word-Level Classification
Bo Huang, Yang Bai and Xiaobing Zhou . . . .904 Sefamerve ARGE at SemEval-2021 Task 5: Toxic Spans Detection Using Segmentation Based 1-D Con- volutional Neural Network Model
Selman Delil, Birol Kuyumcu and Cüneyt Aksakallı . . . .909 MIPT-NSU-UTMN at SemEval-2021 Task 5: Ensembling Learning with Pre-trained Language Models for Toxic Spans Detection
Mikhail Kotyushev, Anna Glazkova and Dmitry Morozov . . . .913 UIT-E10dot3 at SemEval-2021 Task 5: Toxic Spans Detection with Named Entity Recognition and Question-Answering Approaches
Phu Gia Hoang, Luan Thanh Nguyen and Kiet Nguyen . . . .919 SkoltechNLP at SemEval-2021 Task 5: Leveraging Sentence-level Pre-training for Toxic Span Detection David Dale, Igor Markov, Varvara Logacheva, Olga Kozlova, Nikita Semenov and Alexander Panchenko . . . .927 Entity at SemEval-2021 Task 5: Weakly Supervised Token Labelling for Toxic Spans Detection
Vaibhav Jain and Mina Naghshnejad. . . .935 BennettNLP at SemEval-2021 Task 5: Toxic Spans Detection using Stacked Embedding Powered Toxic Entity Recognizer
Harsh Kataria, Ambuje Gupta and Vipul Mishra . . . .941 UoT-UWF-PartAI at SemEval-2021 Task 5: Self Attention Based Bi-GRU with Multi-Embedding Repre- sentation for Toxicity Highlighter
Hamed Babaei Giglou, Taher Rahgooy, Mostafa Rahgouy and Jafar Razmara . . . .948 YoungSheldon at SemEval-2021 Task 5: Fine-tuning Pre-trained Language Models for Toxic Spans De- tection using Token classification Objective
Mayukh Sharma, Ilanthenral Kandasamy and W.B. Vasantha . . . .953 HLE-UPC at SemEval-2021 Task 5: Multi-Depth DistilBERT for Toxic Spans Detection
Rafel Palliser-Sans and Albert Rial-Farràs. . . .960 Lone Pine at SemEval-2021 Task 5: Fine-Grained Detection of Hate Speech Using BERToxic
Yakoob Khan, Weicheng Ma and Soroush Vosoughi . . . .967 SRPOL DIALOGUE SYSTEMS at SemEval-2021 Task 5: Automatic Generation of Training Data for Toxic Spans Detection
Michał Satława, Katarzyna Zamły´nska, Jarosław Piersa, Joanna Kolis, Klaudia Firl ˛ag, Katarzyna Beksa, Zuzanna Bordzicka, Christian Goltz, Paweł Bujnowski and Piotr Andruszkiewicz . . . .974
SINAI at SemEval-2021 Task 5: Combining Embeddings in a BiLSTM-CRF model for Toxic Spans De- tection
Flor Miriam Plaza-del-Arco, Pilar López-Úbeda, L. Alfonso Ureña-López and M. Teresa Martín- Valdivia . . . .984 CSECU-DSG at SemEval-2021 Task 5: Leveraging Ensemble of Sequence Tagging Models for Toxic Spans Detection
Tashin Hossain, Jannatun Naim, Fareen Tasneem, Radiathun Tasnia and Abu Nowshed Chy . . .990 UTNLP at SemEval-2021 Task 5: A Comparative Analysis of Toxic Span Detection using Attention- based, Named Entity Recognition, and Ensemble Models
Alireza Salemi, Nazanin Sabri, Emad Kebriaei, Behnam Bahrak and Azadeh Shakery . . . .995 macech at SemEval-2021 Task 5: Toxic Spans Detection
Maggie Cech. . . .1003 LZ1904 at SemEval-2021 Task 5: Bi-LSTM-CRF for Toxic Span Detection using Pretrained Word Em- bedding
Liang Zou and Wen Li . . . .1009 LIIR at SemEval-2021 task 6: Detection of Persuasion Techniques In Texts and Images using CLIP features
Erfan Ghadery, Damien Sileo and Marie-Francine Moens. . . .1015 AIMH at SemEval-2021 Task 6: Multimodal Classification Using an Ensemble of Transformer Models
Nicola Messina, Fabrizio Falchi, Claudio Gennaro and Giuseppe Amato . . . .1020 HOMADOS at SemEval-2021 Task 6: Multi-Task Learning for Propaganda Detection
Konrad Kaczy´nski and Piotr Przybyła . . . .1027 1213Li at SemEval-2021 Task 6: Detection of Propaganda with Multi-modal Attention and Pre-trained Models
Peiguang Li, Xuan Li and Xian Sun . . . .1032 NLyticsFKIE at SemEval-2021 Task 6: Detection of Persuasion Techniques In Texts And Images
Albert Pritzkau . . . .1037 YNU-HPCC at SemEval-2021 Task 6: Combining ALBERT and Text-CNN for Persuasion Detection in Texts and Images
Xingyu Zhu, Jin Wang and Xuejie Zhang . . . .1045 LT3 at SemEval-2021 Task 6: Using Multi-Modal Compact Bilinear Pooling to Combine Visual and Textual Understanding in Memes
Pranaydeep Singh and Els Lefever . . . .1051 FPAI at SemEval-2021 Task 6: BERT-MRC for Propaganda Techniques Detection
Xiaolong Hou, Junsong Ren, Gang Rao, Lianxin Lian, Zhihao Ruan, Yang Mo and JIanping Shen 1056
NLPIITR at SemEval-2021 Task 6: RoBERTa Model with Data Augmentation for Persuasion Techniques Detection
Vansh Gupta and Raksha Sharma . . . .1061
xvi
LeCun at SemEval-2021 Task 6: Detecting Persuasion Techniques in Text Using Ensembled Pretrained Transformers and Data Augmentation
Dia Abujaber, Ahmed Qarqaz and Malak A. Abdullah. . . .1068 Volta at SemEval-2021 Task 6: Towards Detecting Persuasive Texts and Images using Textual and Mul- timodal Ensemble
Kshitij Gupta, Devansh Gautam and Radhika Mamidi . . . .1075 MinD at SemEval-2021 Task 6: Propaganda Detection using Transfer Learning and Multimodal Fusion Junfeng Tian, Min Gui, Chenliang Li, Ming Yan and Wenming Xiao. . . .1082 CSECU-DSG at SemEval-2021 Task 6: Orchestrating Multimodal Neural Architectures for Identifying Persuasion Techniques in Texts and Images
Tashin Hossain, Jannatun Naim, Fareen Tasneem, Radiathun Tasnia and Abu Nowshed Chy .1088 UMUTeam at SemEval-2021 Task 7: Detecting and Rating Humor and Offense with Linguistic Features and Word Embeddings
José Antonio García-Díaz and Rafael Valencia-García. . . .1096 ES-JUST at SemEval-2021 Task 7: Detecting and Rating Humor and Offensive Text Using Deep Learn- ing
Emran Al Bashabsheh and Sanaa Abu Alasal . . . .1102 Tsia at SemEval-2021 Task 7: Detecting and Rating Humor and Offense
Zhengyi Guan and Xiaobing ZXB Zhou . . . .1108 DLJUST at SemEval-2021 Task 7: Hahackathon: Linking Humor and Offense
Hani Al-Omari, Isra’a AbedulNabi and Rehab Duwairi . . . .1114 Gulu at SemEval-2021 Task 7: Detecting and Rating Humor and Offense
Maoqin Yang . . . .1120 DUTH at SemEval-2021 Task 7: Is Conventional Machine Learning for Humorous and Offensive Tasks enough in 2021?
Alexandros Karasakalidis, Dimitrios Effrosynidis and Avi Arampatzis . . . .1125 DeepBlueAI at SemEval-2021 Task 7: Detecting and Rating Humor and Offense with Stacking Diverse Language Model-Based Methods
Bingyan Song, Chunguang Pan, Shengguang Wang and Zhipeng Luo . . . .1130 CS-UM6P at SemEval-2021 Task 7: Deep Multi-Task Learning Model for Detecting and Rating Humor and Offense
Kabil Essefar, Abdellah El Mekki, Abdelkader El Mahdaouy, Nabil El Mamoun and Ismail Berrada 1135
hub at SemEval-2021 Task 7: Fusion of ALBERT and Word Frequency Information Detecting and Rating Humor and Offense
Bo Huang and Yang Bai . . . .1141 YoungSheldon at SemEval-2021 Task 7: Fine-tuning Is All You Need
Mayukh Sharma, Ilanthenral Kandasamy and W.B. Vasantha. . . .1146 MagicPai at SemEval-2021 Task 7: Method for Detecting and Rating Humor Based on Multi-Task Ad- versarial Training
Jian Ma, Shuyi Xie, Haiqin Yang, Lianxin Jiang, Mengyuan Zhou, Xiaoyi Ruan and Yang Mo1153
UPB at SemEval-2021 Task 7: Adversarial Multi-Task Learning for Detecting and Rating Humor and Offense
R˘azvan-Alexandru Sm˘adu, Dumitru-Clementin Cercel and Mihai Dascalu . . . .1160 Team_KGP at SemEval-2021 Task 7: A Deep Neural System to Detect Humor and Offense with Their Ratings in the Text Data
Anik Mondal and Raksha Sharma . . . .1169 ZYJ at SemEval-2021 Task 7: HaHackathon: Detecting and Rating Humor and Offense with ALBERT- Based Model
Yingjia Zhao and Xin Tao . . . .1175 UoR at SemEval-2021 Task 7: Utilizing Pre-trained DistilBERT Model and Multi-scale CNN for Humor Detection
Zehao Liu, Carl Haines and Huizhi Liang . . . .1179 TECHSSN at SemEval-2021 Task 7: Humor and Offense detection and classification using ColBERT embeddings
Rajalakshmi Sivanaiah, Angel Deborah S, S Milton Rajendram, Mirnalinee TT, Abrit Pal Singh, Aviansh Gupta and Ayush Nanda . . . .1185 Amherst685 at SemEval-2021 Task 7: Joint Modeling of Classification and Regression for Humor and Offense
Brian Zylich, Akshay Gugnani, Gabriel Brookman and Nicholas Samoray . . . .1190 DuluthNLP at SemEval-2021 Task 7: Fine-Tuning RoBERTa Model for Humor Detection and Offense Rating
Samuel Akrah . . . .1196 CSECU-DSG at SemEval-2021 Task 7: Detecting and Rating Humor and Offense Employing Transform- ers
Afrin Sultana, Nabila Ayman and Abu Nowshed Chy . . . .1204 RedwoodNLP at SemEval-2021 Task 7: Ensembled Pretrained and Lightweight Models for Humor De- tection
Nathan Chi and Ryan Chi . . . .1209 EndTimes at SemEval-2021 Task 7: Detecting and Rating Humor and Offense with BERT and Ensembles Chandan Kumar Pandey, Chirag Singh and Karan Mangla . . . .1215 IIITH at SemEval-2021 Task 7: Leveraging transformer-based humourous and offensive text detection architectures using lexical and hurtlex features and task adaptive pretraining
Tathagata Raha, Ishan Sanjeev Upadhyay, Radhika Mamidi and Vasudeva Varma . . . .1221 FII FUNNY at SemEval-2021 Task 7: HaHackathon: Detecting and rating Humor and Offense
Mihai Samson and Daniela Gifu . . . .1226 Counts@IITK at SemEval-2021 Task 8: SciBERT Based Entity And Semantic Relation Extraction For Scientific Data
Akash Gangwar, Sabhay Jain, Shubham Sourav and Ashutosh Modi . . . .1232 CONNER: A Cascade Count and Measurement Extraction Tool for Scientific Discourse
Jiarun Cao, Yuejia Xiang, Yunyan Zhang, Zhiyuan Qi, Xi Chen and Yefeng Zheng . . . .1239
xviii
Stanford MLab at SemEval-2021 Task 8: 48 Hours Is All You Need
Patrick Liu, Niveditha Iyer, Erik Rozi and Ethan A. Chi . . . .1245 LIORI at SemEval-2021 Task 8: Ask Transformer for measurements
Adis Davletov, Denis Gordeev, Nikolay Arefyev and Emil Davletov . . . .1249 Sattiy at SemEval-2021 Task 9: An Ensemble Solution for Statement Verification and Evidence Finding with Tables
Xiaoyi Ruan, Meizhi Jin, Jian Ma, Haiqin Yang, Lianxin Jiang, Yang Mo and Mengyuan Zhou1255 Volta at SemEval-2021 Task 9: Statement Verification and Evidence Finding with Tables using TAPAS and Transfer Learning
Devansh Gautam, Kshitij Gupta and Manish Shrivastava . . . .1262 KaushikAcharya at SemEval-2021 Task 9: Candidate Generation for Fact Verification over Tables
Kaushik Acharya . . . .1271 AttesTable at SemEval-2021 Task 9: Extending Statement Verification with Tables for Unknown Class, and Semantic Evidence Finding
Harshit Varma, Aadish Jain, Pratik Ratadiya and Abhishek Rathi . . . .1276 MedAI at SemEval-2021 Task 10: Negation-aware Pre-training for Source-free Negation Detection Do- main Adaptation
Jinquan Sun, Qi Zhang, Yu Wang and Lei Zhang . . . .1283 YNU-HPCC at SemEval-2021 Task 10: Using a Transformer-based Source-Free Domain Adaptation Model for Semantic Processing
Zhewen Yu, Jin Wang and Xuejie Zhang . . . .1289 ECNUICA at SemEval-2021 Task 11: Rule based Information Extraction Pipeline
Jiaju Lin, Jing Ling, Zhiwei Wang, Jiawei Liu, Qin Chen and Liang He . . . .1295 UOR at SemEval-2021 Task 12: On Crowd Annotations; Learning with Disagreements to optimise crowd truth
Emmanuel Osei-Brefo, Thanet Markchom and Huizhi Liang . . . .1303
Conference Program
All times are UTC.
5 August 2021
14:00–15:00 Invited Talk
Seven Social Factors in Natural Language Processing: Theory and Practice Diyi Yang
15:00–15:25 Plenary session: Tasks 1, 2, 4
SemEval-2021 Task 1: Lexical Complexity Prediction
Matthew Shardlow, Richard Evans, Gustavo Henrique Paetzold and Marcos Zampieri
OCHADAI-KYOTO at SemEval-2021 Task 1: Enhancing Model Generalization and Robustness for Lexical Complexity Prediction
Yuki Taya, Lis Kanashiro Pereira, Fei Cheng and Ichiro Kobayashi
SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disam- biguation (MCL-WiC)
Federico Martelli, Najla Kalach, Gabriele Tola and Roberto Navigli SemEval-2021 Task 4: Reading Comprehension of Abstract Meaning
Boyuan Zheng, Xiaoyu Yang, Yu-Ping Ruan, Zhenhua Ling, Quan Liu, Si Wei and Xiaodan Zhu
TA-MAMC at SemEval-2021 Task 4: Task-adaptive Pretraining and Multi-head At- tention for Abstract Meaning Reading Comprehension
Jing Zhang, Yimeng Zhuang and Yinpei Su
5 August 2021 (continued)
15:25–15:50 Plenary session: Tasks 5, 6, 7
SemEval-2021 Task 5: Toxic Spans Detection
John Pavlopoulos, Jeffrey Sorensen, Léo Laugier and Ion Androutsopoulos SemEval-2021 Task 6: Detection of Persuasion Techniques in Texts and Images Dimitar Dimitrov, Bishr Bin Ali, Shaden Shaar, Firoj Alam, Fabrizio Silvestri, Hamed Firooz, Preslav Nakov and Giovanni Da San Martino
Alpha at SemEval-2021 Task 6: Transformer Based Propaganda Classification Zhida Feng, Jiji Tang, Jiaxiang Liu, Weichong Yin, Shikun Feng, Yu Sun and Li Chen
SemEval 2021 Task 7: HaHackathon, Detecting and Rating Humor and Offense J. A. Meaney, Steven Wilson, Luis Chiruzzo, Adam Lopez and Walid Magdy
15:50–16:00 Announcement of Best Paper Awards & General Discussion
16:30–17:30 Poster session: Tasks 1, 2, 4
+ This poster session will also be held at 02:00–03:00 and at 11:30–12:30.
LangResearchLab NC at SemEval-2021 Task 1: Linguistic Feature Based Mod- elling for Lexical Complexity
Raksha Agarwal and Niladri Chatterjee
Complex words identification using word-level features for SemEval-2020 Task 1 Jenny A. Ortiz-Zambrano and Arturo Montejo-Ráez
TUDA-CCL at SemEval-2021 Task 1: Using Gradient-boosted Regression Tree En- sembles Trained on a Heterogeneous Feature Set for Predicting Lexical Complexity Sebastian Gombert and Sabine Bartsch
JCT at SemEval-2021 Task 1: Context-aware Representation for Lexical Complexity Prediction
Chaya Liebeskind, Otniel Elkayam and Shmuel Liebeskind
xxii
5 August 2021 (continued)
IAPUCP at SemEval-2021 Task 1: Stacking Fine-Tuned Transformers is Almost All You Need for Lexical Complexity Prediction
Kervy Rivas Rojas and Fernando Alva-Manchego
Uppsala NLP at SemEval-2021 Task 2: Multilingual Language Models for Fine- tuning and Feature Extraction in Word-in-Context Disambiguation
Huiling You, Xingran Zhu and Sara Stymne
SkoltechNLP at SemEval-2021 Task 2: Generating Cross-Lingual Training Data for the Word-in-Context Task
Anton Razzhigaev, Nikolay Arefyev and Alexander Panchenko
Zhestyatsky at SemEval-2021 Task 2: ReLU over Cosine Similarity for BERT Fine- tuning
Boris Zhestiankin and Maria Ponomareva
SzegedAI at SemEval-2021 Task 2: Zero-shot Approach for Multilingual and Cross- lingual Word-in-Context Disambiguation
Gábor Berend
ReCAM@IITK at SemEval-2021 Task 4: BERT and ALBERT based Ensemble for Abstract Word Prediction
Abhishek Mittal and Ashutosh Modi
ECNU_ICA_1 SemEval-2021 Task 4: Leveraging Knowledge-enhanced Graph At- tention Networks for Reading Comprehension of Abstract Meaning
Pingsheng Liu, Linlin Wang, Qian Zhao, Hao Chen, Yuxi Feng, Xin Lin and liang he
LRG at SemEval-2021 Task 4: Improving Reading Comprehension with Abstract Words using Augmentation, Linguistic Features and Voting
Abheesht Sharma, Harshit Pandey, Gunjan Chhablani, Yash Bhartia and Tirtharaj Dash
IIE-NLP-Eyas at SemEval-2021 Task 4: Enhancing PLM for ReCAM with Special Tokens, Re-Ranking, Siamese Encoders and Back Translation
Yuqiang Xie, Luxi Xing, Wei Peng and Yue Hu
NLP-IIS@UT at SemEval-2021 Task 4: Machine Reading Comprehension using the Long Document Transformer
Hossein Basafa, Sajad Movahedi, Ali Ebrahimi, Azadeh Shakery and Heshaam Faili
5 August 2021 (continued)
17:30–18:30 Poster session: Tasks 5, 6, 7
+ This poster session will also be held at 03:00–04:00 and at 12:30–13:30.
IITK@Detox at SemEval-2021 Task 5: Semi-Supervised Learning and Dice Loss for Toxic Spans Detection
Archit Bansal, Abhay Kaushik and Ashutosh Modi
UniParma at SemEval-2021 Task 5: Toxic Spans Detection Using CharacterBERT and Bag-of-Words Model
Akbar Karimi, Leonardo Rossi and Andrea Prati
UPB at SemEval-2021 Task 5: Virtual Adversarial Training for Toxic Spans Detec- tion
Andrei Paraschiv, Dumitru-Clementin Cercel and Mihai Dascalu
NLRG at SemEval-2021 Task 5: Toxic Spans Detection Leveraging BERT-based Token Classification and Span Prediction Techniques
Gunjan Chhablani, Abheesht Sharma, Harshit Pandey, Yash Bhartia and Shan Suthaharan
UoB at SemEval-2021 Task 5: Extending Pre-Trained Language Models to Include Task and Domain-Specific Information for Toxic Span Prediction
Erik Yan and Harish Tayyar Madabushi
Cisco at SemEval-2021 Task 5: What’s Toxic?: Leveraging Transformers for Mul- tiple Toxic Span Extraction from Online Comments
Sreyan Ghosh and Sonal Kumar
MedAI at SemEval-2021 Task 5: Start-to-end Tagging Framework for Toxic Spans Detection
Zhen Wang, Hongjie Fan and Junfei Liu
HamiltonDinggg at SemEval-2021 Task 5: Investigating Toxic Span Detection using RoBERTa Pre-training
Huiyang Ding and David Jurgens
WVOQ at SemEval-2021 Task 6: BART for Span Detection and Classification Cees Roele
HumorHunter at SemEval-2021 Task 7: Humor and Offense Recognition with Dis- entangled Attention
Yubo Xie, Junze Li and Pearl Pu
xxiv
5 August 2021 (continued)
Grenzlinie at SemEval-2021 Task 7: Detecting and Rating Humor and Offense Renyuan Liu and Xiaobing Zhou
abcbpc at SemEval-2021 Task 7: ERNIE-based Multi-task Model for Detecting and Rating Humor and Offense
Chao Pang, Xiaoran Fan, Weiyue Su, Xuyi Chen, Shuohuan Wang, Jiaxiang Liu, Xuan Ouyang, Shikun Feng and Yu Sun
Humor@IITK at SemEval-2021 Task 7: Large Language Models for Quantifying Humor and Offensiveness
Aishwarya Gupta, Avik Pal, Bholeshwar Khurana, Lakshay Tyagi and Ashutosh Modi
RoMa at SemEval-2021 Task 7: A Transformer-based Approach for Detecting and Rating Humor and Offense
Roberto Labadie, Mariano Jason Rodriguez, Reynier Ortega and Paolo Rosso
6 August 2021
14:00–15:00 Invited Talk
Predictability and Informativity in Communication Hannah Rohde
15:00–15:25 Plenary session: Tasks 8, 9, 12
SemEval-2021 Task 8: MeasEval – Extracting Counts and Measurements and their Related Contexts
Corey Harper, Jessica Cox, Curt Kohler, Antony Scerri, Ron Daniel Jr. and Paul Groth
SemEval-2021 Task 9: Fact Verification and Evidence Finding for Tabular Data in Scientific Documents (SEM-TAB-FACTS)
Nancy X. R. Wang, Diwakar Mahajan, Marina Danilevsky and Sara Rosenthal BreakingBERT@IITK at SemEval-2021 Task 9: Statement Verification and Evi- dence Finding with Tables
Aditya Jindal, Ankur Gupta, Jaya Srivastava, Preeti Menghwani, Vijit Malik, Vishesh Kaushik and Ashutosh Modi
SemEval-2021 Task 12: Learning with Disagreements
Alexandra Uma, Tommaso Fornaciari, Anca Dumitrache, Tristan Miller, Jon Cham- berlain, Barbara Plank, Edwin Simpson and Massimo Poesio
6 August 2021 (continued)
15:25–15:50 Plenary session: Tasks 10, 11
SemEval-2021 Task 10: Source-Free Domain Adaptation for Semantic Processing Egoitz Laparra, Xin Su, Yiyun Zhao, Özlem Uzuner, Timothy Miller and Steven Bethard
BLCUFIGHT at SemEval-2021 Task 10: Novel Unsupervised Frameworks For Source-Free Domain Adaptation
Weikang Wang, Yi Wu, Yixiang Liu and Pengyuan Liu
SemEval-2021 Task 11: NLPContributionGraph - Structuring Scholarly NLP Con- tributions for a Research Knowledge Graph
Jennifer D’Souza, Sören Auer and Ted Pedersen
UIUC_BioNLP at SemEval-2021 Task 11: A Cascade of Neural Models for Struc- turing Scholarly NLP Contributions
Haoyang Liu, M. Janina Sarol and Halil Kilicoglu
15:50–16:00 Announcement of SemEval-2022 Tasks & Closing Remarks
16:30–17:30 Poster session: Tasks 8, 9, 12
+ This poster session will also be held at 02:00–03:00 and at 11:30–12:30.
KGP at SemEval-2021 Task 8: Leveraging Multi-Staged Language Models for Ex- tracting Measurements, their Attributes and Relations
Neel Karia, Ayush Kaushal and Faraaz Mallick
DPR at SemEval-2021 Task 8: Dynamic Path Reasoning for Measurement Relation Extraction
Amir Pouran Ben Veyseh, Franck Dernoncourt and Thien Huu Nguyen CLaC-np at SemEval-2021 Task 8: Dependency DGCNN
Nihatha Lathiff, Pavel PK Khloponin and Sabine Bergler
CLaC-BP at SemEval-2021 Task 8: SciBERT Plus Rules for MeasEval Benjamin Therien, Parsa Bagherzadeh and Sabine Bergler
xxvi
6 August 2021 (continued)
THiFly_Queens at SemEval-2021 Task 9: Two-stage Statement Verification with Adaptive Ensembling and Slot-based Operation
Yuxuan Zhou, Kaiyin Zhou, Xien Liu, Ji Wu and Xiaodan Zhu
TAPAS at SemEval-2021 Task 9: Reasoning over tables with intermediate pre- training
Thomas Müller, Julian Eisenschlos and Syrine Krichene
BOUN at SemEval-2021 Task 9: Text Augmentation Techniques for Fact Verification in Tabular Data
Abdullatif Köksal, Yusuf Yüksel, Bekir Yıldırım and Arzucan Özgür
17:30–18:30 Poster session: Tasks 10, 11
+ This poster session will also be held at 03:00–04:00 and at 12:30–13:30.
IITK at SemEval-2021 Task 10: Source-Free Unsupervised Domain Adaptation us- ing Class Prototypes
Harshit Kumar, Jinang Shah, Nidhi Hegde, Priyanshu Gupta, Vaibhav Jindal and Ashutosh Modi
PTST-UoM at SemEval-2021 Task 10: Parsimonious Transfer for Sequence Tagging Kemal Kurniawan, Lea Frermann, Philip Schulz and Trevor Cohn
Self-Adapter at SemEval-2021 Task 10: Entropy-based Pseudo-Labeler for Source- free Domain Adaptation
Sangwon Yoon, Yanghoon Kim and Kyomin Jung
The University of Arizona at SemEval-2021 Task 10: Applying Self-training, Active Learning and Data Augmentation to Source-free Domain Adaptation
Xin Su, Yiyun Zhao and Steven Bethard
KnowGraph@IITK at SemEval-2021 Task 11: Building Knowledge Graph for NLP Research
Shashank Shailabh, Sajal Chaurasia and Ashutosh Modi
YNU-HPCC at SemEval-2021 Task 11: Using a BERT Model to Extract Contribu- tions from NLP Scholarly Articles
Xinge Ma, Jin Wang and Xuejie Zhang
ITNLP at SemEval-2021 Task 11: Boosting BERT with Sampling and Adversarial Training for Knowledge Extraction
Genyu Zhang, Yu Su, Changhong He, Lei Lin, Chengjie Sun and Lili Shan
6 August 2021 (continued)
Duluth at SemEval-2021 Task 11: Applying DeBERTa to Contributing Sentence Selection and Dependency Parsing for Entity Extraction
Anna Martin and Ted Pedersen
INNOVATORS at SemEval-2021 Task-11: A Dependency Parsing and BERT-based model for Extracting Contribution Knowledge from Scientific Papers
Hardik Arora, Tirthankar Ghosal, Sandeep Kumar, Suraj Patwal and Phil Gooch
xxviii
Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), pages 1–16
SemEval-2021 Task 1: Lexical Complexity Prediction
Matthew Shardlow1, Richard Evans2, Gustavo Henrique Paetzold3, Marcos Zampieri4
1Manchester Metropolitan University, UK
2University of Wolverhampton, UK
3Universidade Tecnol´ogica Federal do Paran´a, Brazil
4Rochester Institute of Technology USA m.shardlow@mmu.ac.uk
Abstract
This paper presents the results and main find- ings of SemEval-2021 Task 1 - Lexical Com- plexity Prediction. We provided participants with an augmented version of the CompLex Corpus (Shardlow et al., 2020). CompLex is an English multi-domain corpus in which words and multi-word expressions (MWEs) were annotated with respect to their complex- ity using a five point Likert scale. SemEval- 2021 Task 1 featured two Sub-tasks: Sub-task 1 focused on single words and Sub-task 2 fo- cused on MWEs. The competition attracted 198 teams in total, of which 54 teams submit- ted official runs on the test data to Sub-task 1 and 37 to Sub-task 2.
1 Introduction
The occurrence of an unknown word in a sentence can adversely affect its comprehension by read- ers. Either they give up, misinterpret, or plough on without understanding. A committed reader may take the time to look up a word and expand their vocabulary, but even in this case they must leave the text, undermining their concentration. The nat- ural language processing solution is to identify can- didate words in a text that may be too difficult for a reader (Shardlow,2013;Paetzold and Specia, 2016a). Each potential word is assigned a judgment by a system to determine if it was deemed ‘com- plex’ or not. These scores indicate which words are likely to cause problems for a reader. The words that are identified as problematic can be the subject of numerous types of intervention, such as direct replacement in the setting of lexical simplification (Gooding and Kochmar,2019), or extra informa- tion being given in the context of explanation gen- eration (Rello et al.,2015).
Whereas previous solutions to this task have typ- ically considered the Complex Word Identification (CWI) task (Paetzold and Specia,2016a;Yimam et al.,2018) in which a binary judgment of a word’s
complexity is given (i.e., is a word complex or not?), we instead focus on the Lexical Complexity Prediction (LCP) task (Shardlow et al.,2020) in which a value is assigned from a continuous scale to identify a word’s complexity (i.e., how complex is this word?). We ask multiple annotators to give a judgment on each instance in our corpus and take the average prediction as our complexity label. The former task (CWI) forces each user to make a sub- jective judgment about the nature of the word that models their personal vocabulary. Many factors may affect the annotator’s judgment including their education level, first language, specialism or famil- iarity with the text at hand. The annotators may also disagree on the level of difficulty at which to label a word as complex. One annotator may label every word they feel is above average difficulty, another may label words that they feel unfamiliar with, but understand from the context, whereas an- other annotator may only label those words that they find totally incomprehensible, even in context.
Our introduction of the LCP task seeks to address this annotator confusion by giving annotators a Likert scale to provide their judgments. Whilst annotators must still give a subjective judgment depending on their own understanding, familiarity and vocabulary — they do so in a way that better captures the meaning behind each judgment they have given. By aggregating these judgments we have developed a dataset that contains continuous labels in the range of 0–1 for each instance. This means that rather than a system predicting whether a word is complex or not (0 or 1), instead a system must now predict where, on our continuous scale, a word falls (0–1).
Consider the following sentence taken from a biomedical source, where the target word ‘observa- tion’ has been highlighted:
(1) Theobservationof unequal expression leads to a number of questions.
1
In the binary annotation setting of CWI some anno- tators may rightly consider this term non-complex, whereas others may rightly consider it to be com- plex. Whilst the meaning of the word is reasonably clear to someone with scientific training, the con- text in which it is used is unfamiliar for a lay reader and will likely lead to them considering it com- plex. In our new LCP setting, we are able to ask annotators to mark the word on a scale from very easy to very difficult. Each user can give their sub- jective interpretation on this scale indicating how difficult they found the word. Whilst annotators will inevitably disagree (some finding it more or less difficult), this is captured and quantified as part of our annotations, with a word of this type likely to lead to a medium complexity value.
LCP is useful as part of the wider task of lexi- cal simplification (Devlin and Tait,1998), where it can be used to both identify candidate words for simplification (Shardlow, 2013) and rank poten- tial words as replacements (Paetzold and Specia, 2017). LCP is also relevant to the field of readabil- ity assessment, where knowing the proportion of complex words in a text helps to identify the overall complexity of the text (Dale and Chall.,1948).
This paper presents SemEval-2021 Task 1: Lex- ical Complexity Prediction. In this task we devel- oped a new dataset for complexity prediction based on the previously published CompLex dataset. Our dataset covers 10,800 instances spanning 3 genres and containing unigrams and bigrams as targets for complexity prediction. We solicited participants in our task and released a trial, training and test split in accordance with the SemEval schedule. We accepted submissions in two separate Sub-tasks, the first being single words only and the second taking single words and multi-word expressions (modelled by our bigrams). In total 55 teams par- ticipated across the two Sub-tasks.
The rest of this paper is structured as folllows:
In Section2we discuss the previous two iterations of the CWI task. In Section 3, we present the CompLex 2.0 dataset that we have used for our task, including the methodology we used to produce trial, test and training splits. In Section5, we show the results of the participating systems and compare the features that were used by each system. We finally discuss the nature of LCP in Section7and give concluding remarks in Section8
2 Related Tasks
CWI 2016 at SemEval The CWI shared task was organized at SemEval 2016 (Paetzold and Spe- cia,2016a). The CWI 2016 organizers introduced a new CWI dataset and reported the results of 42 CWI systems developed by 21 teams. Words in their dataset were considered complex if they were difficult to understand for non-native English speak- ers according to a binary labelling protocol. A word was considered complex if at least one of the anno- tators found it to be difficult. The training dataset consisted of 2,237 instances, each labelled by 20 annotators and the test dataset had 88,221 instances, each labelled by 1 annotator (Paetzold and Specia, 2016a).
The participating systems leveraged lexical fea- tures (Choubey and Pateria, 2016;Bingel et al., 2016;Quijada and Medero,2016) and word em- beddings (Kuru, 2016; S.P et al., 2016; Gillin, 2016), as well as finding that frequency features, such as those taken from Wikipedia (Konkol,2016;
Wr´obel,2016) were useful. Systems used binary classifiers such as SVMs (Kuru,2016;S.P et al., 2016;Choubey and Pateria,2016), Decision Trees (Choubey and Pateria,2016;Quijada and Medero, 2016;Malmasi et al.,2016), Random Forests (Ron- zano et al., 2016;Brooke et al., 2016;Zampieri et al.,2016;Mukherjee et al.,2016) and threshold- based metrics (Kauchak,2016;Wr´obel,2016) to predict the complexity labels. The winning system made use of threshold-based methods and features extracted from Simple Wikipedia (Paetzold and Specia,2016b).
A post-competition analysis (Zampieri et al., 2017) with oracle and ensemble methods showed that most systems performed poorly due mostly to the way in which the data was annotated and the the small size of the training dataset.
CWI 2018 at BEA The second CWI Shared Task was organized at the BEA workshop 2018 (Yimam et al.,2018). Unlike the first task, this second task had two objectives. The first objective was the binary complex or non-complex classification of target words. The second objective was regression or probabilistic classification in which 13 teams were asked to assign the probability of a target word being considered complex by a set of language learners. A major difference in this second task was that datasets of differing genres: (TEXT GENRES) as well as English, German and Spanish datasets 2
for monolingual speakers and a French dataset for multilingual speakers were provided (Yimam et al., 2018).
Similar to 2016, systems made use of a variety of lexical features including word length (Wani et al.,2018;De Hertog and Tack,2018;AbuRa’ed and Saggion, 2018; Hartmann and dos Santos, 2018; Alfter and Pil´an, 2018; Kajiwara and Ko- machi, 2018), frequency (De Hertog and Tack, 2018;Aroyehun et al.,2018;Alfter and Pil´an,2018;
Kajiwara and Komachi, 2018), N-gram features (Gooding and Kochmar,2018;Popovi´c,2018;Hart- mann and dos Santos,2018;Alfter and Pil´an,2018;
Butnaru and Ionescu,2018) and word embeddings (De Hertog and Tack, 2018;AbuRa’ed and Sag- gion, 2018;Aroyehun et al., 2018; Butnaru and Ionescu,2018). A variety of classifiers were used ranging from traditional machine learning classi- fiers (Gooding and Kochmar,2018;Popovi´c,2018;
AbuRa’ed and Saggion,2018), to Neural Networks (De Hertog and Tack,2018;Aroyehun et al.,2018).
The winning system made use of Adaboost with WordNet features, POS tags, dependency parsing relations and psycholinguistic features (Gooding and Kochmar,2018).
3 Data
We previously reported on the annotation of the CompLex dataset (Shardlow et al.,2020) (hereafter referred to as CompLex 1.0), in which we anno- tated around 10,000 instances for lexical complex- ity using the Figure Eight platform. The instances spanned three genres: Europarl, taken from the proceedings of the European Parliament (Koehn, 2005); The Bible, taken from an electronic dis- tribution of the World English Bible translation (Christodouloupoulos and Steedman, 2015) and Biomedicalliterature, taken from the CRAFT cor- pus (Bada et al.,2012). We limited our annotations to focus only on nouns and multi-word expressions following a Noun-Noun or Adjective-Noun pat- tern, using the POS tagger from Stanford CoreNLP (Manning et al.,2014) to identify these patterns.
Whilst these annotations allowed us to report on the dataset and to show some trends, the overall quality of the annotations we received was poor and we ended up discarding a large number of the annotations. For CompLex 1.0 we retained only instances with four or more annotations and the low number of annotations (average number of annotators = 7) led to the overall dataset being less
reliable than initially expected
For the Shared Task we chose to boost the num- ber of annotations on the same data as used for CompLex 1.0 using Amazon’s Mechanical Turk platform. We requested a further 10 annotations on each data instance bringing up the average num- ber of annotators per instance. Annotators were presented with the same task layout as in the anno- tation of CompLex 1.0 and we defined the Likert Scale points as previously:
Very Easy: Words which were very familiar to an annotator.
Easy: Words with which an annotator was aware of the meaning.
Neutral: A word which was neither difficult nor easy.
Difficult: Words which an annotator was unclear of the meaning, but may have been able to infer the meaning from the sentence.
Very Difficult: Words that an annotator had never seen before, or were very unclear.
These annotations were aggregated with the re- tained annotations of CompLex 1.0 to give our new dataset, CompLex 2.0, covering 10,800 instances across single and multi-words and across 3 genres.
The features that make our corpus distinct from other corpora which focus on the CWI and LCP tasks are described below:
Continuous Annotations: We have annotated our data using a 5-point Likert Scale. Each in- stance has been annotated multiple times and we have taken the mean average of these anno- tations as the label for each data instance. To calculate this average we converted the Likert Scale points to a continuous scale as follows:
Very Easy→0, Easy→0.25, Neutral→0.5, Difficult→0.75, Very Difficult→1.0.
Contextual Annotations: Each instance in the corpus is presented with its enclosing sentence as context. This ensures that the sense of a word can be identified when assigning it a complexity value. Whereas previous work has reannotated the data from the CWI–2018 shared task with word senses (Strohmaier et al.,2020), we do not make explicit sense distinctions between our tokens, instead leav- ing this task up to participants.
Repeated Token Instances: We provide more than one context for each token (up to a maxi- mum of five contexts per genre). These words were annotated separately during annotation, with the expectation that tokens in different contexts would receive differing complexity values. This deliberately penalises systems that do not take the context of a word into account.
Multi-word Expressions: In our corpus we have provided 1,800 instances of multi-word ex- pressions (split across our 3 sub-corpora).
Each MWE is modelled as a Noun-Noun or Adjective-Noun pattern followed by any POS tag which is not a noun. This avoids select- ing the first portion of complex noun phrases.
There is no guarantee that these will corre- spond to true MWEs that take on a meaning beyond the sum of their parts, and further in- vestigation into the types of MWEs present in the corpus would be informative.
Aggregated Annotations: By aggregating the Likert scale labels we have generated crowd- sourced complexity labels for each instance in our corpus. We are assuming that, although there is inevitably some noise in any large an- notation project (and especially so in crowd- sourcing), this will even out in the averaging process to give a mean value reflecting the appropriate complexity for each instance. By taking the mean average we are assuming uni- modal distributions in our annotations.
Varied Genres: We have selected for diverse gen- res as mentioned above. Previous CWI datasets have focused on informal text such as Wikipedia and multi-genre text, such as news.
By focusing on specific texts we force systems to learn generalised complexity annotations that are appropriate in a cross-genre setting.
We have presented summary statistics for Com- pLex 2.0 in Table1. In total, 5,617 unique words are split across 10,800 contexts, with an average complexity across our entire dataset of 0.321. Each genre has 3,600 contexts, with each split between 3,000 single words and 600 multi-word expres- sions. Whereas single words are slightly below the average complexity of the dataset at 0.302, multi- word expressions are much more complex at 0.419,
indicating that annotators found these more dif- ficult to understand. Similarly Europarl and the Bible were less complex than the corpus average, whereas the Biomedical articles were more com- plex. The number of unique tokens varies from one genre to another as the tokens were selected at random and discarded if there were already more than 5 occurrences of the given token already in the dataset. This stochastic selection process led to a varied dataset with some tokens only having one context, whereas others have as many as five in a given genre. On average each token has around 2 contexts.
4 Data Splits
In order to run the shared task we partitioned our dataset into Trial, Train and Test splits and dis- tributed these according to the SemEval schedule.
A criticism of previous CWI shared tasks is that the training data did not accurately reflect the dis- tribution of instances in the testing data. We sought to avoid this by stratifying our selection process for a number of factors. The first factor we consid- ered was genre. We ensured that an even number of instances from each genre was present in each split. We also stratified for complexity, ensuring that each split had a similar distribution of com- plexities. Finally we also stratified the splits by token, ensuring that multiple instances containing the same token occurred in only one split. This last criterion ensures that systems do not overfit to the test data by learning the complexities of specific tokens in the training data.
Performing a robust stratification of a dataset according to multiple features is a non-trivial op- timisation problem. We solved this by first group- ing all instances in a genre by token and sorting these groups by the complexity of the least com- plex instance in the group. For each genre, we passed through this sorted list and for each set of 20 groups we put the first group in the trial set, the next two groups in the test set and the remaining 17 groups in the training data. This allowed us to get a rough 5-85-10 split between trial, training and test data. The trial and training data were released in this ordered format, however to prevent systems from guessing the labels based on the data ordering we randomised the order of the instances in the test data prior to release. The splits that we used for the Shared Task are available via GitHub1.
1https://github.com/MMU-TDMLab/CompLex
4
Subset Genre Contexts Unique Tokens Average Complexity All
Total 10,800 5,617 0.321
Europarl 3,600 2,227 0.303
Biomed 3,600 1,904 0.353
Bible 3,600 1,934 0.307
Single
Total 9,000 4,129 0.302
Europarl 3,000 1,725 0.286
Biomed 3,000 1,388 0.325
Bible 3,000 1,462 0.293
MWE
Total 1,800 1,488 0.419
Europarl 600 502 0.388
Biomed 600 516 0.491
Bible 600 472 0.377
Table 1: The statistics for CompLex 2.0.
Table2 presents statistics on each split in our data, where it can be seen that we were able to achieve a roughly even split between genres across the trial, train and test data.
Subset Genre Trial Train Test All
Total 520 9179 1101 Europarl 180 3010 410 Biomed 168 3090 342 Bible 172 3079 349 Single
Total 421 7662 917 Europarl 143 2512 345 Biomed 135 2576 289 Bible 143 2574 283 MWE
Total 99 1517 184 Europarl 37 498 65
Biomed 33 514 53
Bible 29 505 66
Table 2: The Trial, Train and Test splits that were used as part of the shared task.
5 Results
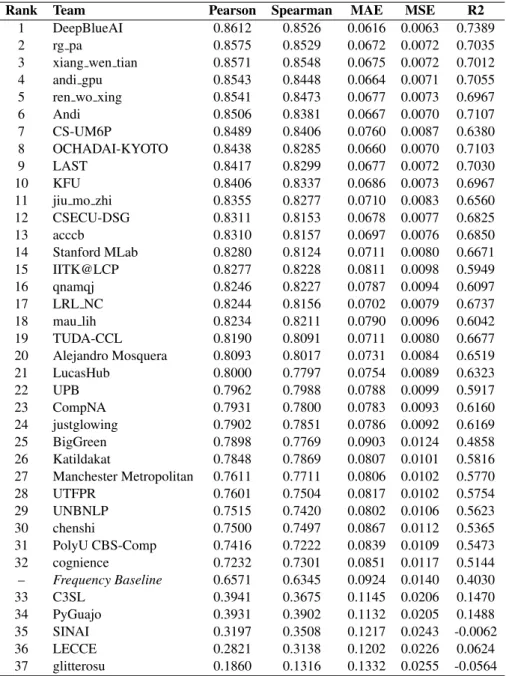
The full results of our task can be seen in Ap- pendix A. We had 55 teams participate in our 2 Sub-tasks, with 19 participating in Sub-task 1 only, 1 participating in Sub-task 2 only and 36 partici- pating in both Sub-tasks. We have used Pearson’s correlation for our final ranking of participants, but we have also included other metrics that are appro- priate for evaluating continuous and ranked data and provided secondary rankings of these.
Sub-task 1 asked participants to assign complex- ity values to each of the single words instances in our corpus. For Sub-task 2, we asked participants to submit results on both single words and MWEs.
We did not rank participants on MWE-only submis-
sions due to the relatively small number of MWEs in our corpus (184 in the test set).
The metrics we chose for ranking were as fol- lows:
Pearson’s Correlation: We chose this metric as our primary method of ranking as it is well known and understood, especially in the con- text of evaluating systems with continuous outputs. Pearson’s correlation is robust to changes in scale and measures how the input variables change with each other.
Spearman’s Rank: This metric does not consider the values output by a system, or in the test labels, only the order of those labels. It was chosen as a secondary metric as it is more robust to outliers than Pearson’s correlation.
Mean Absolute Error (MAE): Typically used for the evaluation of regression tasks, we included MAE as it gives an indication of how close the predicted labels were to the gold labels for our task.
Mean Squared Error (MSE): There is little dif- ference in the calculation of MSE vs. MAE, however we also include this metric for com- pleteness.
R2: This measures the proportion of variance of the original labels captured by the predicted labels. It is possible to do well on all the other metrics, yet do poorly on R2 if a system pro- duces annotations with a different distribution than those in the original labels.
In Table3we show the scores of the top 10 sys- tems across our 2 Sub-tasks according to Pearson’s