Írta:
GYIMÓTHY TIBOR HAVASI FERENC KISS ÁKOS
FORDÍTÓPROGRAMOK
Egyetemi tananyag
2011
Tudományegyetem Természettudományi és Informatikai Kar Szoftverfejlesztés Tanszék
LEKTORÁLTA: Dr. Aszalós László, Debreceni Egyetem Informatikai Kar Számítógéptudományi Tanszék
Creative Commons NonCommercial-NoDerivs 3.0 (CC BY-NC-ND 3.0) A szerző nevének feltüntetése mellett nem kereskedelmi céllal szabadon másolható, terjeszthető, megjelentethető és előadható, de nem módosítható.
TÁMOGATÁS:
Készült a TÁMOP-4.1.2-08/1/A-2009-0008 számú, „Tananyagfejlesztés mérnök informatikus, programtervező informatikus és gazdaságinformatikus képzésekhez” című projekt keretében.
ISBN 978-963-279-503-4
KÉSZÜLT: a Typotex Kiadó gondozásában FELELŐS VEZETŐ: Votisky Zsuzsa
AZ ELEKTRONIKUS KIADÁST ELŐKÉSZÍTETTE: Csépány Gergely László
KULCSSZAVAK:
fordítóprogramok, attribútum nyelvtanok, interpreterek, fordítóprogram-generáló rendszerek, röpfordítás.
ÖSSZEFOGLALÁS:
A fordítóprogramok feladata, hogy a különböző programozási nyelven írt programokat
végrehajtható gépi kódú utasításokká transzformálja. A fordítási folyamat nagyon összetett, hiszen sok programozási nyelv létezik és a különböző processzorok gépi utasítás készlete is jelentősen eltérhet egymástól. Figyelembe véve a rendelkezésre álló magyar nyelvű szakirodalmat, ebben a jegyzetben nem törekedtünk egy átfogó, a fordítás minden fázisát érintő anyag elkészítésére, hanem három területet érintünk részletesebben.
A fordítási folyamat legjobban kidolgozott fázisainak a lexikális és a szintaktikus elemzés tekinthető. Hatékony algoritmusok és ezek megvalósítását támogató rendszerek készültek a lexikális és szintaktikus elemzők automatikus előállítására. A jegyzetben példákon keresztül bemutatjuk az ANTLR rendszert, amely segítségével formális nyelvtan alapú definíciók alapján gyakorlatban is használható minőségű elemzők generálhatók.
A szintaktikus elemzést követő fordítási fázis a szemantikus elemzés. Ennek feladata az olyan fordítási időben felderíthető problémák megoldása, amelyek a hagyományos szintaktikus elemzőkkel nehezen valósíthatók meg (ilyen például a típus kompatibilitás vagy a változók láthatósági kérdésének kezelése). A szemantikus elemzés elterjedt modellje az attribútum nyelvtan alapú fordítási modell. A jegyzetben ismertetjük az attribútum nyelvtanokat és a kapcsolódó attribútum kiértékelő stratégiákat, valamint példákat mutatunk be arra, hogyan használhatók az
Tartalomjegyzék
1. Bevezetés 5
2. A fordítóprogramok alapjai 7
2.1. Áttekintés . . . 7
2.1.1. Formális nyelvtanok és jelölésük . . . 7
2.1.2. A FI halmaz. . . 8
2.1.3. Az LL(k) elemzés . . . 9
2.1.4. Feladatok . . . 10
2.2. A fordítóprogramok szerkezete . . . 10
2.3. Lexikális elemz˝o . . . 11
2.4. Szintaktikus elemz˝o . . . 11
3. Lexikális és szintaktikus elemz˝o a gyakorlatban - ANTLR 13 3.1. Jelölések használata . . . 13
3.2. Az ANTLR telepítése . . . 13
3.3. Fejlesztés ANTLRWorks környezetben . . . 14
3.4. Az ANTLR nyelvtanfájl felépítése . . . 16
3.5. Lexikális elemz˝o megvalósítása . . . 16
3.5.1. Feladatok . . . 17
3.6. Szintaktikus elemz˝o megvalósítása . . . 17
3.6.1. Feladatok . . . 20
3.7. Akciók beépítése . . . 20
3.8. Paraméterek kezelése . . . 21
3.9. Kifejezés értékének kiszámítása szemantikus akciókkal . . . 21
3.9.1. Feladatok . . . 22
3.9.2. ANTLR által generált kód . . . 23
3.10. AST építés . . . 25
3.10.1. Feladatok . . . 30
4. Attribútumos fordítás 32 4.1. Attribútum nyelvtanok definíciója . . . 32
4.2. Attribútum kiértékelés . . . 36
4.3. Attribútum nyelvtan bináris törtszám értékének kiszámítására . . . 38
4.4. Többmenetes attribútum kiértékel˝o . . . 41
4.5. Típus kompatibilitás ellen˝orzés . . . 46
4.6. Rendezett attribútum nyelvtanok . . . 49
4.6.1. OAG teszt . . . 49
4.6.2. OAG vizit-sorozat számítása . . . 51
4.7. Attribútum nyelvtanok osztályozása . . . 53
4.8. Közbüls˝o kód generálása . . . 55
4.9. Szimbólumtábla kezelése . . . 56
4.10. Feladatok . . . 58
5. Interpretált kód és röpfordítás 60 5.1. Fa alapú interpreter . . . 61
5.2. Bájtkód alapú interpreter . . . 61
5.3. Szálvezérelt interpreterek . . . 63
5.3.1. Tokenvezérelt interpreter . . . 64
5.3.2. Direkt vezérelt interpreter . . . 65
5.3.3. Környezetvezérelt interpreter . . . 66
5.4. Röpfordítás . . . 68
5.5. Példamegvalósítás. . . 72
5.5.1. Bájtkódgenerálás és -interpretálás megvalósítása Java nyelven . . . . 72
5.5.2. Bájtkód alapú és szálvezérelt interpreterek megvalósítása C nyelven . 77 5.5.3. Röpfordító megvalósítása C nyelven Intel Linux platformra . . . 83
5.6. Összegzés . . . 86
5.7. Feladatok . . . 86
Irodalomjegyzék 86
1. fejezet Bevezetés
A fordítóprogramok feladata, hogy a különböz˝o programozási nyelven írt programokat végrehajtható gépi kódú utasításokká transzformálja. A fordítási folyamat nagyon össze- tett, hiszen sok programozási nyelv létezik és a különböz˝o processzorok gépi utasítás készlete is jelent˝osen eltérhet egymástól. Nem véletlen, hogy a számítógépek elterjedé- sének id˝oszakában (50-es évek) a fordítóprogramok hatékony megvalósítását tekintették az egyik legbonyolultabb számítástudományi és szoftvertechnológiai problémának. Sok kiváló informatikai szakember kezdett el dolgozni ezen a területen, aminek eredményeként létrejöttek olyan algoritmusok, amelyek felhasználásával nagyméret˝u programokra is sikerült végrehajtási id˝oben és tárméretben is elfogadható kódot generálni. Ezt nyilvánvalóan az is el˝osegítette, hogy a számítógépek m˝uszaki teljesítménye rohamosan növekedett, pl. nem jelentett problémát a megnövekedett tárigény.
A beágyazott rendszerek terjedésével ez a kényelmes helyzet megváltozott. Noha az ezekben az eszközökben alkalmazott processzorok teljesítménye is rohamosan növekszik, de jelent˝osen elmarad az asztali gépek nyújtotta lehet˝oségekt˝ol.
Ez a trend újból óriási kihívást jelent a fordítóprogramokkal foglalkozó szakemberek számára. Meg kell találni azokat a megoldásokat, amelyekkel a gyakran nagyon összetett alkalmazások is hatékonyan végrehajthatók ezeken a beágyazott eszközökön. Ez általában nagyon agresszív optimalizálási megoldásokat igényel mind végrehajtási id˝o, mind pedig tárméret területén. A beágyazott rendszerek esetében egy sajátos problémaként megjelent egy harmadik optimalizálási szempont is, nevezetesen az energia-felhasználás kérdése. Mivel ezek az eszközök általában korlátos energiaforrással rendelkeznek, ezért a generált kód energia-felhasználását is optimalizálni kell.
A fordítóprogramokkal kapcsolatos eredményekr˝ol számos kiváló szakkönyv készült.
Az angol nyelv˝u szakkönyvek közül mindenképpen ki kell emelni az A. V. Aho, R. Sethi és J. D. Ullman által írt alap könyvet, amit szokás „Dragon” könyvként is említeni [2].
Ez a könyv szisztematikusan tárgyalja a fordítás különböz˝o fázisait, érinti a kapcsolódó elméleti eredményeket, de alapvet˝oen gyakorlati megközelítéssel dolgozza fel a területet.
Szintén kiváló angol nyelv˝u szakkönyv S.S. Muchnick munkája [8]. Ez a könyv a fordítóprogramok legösszetettebb problémájának tekinthet˝o kódoptimalizálás alapjait képez˝o programanalizálási módszerekkel foglalkozik.
Magyar nyelven is elérhet˝o néhány kiváló munka a fordítóprogramok területén. A
fordítóprogramok szintaktikus elemzésének elméleti hátterét ismerteti Fülöp Z. egyetemi jegyzete [5]. Csörnyei Z. 2006-ban publikált Fordítóprogramok cím˝u könyve [4] áttekintést ad a teljes fordítási folyamatról sikeresen ötvözve a szükséges elméleti háttér és a gyakorlati problémák bemutatását. A szintaktikus elemzés gyakorlati oktatásához készített hasznos példatárat Aszalós L. és Herendi T. [3].
Figyelembe véve a rendelkezésre álló magyar nyelv˝u szakirodalmat, ebben a jegyzetben nem törekedtünk egy átfogó, a fordítás minden fázisát érint˝o anyag elkészítésére. Erre a jegyzet méret korlátai miatt sem lett volna lehet˝oség. A jegyzetben egy rövid bevezet˝o fejezet (2. fejezet) után három területet érintünk részletesebben.
A fordítási folyamat legjobban kidolgozott fázisainak a lexikális és a szintaktikus elemzés tekinthet˝o. Hatékony algoritmusok és ezek megvalósítását támogató rendszerek készültek a lexikális és szintaktikus elemz˝ok automatikus el˝oállítására. A jegyzet 3. fejezetében pél- dákon keresztül bemutatjuk az ANTLR rendszert [1], amely segítségével formális nyelvtan alapú definíciók alapján gyakorlatban is használható min˝oség˝u elemz˝ok generálhatók.
A szintaktikus elemzést követ˝o fordítási fázis a szemantikus elemzés. Ennek feladata az olyan fordítási id˝oben felderíthet˝o problémák megoldása, amelyek a hagyományos szintaktikus elemz˝okkel nehezen valósíthatók meg. Ilyen például a típus kompatibilitás vagy a változók láthatósági kérdésének kezelése. A szemantikus elemzés elterjedt modellje az attribútum nyelvtan alapú fordítási modell. A 4. fejezetben ismertetjük az attribútum nyelvtanokat és a kapcsolódó attribútum kiértékel˝o stratégiákat, valamint példákat mutatunk be arra, hogyan használhatók az attribútum nyelvtanok fordítás idej˝u szemantikus problémák megoldására.
A beágyazott rendszerek elterjedésével egyre nagyobb teret kaptak az értelmez˝o (in- terpreter) alapú program végrehajtási megoldások. Ezek lényege, hogy a forráskódból nem generálunk gépi kódú utasításokat, hanem egy értelmez˝o program segítségével hajtjuk végre az utasításokat. (Megjegyezzük, hogy általában a forrásprogramból készül egy közbüls˝o kódnak nevezett reprezentáció és az értelmez˝o program ezt a kódot hajtja végre.) Az 5.
fejezetben ismertetjük a különböz˝o értelmezési technikákat és bemutatunk optimalizálási megoldásokat.
Ez a jegyzet az egyetemi informatikai képzés BSc és MSc szakjain is használható a fordítóprogramokkal kapcsolatos kurzusokban. A jegyzet elsajátításához alapfokú ismeretek szükségesek a formális nyelvek elemzésér˝ol és programozási tapasztalat C és Java nyelve- ken.
2. fejezet
A fordítóprogramok alapjai
2.1. Áttekintés
Ebben a jegyzetben az un. szintaxis-vezérelt fordítási megoldással foglalkozunk. Ennek lé- nyege, hogy a fordítandó programozási nyelv szerkezete megadható egykörnyezet-független nyelvtannal. Ezután az adott nyelv szerint, minden programra a nyelvtan alapján készíthet˝o egyelemzési fa(derivációs fa). A formális nyelvtanokkal és elemzésükkel ebben a jegyzetben csak áttekintés szintjén foglalkozunk. A témába mélyebb betekintést a [4] és [5] jegyzetek adnak, gyakorlási lehet˝oségre pedig [3] jegyzet nyújt kiváló lehet˝oséget.
2.1.1. Formális nyelvtanok és jelölésük
Egy G formális nyelvtan egy olyan G = (N,T,S,P) négyes, ahol N a nemterminális szimbólumok, T a terminális szimbólumok halmaza, amelyeket szoktak tokeneknek is nevezni. P az α → β alakú átírási szabályok halmaza, az S ∈ N pedig egy kitüntetett nemterminális, a kezd˝oszimbólum. A továbbiakban a jelölésekben a következ˝o konvenciókat követjük:
a terminális szimbólumokat vagy a token nevével jelöljük kis bet˝ukkel megnevezve (pl.
szam), vagy az általa reprezentált karaktersorozatot egyszeres idéz˝ojelek között (pl.
’+’) Ezek lényegében az adott nyelv speciális karakterei (pl. ’,’ ’:’ ’;’), kulcsszavai (pl. ’if’, ’for’) illetve logikailag összetartozó karakter sorozatai (pl. azonosítók, konstansok).
a nemterminális szimbólumokat nagy kezd˝obet˝ukkel nevezzük el (pl. Tag).
ezek tetsz˝oleges sorozatát pedig a görög ABC bet˝uivel jelöljük (pl.α).
Egy formális nyelvtan környezetfüggetlen, ha a szabályai A→ β alakúak, azaz a bal oldalon pontosan egy darab nemterminális található. A legtöbb elemz˝o algoritmus eleve ilyen nyelvtanokkal dolgozik, mert elemzésük általánosságban véve sokkal könnyebb feladat, mint a környezetfügg˝o nyelvtanoké.
Egy környezetfüggetlen formális nyelvtantbalrekurzívnaknevezünk, ha van benne olyan A nemterminális, amelyb˝ol levezethet˝o (valamennyi szabály egymás utáni alkalmazásával
megkapható) egy Aα alakú kifejezés. Az ilyen típusú szabályokat az általunk használt elemz˝ok nem bírják elemezni, viszont tetsz˝oleges nyelvtan transzformálható vele ekvivalens, nem balrekurzív nyelvtanná.
Az elemzés során általában felépül˝o elemzési fa gyökerében a kezd˝oszimbólum van, a leveleit (amelyek terminális szimbólumok) összeolvasva megkapjuk az elemezend˝o inputot, a csúcspontokban pedig nemterminálisok ülnek a levezetésnek megfelel˝oen „összekötve”.
Példa: a2.1ábrán látható egy egyszer˝u értékadó utasítás formális nyelvtana.
1. Utasitas→azonosito ’:=’ Kifejezes 2. Kifejezes→Kifejezes ’+’ Tag 3. Kifejezes→Kifejezes ’−’ Tag 4. Kifejezes→Tag
5. Tag→Tag ’*’ Tenyezo 6. Tag→Tag ’/’ Tenyezo 7. Tag→Tenyezo
8. Tenyezo→’(’ Kifejezes ’)’
9. Tenyezo→szam 10. Tenyezo→azonosito
2.1. ábra. Értékadó utasítás környezet-független nyelvtana A nyelvtan
• nemterminális szimbólumai:Utasitas, Kifejezes, Tag, Tenyezo
• terminális szimbólumai: ’:=’, ’+’ , ’-’, ’*’ , ’/ ’, ’(’ , ’)’ , azonosito, szam
• kezd˝o szimbóluma: Utasitas
Ezt a nyelvtant felhasználva elkészíthetjük az alábbi értékadó utasítás alfa := beta + 8 * (gamma - delta)
elemzési fáját.
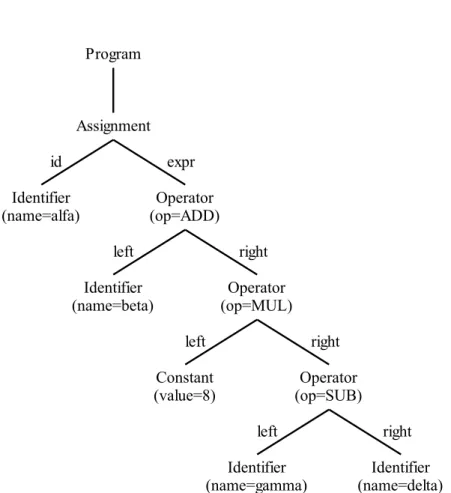
A2.2. ábrán láthatjuk, hogy az elemzési fában azalfa, beta, gamma, deltaszimbólumok helyett mindenütt azazonositoa 8-as konstans helyett pedig aszamterminális (token) szim- bólum szerepel. Alexikális elemz˝ofeladata, hogy ezeket a transzformációkat megvalósítsa.
2.1.2. A FI halmaz
Az elemzéshez szükséges egyik segédfogalom aFIk()halmaz, amely értelmezhet˝o tetsz˝ole- ges terminálisokat és/vagy nemterminálosakat tartalmazó kifejezésekre, és bel˝ole levezethet˝o terminális szimbólumok els˝o (first) k szimbólumainak halmazát jelenti, azaz:
terminális szavaknál ez a halmaz az els˝o k szimbólumuk – rövidebb esetén a teljes szó.
nemterminális szavaknál azon terminális szavak FIk()-jainak halmaza, amelyek ebb˝ol levezethet˝oek.
A2.1nyelvtan esetében aFI1(Tenyezo)halmaz: ’(’,szam,azonosito.
2.1. ÁTTEKINTÉS 9
Utasitas
azonosito
(alfa) ’:=’ Kifejezes
Kifejezes ’+’ Tag
Tag
Tenyezo
azonosito (beta)
Tag ’*’ Tenyezo
Tenyezo
szam (8)
’(’ Kifejezes ’)’
Kifejezes ’-’ Tag
Tag
Tenyezo
azonosito (gamma)
Tenyezo
azonosito (delta)
2.2. ábra. Azalfa := beta + 8 * (gamma - delta)utasítás elemzési fája
2.1.3. Az LL(k) elemzés
A LL(k) elemzés során a levezetés a kezd˝oszimbólumból indul. Bal oldali levezetés haszná- lunk (jelölése ⇒l), azaz minden egyes lépésnél kicseréljük a legbaloldalibb nemterminálist – legyen most ezA– valamelyik szabály alapján. Ha egyetlenA→β alakú szabályunk van, akkor ez a csere egyértelm˝u. Ha több ilyen van, akkor pedig az inputon lév˝o következ˝o k darab szimbólum alapján döntünk, hogy melyik szabályt alkalmazzuk. A LL(k) nyelvtanok olyan nyelvtanok, amelyeknél ez az információ bármilyen input esetén is elegend˝o az egyértelm˝u döntéshez.
Formálisan megfogalmazva: legyen k egy pozitív egész szám,α ⇒∗β jelentse azt, hogy α-ból β levezethet˝o, α ⇒∗l β pedig azt, hogy α-ból β baloldali levezetéssel (mindig csak a bal oldali nemterminális kicserélésével) levezethet˝o. Ekkor egy nem balrekurzív nyelvtan akkor LL(k) nyelvtan, ha valahányszor teljesülnek a
• S⇒∗l ωAα⇒ω β α ⇒∗ωx
• S⇒∗l ωAα⇒ω γ α ⇒∗ωy
• FIk(x) =FIk(y)
feltételek, akkorβ =γ-nak is teljesülnie kell.
2.1.4. Feladatok
Tekintsük az alábbi nyelvtant:
S −> + A A | ∗ A A A −> ’1 ’ | ’2 ’ | S
• Számoljuk ki aFI1(S)ésFI1(A)halmazokat!
• LL(k) nyelvtan-e a fenti nyelvtan, és ha igen, mekkorak-ra?
• Rajzoljuk föl az elemzési fáját az+ +1 2∗2 2 inputra!
• Melyik állítás igaz?
1. Minden LL(2) nyelvtan egyben LL(1) nyelvtan is.
2. Minden LL(1) nyelvtan egyben LL(2) nyelvtan is.
2.2. A fordítóprogramok szerkezete
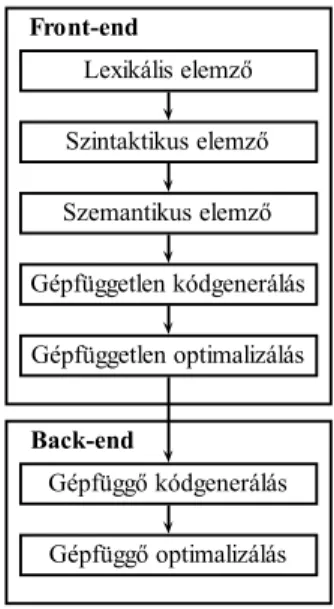
2.3. ábra. Fordítóprogramok fázisai
A fordítóprogramok f˝obb fázisai a2.3. ábrán látható. A gép független fázisokat szokás front-endnek a gép függ˝o részeket pedig back-endnek nevezni. A fordítóprogram front-end része analizálja a forrásprogramot, felépíti az elemzési fát, elvégzi a szükséges szemantikus ellen˝orzéseket és egy gép függetlenközbüls˝o kódotgenerál. A közbüls˝o kód assembly jelleg˝u
2.3. LEXIKÁLIS ELEMZ ˝O 11 kód, ami azonban független a konkrét gépi architektúráktól. Nagy el˝onye, hogy közbüls˝o kódból már könny˝u el˝oállítani gépi kódú utasításokat konkrét architektúrákra. Lehet˝oség van a generált közbüls˝o kód optimalizálására is pl. redundáns számítások kisz˝urésével.
A fordítóprogram back-end része a konkrét gépi architektúrára készíti el az áthelyezhet˝o gépi kódú vagy pedig assembly szint˝u programot. Itt már például fontos szempont a regiszter allokáció optimalizálása. A front-end és back-end részek szétválasztása nagyon el˝onyös, mivel így a back-end részek cseréjével egyszer˝uen készíthet˝o gépi kód különböz˝o platformokra.
A fordítóprogramok fontos része a szimbólumtábla kezelés illetve a fordítás különböz˝o fázisaiban észlelt hibák kezelése. A szimbólumtáblában a program azonosítóiról tárolunk információkat pl. egy változóról a típusát, az allokált memória címét, érvényességi tartomá- nyát (scope). A szimbólumtáblát a fordítás minden fázisában használjuk. Fordítási hibák leggyakrabban a fordítóprogram analízis fázisaiban (lexikális, szintaktikus, szemantikus elemzés) keletkeznek. Tipikus szintaktikus hiba, ha egy utasítás szerkezetét elrontjuk, például elhagyunk egy zárójelt. Szemantikus hiba lehet például az, ha egy értékadó utasítás baloldali változójának típusa nem kompatibilis a jobboldali kifejezés típusával. A fordítási hibák kezelésénél fontos szempont, hogy minél több hibát detektáljunk egy fordítás során.
2.3. Lexikális elemz˝o
A fordítóprogram bemenete egy karakter sorozat, például egy program forráskódja. A ka- rakter sorozat feldolgozásának els˝o lépése alexikális elemz˝o, amely a következ˝o feladatokat hivatott ellátni:
• Az összetartozó karaktereket egy tokenné összevonja: tokenek lehetnek egy adott programozási nyelv kulcsszavai (pl. ’if’, ’while’, ...), vagy számok (’123’, ’1.23’, ...), stb. Az olyan karakterek, amelyek önállóan bírnak jelentéssel, (pl. egy ’+’ jel) önálló tokenek lesznek.
• Kisz˝uri azokat a karaktereket, amelyek az elemzés szempontjából lényegtelenek:
tipikusan ilyenek a kommentek, újsor vagy white space karakterek (szóköz, tabulátor, ...).
• Felépít egy táblát (sztring tábla) a felismert tokenekre, amelyben bizonyos információ- kat tárol róluk (pl. az azonosító neve).
A lexikális elemz˝o tehát el˝ofeldolgozást végez az inputon, és egy token sorozatot ad át a szintaktikus elemz˝onek. A token saját típusán kívül tárolja az általa képviselt input szövegrészletet (egy egész szám esetében pl. ’12’), a forráskódban elfoglalt helyét (hányadik sorban és oszlopban volt volt) is. A szintaktikus elemz˝o a további feldolgozáshoz a tokeneket és a sztring táblát kapja meg.
2.4. Szintaktikus elemz˝o
A feldolgozás következ˝o lépése aszintaktikus elemz˝o, melynek feladata:
• Ellen˝orzi az input szintaktikáját, hogy megfelel-e az elvártaknak - amelyet környezet- független nyelvtan formájában fogalmazunk meg számára.
• A szintaktika (környezetfüggetlen nyelvtan) alapján készítse el˝o a további feldolgozást egy új bels˝o reprezentáció felépítésével, amely elméleti szempontból a elemzési fával mutat rokonságot, sok fordítóprogram esetében AST-nek, azaz absztrakt szintaxis fának hívnak.
A fordítóprogram következ˝o lépcs˝oje, aszemantikus elemz˝o ezen a bels˝o reprezentáción fog majd tovább dolgozni.
Látni fogjuk, hogy egyszer˝ubb esetekben az AST felépítése nélkül, már az elemzés közben elvégezhet˝o a kívánt feladat.
3. fejezet
Lexikális és szintaktikus elemz˝o a gyakorlatban - ANTLR
Egy fordítóprogram implementálása sok olyan feladattal jár, amely gépies és igen id˝oigényes.
Ez az oka annak, hogy a gyakorlatban ritkán fordul el˝o, hogy valaki közvetlenül írjon elemz˝ot, sokkal inkább használ erre a célra egy fordítóprogram generáló rendszert, amely a gépies részfeladatok elvégzése mellett általában számos kényelmi szolgáltatással teszi még hatékonyabbá a fejlesztést.
Egyik ilyen szabadon felhasználható, nyílt forráskódú, platformfüggetlen LL(k) fordító- program generátor az ANTLR [1] (ANother Tool for Language Recognition). Kifejezetten ehhez a rendszerhez fejlesztették az ANTLWorks1környezetet, amely még kényelmesebbé és hatékonyabbá teszi a fejlesztést, különösen a fordítóprogramok világával újonnan ismerked˝ok számára.
3.1. Jelölések használata
Az el˝oz˝o fejezetben megismertük az a fordítóprogramok elméletnél megszokottól jelölési konvenciót. Ebben a fejezetben egy ett˝ol különböz˝o konvenciót, az ANTLR konvencióját fogjuk használni: a tokenek avagy terminálisok nevének nagybet˝uvel kell kezd˝odnie, a nemterminálisokénak pedig kisbet˝uvel, és egyikben sem használható ékezetes karakter.
3.2. Az ANTLR telepítése
Az ANTLR Java alapú rendszer, így használatának el˝ofeltétele, hogy telepítve legyen Java futtató környezet. Az ANTLR és az ANTLRWorks szabadon letölthet˝o a következ˝o web- oldalról (http://www.antlr.org/works/index.html). Ez utóbbi egy jar fájlba van csomagolva, amely magába foglalja az ANTLR-t és az ANTLRWorks-öt is. A jegyzet írásának idejében a fájl neve anlrworks-1.4.2.jar, amely a következ˝o paranccsal indítható:
java -jar anlrworks-1.4.2.jar
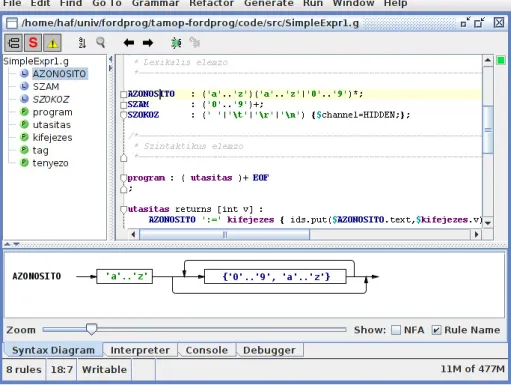
3.1. ábra. Az ANTLRWorks m˝uködés közben: bal oldalt a terminális és nemterminális szimbólumok listája, jobb oldalt a nyelvtanfájl, lent pedig az aktuális szabály szintaxis diagramja
Az ANTLR számára a generálandó fordítóprogramot egy (tipikusan .g kiterjesztés˝u) nyelvtanfájl formájában kell megadnunk, amelyb˝ol alapértelmezésben Java2 forráskódot gyárt, legenerálva a lexikális (Lexer) és szintaktikus elemz˝ot (Parser).
Parancssort használva a nyelvtanfájlból a következ˝o módon indíthatjuk a generálást:
java -cp antlrworks-1.4.2.jar org.antlr.Tool SajatNyelvtan.g
A parancssoros generálás további részleteit nem tárgyaljuk, példánkban az ANTLWorks- szel fogunk dolgozni, ahol a fenti parancsot a „Generate code” menüpontra kattintással hívhatjuk meg.
3.3. Fejlesztés ANTLRWorks környezetben
Az ANTLWorks környezet a nyelvtanfájlok szerkesztését több oldalról támogatja. Egyrészt a szövegszerkeszt˝oje beírás közben elemzi a nyelvtan fájlt, jelezve a hibás részeket, és a beírt szabályokat azonnal mutatja diagram formájában is.
Tartalmaz egy beépített hibakeres˝o részt is, amelyet a „Run” menüpont „Debug” almenü- jével indíthatunk - 3.2ábra. Itt adhatjuk meg azt az inputot, amire futtatni szeretnénk, és itt
1Eclipse-be beépül˝o modul is elérhet˝o hozzá.
2Támogat más célnyelveket is, pl. C/C++, C#, Python, Ruby.
3.3. FEJLESZTÉS ANTLRWORKS KÖRNYEZETBEN 15 állíthatjuk be a kezd˝oszimbólumot, amivel az ANTLRWorks tesztel˝o része kezdeni fogja az elemzést.
3.2. ábra. A hibakeresés el˝ott meg kell adnunk a kezd˝oszimbólumot és az elemzend˝o bemenetet
Amint a hibakeresés elindult –3.3 ábra – , egyesével lépkedhetünk a tokeneken, nézve melyik szabály hívódik meg, milyen elemzési fa épül, és mi íródik a konzolra.
3.3. ábra. Hibakeresés közben egyszerre látjuk az inputot, az azt elemz˝o szabályt és a készül˝o elemzési fát
3.4. Az ANTLR nyelvtanfájl felépítése
Egy ANTLR nyelvtan fájl egyszer˝usített3szerkezete:
grammar NyelvtanNeve ;
< Lexik á l i s elemz ˝o s z a b á l y a i >
< S z i n t a k t i k u s elemz ˝o s z a b á l y a i >
3.5. Lexikális elemz˝o megvalósítása
A lexikális elemz˝onk a lexikális szabályokat az alábbi formában várja:
TOKEN_NEVE : t o k e n _ d e f i n í c i ó j a { a k c i ó ; } ;
A token nevének és definíciójának megadása kötelez˝o, az akció rész opcionális. Fontos, hogy a token nevének nagybet˝uvel kell kezd˝odnie. A definícióban azt kell megadni egy reguláris kifejezés formájában, hogy az adott token milyen karaktersorozatra illeszkedjen.
Ezt láthatjuk a3.4ábrán.
Minta Amire illeszkedik
’a’ azakarakterre
’abcde’ az abcde karaktersorozatra
’.’ egy tetsz˝oleges karakterre
~A olyan karakterre illeszkedik, amire A nem A | B arra, amire vagy A vagy B illeszkedik
’a’..’z’ egy karakterre, amely kódja a két karakter közé esik A* 0 vagy több A-ra illeszkedik
A+ 1 vagy több A-ra illeszkedik
A? 0 vagy 1 A-ra illeszkedik
3.4. ábra. ANTLR-ben használható reguláris kifejezések
Például nézzük meg olyan AZONOSITO token megadását, amely kis bet˝uvel kezd˝odik, és utána valamennyi kis bet˝uvel vagy számjeggyel folytatódik. Ennek a szintaxis diagramja a3.5ábrán látható.
AZONOSITO : ( ’ a ’ . . ’ z ’ ) ( ’ a ’ . . ’ z ’ | ’ 0 ’ . . ’ 9 ’ )∗;
A token definíciója mögé opcionálisan írható akció egy kapcsos zárójelek közé írt programkód részlet. Leggyakrabban ezt a lexikális elemz˝o vezérlésére használják, amelyek közül mi azt fogjuk most ismertetni, hogy hogyan vehet˝o rá, hogy az adott tokent a lexikális elemz˝o ne adja át a szintaktikus elemz˝onek. A gyakorlatban ezt például a megjegyzések
3A jegyzet több ANTLR funkcióra szándékosan nem tér ki, hogy az kezd˝o olvasó számára is könnyebben érthet˝o legyen. Az összes elérhet˝o funkció leírását az olvasó megtalálja az ANTLR weboldalán.
3.6. SZINTAKTIKUS ELEMZ ˝O MEGVALÓSÍTÁSA 17
3.5. ábra. Az AZONOSITO token szintaxis diagrammja
vagy whitespace-ek kezelésére használhatjuk. Az els˝o megoldás erre a problémára a skip() függvény meghívása, amely az adott tokent megsemmisíti. A másik, ha a tokent átsoroljuk a rejtett csatornához a „$channel=HIDDEN;” kódrészlettel. Ekkor a tokent reprezentáló objektum megmarad, kés˝obb akár el˝ovehet˝o, csak a szintaktikus elemz˝o nem kapja meg.
Ez utóbbi módszer a preferáltabb, mi is ezt fogjuk használni.
A következ˝o példában C++ szer˝u kommenteket illetve újsor karaktereket sz˝urünk ki.
UJSOR : ’ \ n ’ { $ c h a n n e l =HIDDEN ; } ; KOMMENT : ’ / / ’ .∗ ’ \ n ’ { $ c h a n n e l =HIDDEN ; } ;
3.5.1. Feladatok
• Definiáljunk egy olyan lexikális elemz˝ot, amely egész számokat és azokat elválasztó szóközt vagy újsor karaktereket ismer föl, ez utóbbiakat viszont nem küldi tovább a szintaktikus elemz˝onek, csak az egész számokat.
• Definiáljunk egy olyan szám tokent, amely ráillik az egész számokra is, és a tizedes törtekre is! (Pl. 12, 13.45, ...)
• Definiáljunk egy olyan tokent, ami a C szer˝u kommentet sz˝uri ki az inputból!
3.6. Szintaktikus elemz˝o megvalósítása
A szintaktikus elemz˝o szabályainak megadása a következ˝o formában történik:
nemtermin á l i s _ n e v e : e l s ˝o a l t e r n a t í va
| má s o d i k a l t e r n a t í va . . .
| u t o l s ó a l t e r n a t í va
;
A nemterminális neve kis bet˝uvel kell, hogy kezd˝odjön. Az egyes alternatívákban pedig a következ˝o elemek szerepelhetnek egymástól szóközzel elválasztva:
• token nevek (pl. SZAM)
• token definíciók (pl. ’+’)
• nemterminális nevek (pl. tenyezo)
A rövidebb leírás mellett a fentiek kombinálhatók a lexikális elemz˝onél már megismert reguláris kifejezések: +, *, ?, | jelek, a jelek csoportosítása pedig zárójelekkel irányítható.
Például tekintsük a korábbi2.1.4-ban lév˝o nyelvtan ANTL-beli leírását:
s : ’+ ’ a a
| ’∗’ b b
; a : ’ 1 ’
| ’ 2 ’
| ’ ( ’ s ’ ) ’
;
A fenti példa egyszer˝u volt, mert láthatóan 1 karakter el˝orenézésével meg lehet állapítani, hogy melyik alszabályt válassza az elemz˝o (pl. s-nél ’+’ esetén az els˝ot, ’*’ esetén a másodikat), így az ANTLR is könnyen megbirkózik majd a feladattal.
Bonyolultabb a helyzet, ha nem LL(k) nyelvtannal van dolgunk, mint ahogyan az a2.1 ábrán látható formális nyelvtan esetében is így van. Ha azt ANTLR formára hozzuk, a következ˝ot kapjuk:
u t a s i t a s : a z o n o s i t o ’ := ’ k i f e j e z e s
;
k i f e j e z e s : k i f e j e z e s ’+ ’ t a g
| k i f e j e z e s ’−’ t a g
| t a g
;
t a g : t a g ’∗’ t e n y e z o
| t a g ’ / ’ t e n y e z o
| t e n y e z o
;
t e n y e z o : ’ ( ’ k i f e j e z e s ’ ) ’
| SZAM
| AZONOSITO
;
Látható, hogy a kifejezes és a tag nemterminális is balrekurzív, emiatt nem boldogul el vele egy LL(k) elemz˝o. Ennek megszüntetése a nyelvtan kis átalakítással megoldható:
u t a s i t a s : a z o n o s i t o ’ := ’ k i f e j e z e s
;
k i f e j e z e s : t a g k i f e j e z e s 2
;
k i f e j e z e s 2 : ’+ ’ t a g
| ’−’ t a g
|
;
t a g : t e n y e z o t a g 2
3.6. SZINTAKTIKUS ELEMZ ˝O MEGVALÓSÍTÁSA 19
;
t a g 2 : ’∗’ t e n y e z o
| ’ / ’ t e n y e z o
|
;
t e n y e z o : ’ ( ’ k i f e j e z e s ’ ) ’
| SZAM
| AZONOSITO
;
Az átalakítás után láthatóan LL(1) nyelvtant kaptunk, hiszen minden alternatívánál egy token el˝orenézéssel – még fejben számolva is – dönteni tudunk, hogy melyik alternatívát válasszuk.
Ha használjuk az ANTLR adta lehet˝oséget, hogy reguláris kifejezést is használhatunk a szabályainkban, akkor a fenti nyelvtant egy rövidebb formában is leírhatjuk:
k i f e j e z e s : t a g
( ’+ ’ t a g
| ’−’ t a g )∗
; t a g :
t e n y e z o
( ’∗’ t e n y e z o
| ’ / ’ t e n y e z o )∗
;
t e n y e z o : SZAM
| ’ ( ’ k i f e j e z e s ’ ) ’
| AZONOSITO
;
3.6. ábra. Az kifejezes szabály szintaxis diagramja
Az átalakított nyelvtan szintaxis diagramján (amelyet az ANTLWorks kirajzol nekünk, 3.6ábra) látszik, hogy most már minden alszabályi döntést az elemz˝o egy token el˝orenézésé- vel el tud dönteni.
3.6.1. Feladatok
• Egészítsük ki a nyelvtant a tenyezo kib˝ovítésével úgy, hogy a sin(x) is használható legyen, aholxegy tetsz˝oleges részkifejezés.
• Oldjuk meg, hogy a nyelvtan hatványozni is tudjon: a^b formában, ahol a és b tetsz˝oleges részkifejezések. Figyelj arra, hogy a hatványozás a szorzás-osztásnál magasabb, de a zárójelnél alacsonyabb prioritású.
3.7. Akciók beépítése
Az ANTLR a szintaktikus elemz˝ob˝ol egy Java osztályt fog generálni, ahol minden nemter- minális egy-egy metódus lesz. A fenti példában a Parser osztálynak lesz egy kifejezes, egy tag és egy tenyezo metódusa, melyek feladata, hogy az inputról beolvassák önmagukat, azaz leelemezzék az input rájuk es˝o részét. Ezekbe a metódusokba szúrhatunk be tetsz˝oleges kódrészletet, ha azt { } jelek közé beírjuk. Lássunk arra példát, hogy írunk ki valamit a konzolra az után, amikor a tenyezo nemterminális elemzése közben a SZAM tokent már fölismertük.
t e n y e z o : SZAM { System . o u t . p r i n t l n ( " Sz ám! " ) ; }
;
A szemantikus akciókban lehet˝oség van a már elemzett tokenek vagy nemterminálisok adatainak az elérésére is. Az adott token vagy nemterminális objektumára úgy tudunk hivatkozni, hogy annak neve elé egy $ jelet teszünk. Ha ez a név nem egyértelm˝u, akkor címkét adhatunk a tokennek vagy nemterminálisnak úgy, hogy a címke nevét a token vagy nemterminális elé írjuk = jellel elválasztva attól. A token vagy nemterminális objektumának adattagjai közül számunkra az alábbiak az érdekesek:
text : a token vagy nemterminálisnak megfelel˝o input szövegrészlet int : a fenti szövegrészlet egész számmá konvertálva - ha az lehetséges
line : azt mondja meg, hogy melyik sorban van az inputon belül az adott token vagy nemterminális
Lássunk egy példát a használatra, ahol megcímkézzük mindkét SZAM tokent, és mindkett˝o- nek azintadattagjára hivatkozunk:
o s s z e g : n1=SZAM ’+ ’ n2=SZAM
{i n t o s s z e g = $n1 .i n t+$n2 .i n t;
System . o u t . p r i n t l n ( "Az ö s s z e g : "+ o s s z e g ) ; }
;
Van néhány különleges hely, ahova még be tudunk szúrni kódrészletet:
@members : ezt az akciót minden szabályon kívülre kell elhelyeznünk, és amit ide írunk, azt az ANTLR beszúrja az elemz˝o osztály definíciójának törzsébe. Ezzel például új adattagokat vagy metódusokat is föl tudunk venni az elemz˝o osztályunkba.
3.8. PARAMÉTEREK KEZELÉSE 21
@init : ezt egy szabály neve után, még a „:” karakter elé lehet elhelyezni, és a bele írt kódrészlet a szabály metódusának legelejére fog bemásolódni.
@after : hasonló az el˝oz˝ohöz, csak ez pedig a metódus végére másolódik.
3.8. Paraméterek kezelése
Mivel minden nemterminálisból metódus lesz, ezért lehet˝oség van arra is, hogy bemen˝o és kimen˝o paramétereket definiáljunk számukra a következ˝o módon:
nemtermin á l i s [ t i p u s b 1 bemeno1 , t i p u s b 2 bemeno2 , . . . ]
r e t u r n s [ t i p u s k 1 kimeno1 , t i p u s k 2 kimeno2 ] : d e f i n i c i ó
;
A bemenoX és a kimenoX a bemen˝o illetve a kimen˝o paraméterek neve. Hivatkozni rájuk szemantikus akcióból a címkéhez hasonlóan $ prefixszel lehet, így állíthatjuk be a szabály kimen˝o paraméterét, illetve használhatjuk fel a bemen˝o paraméter értékét.
Ha valamelyik szabály jobb oldalára bemen˝o paraméterrel rendelkez˝o nemterminálist írunk, akkor ott (éppen mint függvényhívásnál) meg kell mondani milyen paraméterekkel hívjuk. Ezeket a paramétereket [érték1,érték2,...] szintaktikával kell megadnunk, például:
x [i n t be1 , i n t be2 ] r e t u r n s [i n t k i ] : SZAM { $ k i = $SZAM .i n t ∗ $be1 + $be2 ; }
; y :
’ f ’ x [ 2 , 3 ] { System . o u t . p r i n t l n ( " V i s s z a d o t t é r t é k="+$x . k i ) ; }
;
3.9. Kifejezés értékének kiszámítása szemantikus akciókkal
A következ˝okben lássunk egy komplett példát, konkrétan a 2.1 ábrán lév˝o nyelvtan meg- valósítását ANTLR nyelvtan formájában olyan módon, hogy annak értékét szemantikus függvények formájában ki is számolja.
A megvalósításban minden nemterminálishoz fölvettünk egy kimen˝o paramétert (v), amelybe adjuk vissza a kiszámolt részkifejezés értékét. A változók értékét pedig a Parser osztályunkban egyidsnev˝u Map típusú adattagban tároljuk.
SimpleExpr1.g
1 grammar SimpleExpr1 ; 2
3 @members {
4 p r i v a t e j a v a . u t i l . Map< S t r i n g , I n t e g e r > i d s = new j a v a . u t i l . TreeMap < S t r i n g , I n t e g e r > ( ) ;
5
6 p u b l i c s t a t i c v o i d main ( S t r i n g [ ] a r g s ) t h r o w s E x c e p t i o n {
7 SimpleExpr1Lexer l e x = new SimpleExpr1Lexer (new
ANTLRFileStream ( a r g s [ 0 ] ) ) ;
8 CommonTokenStream t o k e n s = new CommonTokenStream ( l e x ) ; 9 S i m p l e E x p r 1 P a r s e r p a r s e r = new S i m p l e E x p r 1 P a r s e r ( t o k e n s ) ; 10 p a r s e r . program ( ) ;
11 }
12 } 13
14 /∗−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
15 ∗ L e x i k a l i s e l e m z o
16 ∗−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−∗/ 17
18 AZONOSITO : ( ’ a ’ . . ’ z ’ ) ( ’ a ’ . . ’ z ’ | ’ 0 ’ . . ’ 9 ’ )∗; 19 SZAM : ( ’ 0 ’ . . ’ 9 ’ ) +;
20 SZOKOZ : ( ’ ’ | ’ \ t ’ | ’ \ r ’ | ’ \ n ’ ) { $ c h a n n e l =HIDDEN ; } ; 21 KOMMENT : ’ # ’ .∗ ’ \ n ’ { $ c h a n n e l =HIDDEN ; } ; 22
23 /∗−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
24 ∗ S z i n t a k t i k u s e l e m z o
25 ∗−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−∗/ 26
27 program : ( u t a s i t a s ) + EOF 28 ;
29
30 u t a s i t a s r e t u r n s [i n t v ] : 31 AZONOSITO ’ := ’ k i f e j e z e s
32 { i d s . p u t ($AZONOSITO . t e x t , $ k i f e j e z e s . v ) ;
33 System . o u t . p r i n t l n ($AZONOSITO . t e x t + " = " + $ k i f e j e z e s . v ) ;
34 }
35 ;36
37 k i f e j e z e s r e t u r n s [i n t v ] : 38 t 1 = t a g { $v = $ t 1 . v ; }
39 ( ’+ ’ t 2 = t a g { $v += $ t 2 . v ; } 40 | ’−’ t 3 = t a g { $v −= $ t 3 . v ; }
41 )∗
42 ; 43
44 t a g r e t u r n s [i n t v ] :
45 t 1 = t e n y e z o { $v = $ t 1 . v ; }
46 ( ’∗’ t 2 = t e n y e z o { $v ∗= $ t 2 . v ; } 47 | ’ / ’ t 3 = t e n y e z o { $v /= $ t 3 . v ; }
48 )∗
49 ;
5051 t e n y e z o r e t u r n s [i n t v ] :
52 SZAM { $v = $SZAM .i n t; }
53 | ’ ( ’ k i f e j e z e s ’ ) ’ { $v = $ k i f e j e z e s . v ; } 54 | AZONOSITO { $v = i d s . g e t ($AZONOSITO . t e x t ) ; } 55 ;
3.9.1. Feladatok
• Valósítsuk meg a3.6.1-ban leírt feladatokat!
3.9. KIFEJEZÉS ÉRTÉKÉNEK KISZÁMÍTÁSA SZEMANTIKUS AKCIÓKKAL 23
3.9.2. ANTLR által generált kód
Ahhoz, hogy jobban megértsük az ANTLR m˝uködését, érdemes megnézni milyen jelleg˝u kódot generál. Minden nemterminálisból a Parser osztályunk egy metódusa lesz, amit a fenti példa tenyezo nemterminálisa esetén a következ˝o szerkezettel lehet leírni:
i n t t e n y e z o ( ) {
i n t v ;
i f ( i n p u t . LA( 1 ) == ’ ( ’ ) { readToken ( ’ ( ’ ) ; v= k i f e j e z e s ( ) ; readToken ( ’ ) ’ ) ; }
e l s e i f ( i n p u t . LA( 1 ) ==SZAM) { Token s = readToken (SZAM) ; v= s . g e t I n t ( ) ;
}
e l s e i f ( i n p u t . LA( 1 ) ==AZONOSITO) { Token a= readToken (AZONOSITO) ;
S t r i n g varibleName =a . g e t T e x t ( ) ; v= g e t V a r i b l e ( varibleName ) ; }
e l s e {
s y n t a x E r r o r ( ) ; }
r e t u r n v ; }
A kódban jól látható, hogyan dönt az elemz˝o az egyes alternatívák között: el˝ore néz egy tokent (ez az input.LA(1)), és az alapján dönt, hogy az melyik jobb oldalnak felelhet meg, amit most „szemmel” is könnyen meg tudunk tenni – általános kiszámításához pedig segítség az el˝oz˝o fejezetben ismételt FI halmaz fogalma. Ha valamelyik alternatívának megfelel az adott input – LL(k) nyelvtan esetében ez csak az egyik alternatíva lehet – akkor annak az elemzésébe kezd, beolvasva az abban lév˝o tokeneket, illetve meghívja az ott lév˝o nemterminálisoknak megfelel˝o metódusokat, amelyek elemzik az adott nemterminálist. Ha pedig egyik alternatívának sem felel meg, akkor szintaktikai hibát kell jeleznünk.
Ugyanezt az ANTLR a következ˝o formában generálja le:
SimpleExpr1 - tenyezo
/ / $ANTLR s t a r t " t e n y e z o "
/ / S i m p l e E x p r 1 . g : 5 1 : 1 : t e n y e z o r e t u r n s [ i n t v ] : ( SZAM | ’ ( ’ k i f e j e z e s
’ ) ’ | AZONOSITO ) ;
p u b l i c f i n a l i n t t e n y e z o ( ) t h r o w s R e c o g n i t i o n E x c e p t i o n { i n t v = 0 ;
Token SZAM3=n u l l; Token AZONOSITO5=n u l l;
i n t k i f e j e z e s 4 = 0 ; t r y {
/ / S i m p l e E x p r 1 . g : 5 1 : 2 5 : ( SZAM | ’ ( ’ k i f e j e z e s ’ ) ’ | AZONOSITO )
i n t a l t 4 =3;
s w i t c h ( i n p u t . LA( 1 ) ) { c a s e SZAM:
{
a l t 4 =1;
} break; c a s e 1 3 :
{
a l t 4 =2;
} break; c a s e AZONOSITO :
{
a l t 4 =3;
} break; d e f a u l t:
N o V i a b l e A l t E x c e p t i o n nvae =
new N o V i a b l e A l t E x c e p t i o n ( " " , 4 , 0 , i n p u t ) ;
throw nvae ;
}
s w i t c h ( a l t 4 ) { c a s e 1 :
/ / S i m p l e E x p r 1 . g : 5 2 : 7 : SZAM {
SZAM3=( Token ) match ( i n p u t , SZAM, FOLLOW_SZAM_in_tenyezo291 ) ; v = (SZAM3!=n u l l? I n t e g e r . v a l u e O f (SZAM3 . g e t T e x t ( ) ) : 0 ) ;
} break; c a s e 2 :
/ / S i m p l e E x p r 1 . g : 5 3 : 7 : ’ ( ’ k i f e j e z e s ’ ) ’ {
match ( i n p u t , 1 3 , FOLLOW_13_in_tenyezo301 ) ; pushFollow ( FOLLOW_kifejezes_in_tenyezo303 ) ; k i f e j e z e s 4 = k i f e j e z e s ( ) ;
s t a t e . _fsp−−;
match ( i n p u t , 1 4 , FOLLOW_14_in_tenyezo305 ) ; v = k i f e j e z e s 4 ;
} break; c a s e 3 :
/ / S i m p l e E x p r 1 . g : 5 4 : 7 : AZONOSITO {
AZONOSITO5=( Token ) match ( i n p u t , AZONOSITO, FOLLOW_AZONOSITO_in_tenyezo315 ) ;
v = i d s . g e t ( ( AZONOSITO5!=n u l l?AZONOSITO5 . g e t T e x t ( ) :n u l l) ) ; }
break; }
}
c a t c h ( R e c o g n i t i o n E x c e p t i o n r e ) { r e p o r t E r r o r ( r e ) ;
3.10. AST ÉPÍTÉS 25
r e c o v e r ( i n p u t , r e ) ; }
f i n a l l y { }
r e t u r n v ; }
/ / $ANTLR e n d " t e n y e z o "
A megjegyzésekben látható, hogy melyik nyelvtan fájl sor melyik kódrészletet generálta, és hogy hova másolódtak be az általunk szemantikus akcióként megadott kódsorok. Látható az alternatívák közötti döntés módja is, továbbá a kimen˝o paraméter (v) visszatérési értékként való visszaadása.
3.10. AST építés
Ha a fordítóprogramunk feladata komplexebb annál, hogy a szintaktikai elemzés közben megoldható legyen, akkor a szintaktikai elemz˝ovel csak egy köztes formátumot érdemes építenünk, egy AST-t, amit aztán a szemantikus elemz˝onk fog feldolgozni.
Ennek megvalósításához els˝o körben az AST-nket kell megterveznünk. A fenti példánk esetében szükségünk lesz egy Program csomópontra a fa gyökere számára, egy Assignment csomópontra az értékadások reprezentálására, egy Operator csomópontra az aritmetikai m˝uveletek ábrázolásához, és a fa leveleiben lév˝o információkat pedig az Identifier (azonosító) és a Constant (szám) fogja tárolni.
A Program csomópontnak van valamennyi utasitas azaz Assignment gyermeke, amit a list nev˝u adattagjában tárol:
Program.java
package a s t ;
i m p o r t j a v a . u t i l . L i s t ; i m p o r t j a v a . u t i l . A r r a y L i s t ; p u b l i c c l a s s Program {
p r i v a t e L i s t <Assignment > l i s t ; p u b l i c Program ( ) {
l i s t = new A r r a y L i s t <Assignment > ( ) ; }
p u b l i c v o i d addAssignment ( Assignment asgmt ) { l i s t . add ( asgmt ) ;
}
p u b l i c L i s t <Assignment > g e t A s s i g n m e n t s ( ) { r e t u r n l i s t ;
}
p u b l i c v o i d e v a l u a t e ( j a v a . u t i l . Map< S t r i n g , I n t e g e r > i d s ) {
f o r ( Assignment asgmt : l i s t ) asgmt . e v a l u a t e ( i d s ) ; }
p u b l i c S t r i n g t o S t r i n g ( ) {
S t r i n g B u f f e r buf = new S t r i n g B u f f e r ( ) ; buf . append ( " ( Program \ n " ) ;
f o r ( Assignment asgmt : l i s t )
buf . append ( S t r i n g . f o r m a t ( " %s \ n " , asgmt ) ) ; buf . append ( " ) \ n " ) ;
r e t u r n buf . t o S t r i n g ( ) ; }
}
Egy Assignment, azaz értékadó utasításnak (utasitas) két gyermeke van: az AZONOSI- TO, amire az értékadás bal oldala (id adattag), és egy kifejezés (kifejezes nemterminális), amely az értékadás jobb oldal (expr adattag tárolja).
Assignment.java
package a s t ;
p u b l i c c l a s s Assignment { p r i v a t e I d e n t i f i e r i d ; p r i v a t e E x p r e s s i o n e x p r ;
p u b l i c Assignment ( I d e n t i f i e r id , E x p r e s s i o n e x p r ) { t h i s. i d = i d ;
t h i s. e x p r = e x p r ; }
p u b l i c I d e n t i f i e r g e t I d e n t i f i e r ( ) { r e t u r n i d ;
}
p u b l i c E x p r e s s i o n g e t E x p r e s s i o n ( ) { r e t u r n e x p r ;
}
p u b l i c v o i d e v a l u a t e ( j a v a . u t i l . Map< S t r i n g , I n t e g e r > i d s ) { i n t v = e x p r . e v a l u a t e ( i d s ) ;
i d s . p u t ( i d . getName ( ) , v ) ;
System . o u t . p r i n t l n ( i d . getName ( ) + " = " + v ) ; }
p u b l i c S t r i n g t o S t r i n g ( ) {
r e t u r n S t r i n g . f o r m a t ( " ( Assignment %s %s ) " , id , e x p r ) ; }
}
3.10. AST ÉPÍTÉS 27 A kifejezések egységes tárolása kedvéért létrehozunk egy közös ˝ost, az Expression osz- tályt, amely leszármazottja a Constant osztály egy SZAM tokent tárol a value adattagjában, az Identifier osztály pedig egy AZONOSITO-t tárol a name adattagjában, és egy Operator osztály, amely egy bináris kifejezést tárol: bal oldalát (left adattag), jobb oldalát (right adattag) és a közöttük lév˝o m˝uveletet (op adattag).
Expression.java
package a s t ;
p u b l i c a b s t r a c t c l a s s E x p r e s s i o n {
p u b l i c a b s t r a c t i n t e v a l u a t e ( j a v a . u t i l . Map< S t r i n g , I n t e g e r > i d s ) ; }
Identifier.java
package a s t ;
p u b l i c c l a s s I d e n t i f i e r e x t e n d s E x p r e s s i o n { p r i v a t e S t r i n g name ;
p u b l i c I d e n t i f i e r ( S t r i n g name ) { t h i s. name = name ;
}
p u b l i c S t r i n g getName ( ) { r e t u r n name ;
}
p u b l i c i n t e v a l u a t e ( j a v a . u t i l . Map< S t r i n g , I n t e g e r > i d s ) { r e t u r n i d s . g e t ( name ) ;
}
p u b l i c S t r i n g t o S t r i n g ( ) {
r e t u r n S t r i n g . f o r m a t ( " ( ID %s ) " , name ) ; }
}
Constant.java
package a s t ;
p u b l i c c l a s s C o n s t a n t e x t e n d s E x p r e s s i o n { p r i v a t e i n t v a l u e ;
p u b l i c C o n s t a n t (i n t v a l u e ) { t h i s. v a l u e = v a l u e ; }
p u b l i c i n t g e t V a l u e ( ) { r e t u r n v a l u e ;
}
p u b l i c i n t e v a l u a t e ( j a v a . u t i l . Map< S t r i n g , I n t e g e r > i d s ) { r e t u r n v a l u e ;
}
p u b l i c S t r i n g t o S t r i n g ( ) {
r e t u r n S t r i n g . f o r m a t ( " ( C o n s t a n t %d ) " , v a l u e ) ; }
}
Operator.java
package a s t ;
p u b l i c c l a s s O p e r a t o r e x t e n d s E x p r e s s i o n {
p r i v a t e s t a t i c f i n a l S t r i n g [ ] symbols = { "+" , "−" , "∗" , " / " } ; p u b l i c s t a t i c f i n a l i n t ADD = 0 ;
p u b l i c s t a t i c f i n a l i n t SUB = 1 ; p u b l i c s t a t i c f i n a l i n t MUL = 2 ; p u b l i c s t a t i c f i n a l i n t DIV = 3 ; p r i v a t e i n t op ;
p r i v a t e E x p r e s s i o n l e f t ; p r i v a t e E x p r e s s i o n r i g h t ;
p u b l i c O p e r a t o r (i n t op , E x p r e s s i o n l e f t , E x p r e s s i o n r i g h t ) { t h i s. op = op ;
t h i s. l e f t = l e f t ; t h i s. r i g h t = r i g h t ; }
p u b l i c i n t g e t O p e r a t o r ( ) { r e t u r n op ;
}
p u b l i c E x p r e s s i o n g e t L e f t O p e r a n d ( ) { r e t u r n l e f t ;
}
p u b l i c E x p r e s s i o n g e t R i g h t O p e r a n d ( ) { r e t u r n r i g h t ;
}
p u b l i c i n t e v a l u a t e ( j a v a . u t i l . Map< S t r i n g , I n t e g e r > i d s ) { i n t l h s = l e f t . e v a l u a t e ( i d s ) ;
i n t r h s = r i g h t . e v a l u a t e ( i d s ) ;
3.10. AST ÉPÍTÉS 29
s w i t c h ( op ) { c a s e ADD:
r e t u r n l h s + r h s ; c a s e SUB :
r e t u r n l h s − r h s ; c a s e MUL:
r e t u r n l h s ∗ r h s ; c a s e DIV :
r e t u r n l h s / r h s ; d e f a u l t:
throw new R u n t i m e E x c e p t i o n ( " Unexpected o p e r a t o r " + op ) ; }
}
p u b l i c S t r i n g t o S t r i n g ( ) {
r e t u r n S t r i n g . f o r m a t ( "(%s %s %s ) " , symbols [ op ] , l e f t , r i g h t ) ; }
}
Ezekkel az osztályokkal definiáltuk az AST-nk épít˝oköveit, amelyb˝ol a nyelvtanunk a korábban megszokott módon szemantikus akciókon belül építkezni tud. A korábbi példához képest annyi a különbség, hogy itt most az egyes nemterminálisok kimen˝o paramétere nem a részkifejezés értéke lesz, hanem a részkifejezést reprezentáló AST részfa.
SimpleExpr3.g
grammar SimpleExpr3 ;
@members {
p r i v a t e j a v a . u t i l . Map< S t r i n g , I n t e g e r > i d s = new j a v a . u t i l . TreeMap < S t r i n g , I n t e g e r > ( ) ;
p u b l i c s t a t i c v o i d main ( S t r i n g [ ] a r g s ) t h r o w s E x c e p t i o n { SimpleExpr3Lexer l e x = new SimpleExpr3Lexer (new
ANTLRFileStream ( a r g s [ 0 ] ) ) ;
CommonTokenStream t o k e n s = new CommonTokenStream ( l e x ) ; S i m p l e E x p r 3 P a r s e r p a r s e r = new S i m p l e E x p r 3 P a r s e r ( t o k e n s ) ; p a r s e r . program ( ) ;
} }
/∗−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
∗ L e x i k a l i s e l e m z o
∗−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−∗/ AZONOSITO : ( ’ a ’ . . ’ z ’ ) ( ’ a ’ . . ’ z ’ | ’ 0 ’ . . ’ 9 ’ )∗;
SZAM : ( ’ 0 ’ . . ’ 9 ’ ) +;
SZOKOZ : ( ’ ’ | ’ \ t ’ | ’ \ r ’ | ’ \ n ’ ) { $ c h a n n e l =HIDDEN ; } ; KOMMENT : ’ # ’ .∗ ’ \ n ’ { $ c h a n n e l =HIDDEN ; } ;
/∗−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
∗ S z i n t a k t i k u s e l e m z o
∗−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−∗/
program r e t u r n s [ a s t . Program p ]
@ i n i t { $p = new a s t . Program ( ) ; }
@ a f t e r { $p . e v a l u a t e ( i d s ) ; }
: ( u t a s i t a s { $p . addAssignment ( $ u t a s i t a s . p ) ; } ) + EOF
;
u t a s i t a s r e t u r n s [ a s t . Assignment p ] :
AZONOSITO ’ := ’ k i f e j e z e s { $p = new a s t . Assignment (new a s t . I d e n t i f i e r ($AZONOSITO . t e x t ) , $ k i f e j e z e s . p ) ; }
;
k i f e j e z e s r e t u r n s [ a s t . E x p r e s s i o n p ] : t 1 = t a g { $p = $ t 1 . p ; }
( ’+ ’ t 2 = t a g { $p = new a s t . O p e r a t o r ( a s t . O p e r a t o r .ADD, $p , $ t 2 . p ) ; }
| ’−’ t 3 = t a g { $p = new a s t . O p e r a t o r ( a s t . O p e r a t o r . SUB, $p , $ t 3 . p ) ; } )∗
;
t a g r e t u r n s [ a s t . E x p r e s s i o n p ] : t 1 = t e n y e z o { $p = $ t 1 . p ; }
( ’∗’ t 2 = t e n y e z o { $p = new a s t . O p e r a t o r ( a s t . O p e r a t o r .MUL, $p ,
$ t 2 . p ) ; }
| ’ / ’ t 3 = t e n y e z o { $p = new a s t . O p e r a t o r ( a s t . O p e r a t o r . DIV , $p ,
$ t 3 . p ) ; } )∗
;
t e n y e z o r e t u r n s [ a s t . E x p r e s s i o n p ] :
SZAM { $p = new a s t . C o n s t a n t ($SZAM .i n t) ; }
| ’ ( ’ k i f e j e z e s ’ ) ’ { $p = $ k i f e j e z e s . p ; }
| AZONOSITO { $p = new a s t . I d e n t i f i e r ($AZONOSITO . t e x t ) ; }
;
A teljes AST felépítése után, melynek ábrája a3.7ábrán látható, a program nemterminális after részében a nyelvtan meghívja a gyökér evaluate metódusát, átadva neki az azonosítókat tárolni hivatott Map-et. Ez az evaluate függvény azután a fát bejárva kiszámítja minden Assignment node által reprezentált értékadást, kiírva annak értékét a képerny˝ore.
3.10.1. Feladatok
• Valósítsuk meg ebben a környezetben is a3.6.1-ban leírt feladatokat!
• Írjunk a fenti példához olyan AST-t bejáró és transzformáló algoritmust, amely képes az olyan aritmetikai kifejezéseket egyszer˝usíteni illetve összevonni, mint amilyen a 0x+3yvagy a 2x+4y+5x−2y!
3.10. AST ÉPÍTÉS 31
3.7. ábra. Azalfa := beta + 8 * (gamma - delta)inputra generálódó AST
Attribútumos fordítás
Amint azt a korábbi fejezetekben láttuk a lexikális illetve szintaktikus elemzés segítségével lehet˝oség van az egyszer˝ubb programozási hibák kisz˝urésére. Ilyenek például speciális karak- terek helytelen használata, kulcsszavak elhagyása vagy utasítások szerkezetének eltévesztése.
Azonban vannak olyan fordítási problémák, amelyek nem kezelhet˝ok környezet-független nyelvtanokkal. Ilyen például a típus kompatibilitás illetve a változók láthatóságának kezelése. Ha például egy értékadó utasítás baloldalán egész változó szerepel a jobboldalán szerepl˝o kifejezés pedig valós értéket ad és az adott programozási nyelv nem engedélyezi az ilyen értékekre a konverziót, akkor típus kompatibilitási probléma jelentkezik. Az ilyen probléma detektálása környezet-független nyelvtannal általános esetben nem lehetséges, hiszen a problémát sok esetben a kifejezésben szerepl˝o változók típusa okozza, ami csak a szimbólumtáblán keresztül elérhet˝o. A változók láthatóságának kérdése ott jelentkezik, amikor egy adott változó használatakor a fordítóprogramnak meg kell keresni a változó adott környezetben érvényes deklarációját. Szimbólumtábla használata nélkül ez sem lehetséges, így a környezetfüggetlen-nyelvtanokon alapuló egyszer˝u szintaktikus elemzés alkalmatlan erre a feladatra. A típus kompatibilitás eldöntését és a változók láthatóságának kezelését szokás fordítási szemantikus problémának vagy a nyelvek környezetfügg˝o tulajdonságainak is nevezni. Látjuk, hogy ezen problémák kezelésére a környezet-független nyelvtanoknál
’er˝osebb’ eszközre van szükség. Ezt felismerve Knuth 1968-ban definiálta az Attribútum Nyelvtan alapú számítási modellt [7], amely alkalmas programozási nyelvek környezetfügg˝o tulajdonságainak kezelésére. A továbbiakban el˝oször formálisan definiáljuk a Attribútum nyelvtanok fogalmát, ismertetünk többfajta attribútum kiértékel˝o stratégiát majd pedig bemutatjuk, hogyan lehet attribútum nyelvtanok használatával kezelni a típus kompatibilitási és láthatósági problémákat.
4.1. Attribútum nyelvtanok definíciója
Egy attribútum nyelvtant öt komponenssel adhatunk meg:
AG= (G,A,Val,SF,SC)