CHAPTER 8 *
Gene-Enzyme Relationships
CHARLES YANOFSKY
I. I n t r o d u c t i o n 373 A. C u r r e n t V i e w of P r o t e i n S y n t h e s i s 374
B . E n z y m e S t r u c t u r e a n d F u n c t i o n 375 I I . G e n e t i c C o n t r o l of P r o t e i n S t r u c t u r e a n d F u n c t i o n 378
A. M u t a t i o n a l A l t e r a t i o n of E n z y m e A c t i v i t y 378 B . G e n e t i c C h a n g e s a n d T h e i r Affects o n , a n d R e l a t i o n s h i p t o , P r o t e i n
P r i m a r y S t r u c t u r e 383 C . N u c l e o t i d e C o m p o s i t i o n a n d S e q u e n c e of C o d i n g U n i t s 391
D . P r i m a r y S t r u c t u r e C h a n g e s i n R e l a t i o n t o F u n c t i o n 399 I I I . G e n e I n t e r a c t i o n s a n d E n z y m e F o r m a t i o n a n d A c t i v i t y 400
A. R e g u l a t i o n of P r o t e i n S y n t h e s i s 400 B . R e g u l a t i o n of E n z y m e A c t i v i t y 403 C . I n t e r allele C o m p l e m e n t a t i o n 406 D . S u p p r e s s o r M u t a t i o n s 408 IV. G e n e r a l C o n c l u s i o n 412
R e f e r e n c e s 412 I. Introduction
Studies of intermediary metabolism over the years have established t h a t most physiological reactions are enzyme-catalyzed. Genetic investi
gations performed to determine the relationship between enzyme-cata
lyzed reactions and the hereditary material of the cell have shown t h a t such reactions are under strict genetic control. How the genetic material exerts its control over the enzymic machinery of the cell has been inten
sively studied in recent years and we now understand m a n y aspects of the relationship between gene, enzyme, and biochemical reaction. T h e pioneer
ing work in this area by Beadle, T a t u m , and co-workers1 demonstrated very clearly t h a t single genetic changes generally result in the loss of ability to perform single biochemical reactions. Each loss of synthetic ability was subsequently correlated with the absence of a particular en
zymic activity.2
Extensive investigations of the effects of gene mutations on specific enzymes have shown t h a t there are several ways in which mutational alterations can affect the formation or activity of an enzyme. Since the methods used to select and detect m u t a n t s usually only require t h a t there be a loss or reduction of a functional activity, it would be expected t h a t all
* T h i s article is b a s e d o n material available t o t h e author prior to its c o m p l e t i o n in A u g u s t 1963.
373
genetic changes which could lead to such a loss would be recovered. The variety of effects t h a t have been observed support this expectation and illustrate very clearly the complexities of a functioning cell and the inter
actions between different cell constituents.
This article will be primarily concerned with enzyme structure and function and their alteration by mutation. Our present understanding of some important genetic phenomena which involve interactions between various cell components will also be discussed. Certain aspects of gene- enzyme relationships will be omitted, such as the genetic control of en
zymes associated with structural components of the cell and developmental control of enzyme formation. The author feels t h a t a t the present time our ignorance in these areas is so great it would be impossible to present more t h a n a speculative discussion of these problems. Other aspects of the func
tion of genetic material, such as its role in duplication and recombination and its participation in R N A (ribonucleic acid) synthesis, will not be dis
cussed. I n addition, the fine structure of genetic material and the process of mutation will only be considered in relation to the determination of protein structure. T h e reader is referred to other chapters in " T h e Bacteria" or to "Molecular Genetics" (J. H . Taylor, e d . )2 a for articles dealing with the subjects t h a t have been omitted.
T h e illustrative examples used in this review were frequently selected from studies performed in the author's laboratory. This selection does not reflect the absence of comparable examples from other studies; rather it indicates the preference of the author to deal with observations with which he has first-hand familiarity.
A. CURRENT V I E W OF PROTEIN SYNTHESIS
On the basis of studies on the chemical nature and structure of genetic m a t e r i a l ,3 - 6 the intermediary steps in protein s y n t h e s i s ,7 , 8 and the afore
mentioned gene-enzyme relationship,2 , 9 a concept has evolved of the role of genetic material in protein formation.
I t is believed t h a t a major function of the genetic material of each organism is to specify the amino acid sequences of the proteins formed by t h a t organism. I t is assumed t h a t the nucleotide sequences in D N A (de
oxyribonucleic acid) contain the information t h a t is ultimately translated into the specific amino acid sequences of polypeptide c h a i n s .1 0 - 1 3 A group of adjacent nucleotides in D N A , called a coding unit, presumably codes for each amino a c i d1 4 , 1 5 and a continuous sequence of coding units speci
fies a linear sequence of amino acids in a polypeptide c h a i n .1 2 I t is believed t h a t the translation of the nucleotide sequences of D N A into amino acid sequences does not take place directly at the site of D N A localization within each cell ; rather, segments of one strand of the D N A double helix are translated into single-stranded messenger R N A ' s1 6"1 9 and these mes-
8. GENE-ENZYME RELATIONSHIPS 375 senger R N A ' s are involved directly in determining the amino acid se
quence of proteins. T h e ribonucleotide sequence of each messenger R N A is presumably complementary to the nucleotide sequence of the D N A strand from which it was c o p i e d .1 6 - 1 8 T h e translation of the nucleotide sequence of an R N A messenger into the amino acid sequence of a protein is accomplished in association with groups of ribonucleoprotein particles, the ribosomes.8' 2 0 - 2 3 T h e amino acids are transferred to the ribosome- messenger R N A complex from specific amino acid carriers, called transfer R N A ' s .7 Each amino acid is activated and attached to transfer R N A by an amino acid-specific activating enzyme.7 The transfer R N A ' s are also amino acid-specific; however, there appears to be more t h a n one transfer R N A species for some of the amino a c i d s .2 4 - 2 7 T h e transfer R N A molecule is believed to contain a nucleotide sequence t h a t corresponds—presumably by complementarity—to a segment of the R N A messenger.2 8 T h e amino acid carried by transfer R N A is linked by peptide bond formation to an amino acid of a growing polypeptide chain. I t is believed t h a t the transla
tion of the information contained in the messenger R N A proceeds from the region corresponding to the amino terminal end of the polypeptide c h a i n .8'2 9 T h e chain when complete is released from the messenger- polyribosome complex and then probably completes the folding process to form the native protein. T h e folding is assumed to be determined by the primary structure of the polypeptide c h a i n .3 0 If a polypeptide chain is a subunit of a multichain complex, it associates with the other chains of the protein and forms the native functional u n i t .3 1 - 3 3 For a detailed de
scription of the stages in protein synthesis see the reviews by B e r g7 and Schweet and Bishop.8
B. ENZYME STRUCTURE AND FUNCTION
Since different regions of an enzyme m a y be responsible for different functions, it is necessary to inquire into the specific functions before at
tempting to interpret the relationships between gene and enzyme. At the present time it would appear t h a t at least the following different functions can be ascribed to the same or different regions of some enzyme molecules : substrate and coenzyme binding; catalytic activity; stability; allosteric interactions; and specific association with other polypeptide chains.
1. ACTIVE S I T E REGION
T h e portion of enzyme structure concerned with the binding and attack of the substrate is obviously of principal importance. These two seemingly related functions—catalytic activity and binding specificity—may often be performed by different specific regions of an enzyme, although most certainly these regions would be near one another in the folded molecule.
This conclusion is based on several observations.3 4 First, it has been found
t h a t substrate analogs will often compete with the substrate for the sub
strate binding site of an enzyme. The fact t h a t such analogs are competi
tive inhibitors suggests t h a t they m a y combine with the same region of the protein t h a t binds the substrate. Since these analogs are not attacked by the enzyme it would appear t h a t binding at the active site is not sufficient in itself to ensure attack by the enzyme. The distinction between binding site and catalytic site is also evident from other findings.3 4 Several proteo
lytic enzymes, including trypsin and chymotrypsin, have very similar amino acid sequences in the vicinity of a particularly reactive serine resi
d u e .3 5 This serine residue is believed to play an important role in the cata
lytic act. Although trypsin and chymotrypsin have similar sequences at the catalytic site and carry out the same type of reaction, they have very dif
ferent specificities. Trypsin attacks bonds on the carboxy side of lysine and arginine, while chymotrypsin splits bonds on the carboxy side of phenyl
alanine, tyrosine, tryptophan, methionine, leucine, and several other amino acids. From these facts it would appear t h a t amino acid sequences other than the one at the catalytic site are involved in determining binding speci
ficity. Substrate binding is now believed to play a major role in enzyme activation.3 4 According to the "induced fit" theory of K o s h l a n d3 6 the com
bination of substrate with enzyme induces a conformational change in the protein. The protein in this form—and only in this form—is capable of at
tacking the substrate.
2. T H E STRUCTURE OF THE ACTIVE S I T E REGION
Although the substrates of m a n y enzymes are small molecules and there is often only one substrate-combining site per protein molecule or protein subunit, it does not follow t h a t only a small segment of the polypeptide chain of a protein constitutes the active site region. Proteolytic digests of enzymes are usually devoid of enzymic activity and this is also true of denatured proteins. Reduction of disulfide bonds often leads to chain unfolding and to loss of enzymic activity. These and other observations indicate t h a t the correct amino acid sequence is insufficient to determine binding or catalytic activity unless it is held in the proper conformation.
I n studies on this subject with pancreatic ribonuclease, it has been found t h a t removal of a 20-amino acid fragment from the amino terminal end of the protein, or removal of the last four amino acids at the carboxy - terminal end of the protein, leads to enzyme i n a c t i v i t y .3 7'3 8 I n either case a conformational change is associated with the loss of a segment of the enzyme.3 7 T h e residual protein lacking the 20-amino acid fragment from the amino terminal end can still bind substrate. Thus, although the residual protein is enzymically inactive it can assume the conformation necessary for substrate binding. Other treatments also inactivate the e n z y m e ,3 7 some
8. GENE-ENZYME RELATIONSHIPS 377 involving the chemical modification of specific amino acids in the protein.
I t is likely, therefore, t h a t portions of a protein molecule, although not directly concerned with combination or attack of the substrate, are im
portant in establishing the native conformation of the active site region.
On the other hand, there are examples in which a sizable segment of an enzyme can be removed without appreciable loss of enzyme a c t i v i t y .3 9 , 4 0
I n such cases it is apparent t h a t the entire structure is not necessary to establish a functional conformation of the active site region. T h u s the active site region m a y constitute only a small segment of an enzyme molecule b u t m a n y different regions along the polypeptide chain m a y par
ticipate directly or indirectly in establishing its native conformation. Con
siderable information is available on the relationship between primary structure and tertiary s t r u c t u r e4 1 - 4 4 and the forces responsible for main
taining the globular protein s t r u c t u r e .4 5
3 . ALLOSTERIC INTERACTIONS
I n a number of cases substances t h a t do not interact directly with sub
strates or products of a reaction and are not analogs of the substrate combine specifically with an enzyme. This combination m a y serve to in
hibit or stimulate enzyme activity and is believed to be of major conse
quence in regulating enzyme activity. I n the best-understood interaction of this type, the end product of a biosynthetic p a t h w a y combines with and inhibits the enzyme t h a t catalyzes the first reaction unique to the p a t h w a y .4 6 I n such cases the enzyme must have a recognition site for the inhibitor. This t y p e of specific interaction with nonsubstrate has been termed an allosteric interaction.4 7 Allosteric interactions will be con
sidered in somewhat greater detail later in this article.
4. SPECIFIC ASSOCIATION
M a n y enzymes consist of subunits of like or unlike polypeptide chains.
I n some cases, only the complex is the physiologically effective unit. For specific association of polypeptide chains to occur, a portion, or portions, of the structure of each polypeptide chain must be concerned with affinity for the other polypeptide chain, or chains. Furthermore, since m a n y enzymes contain several polypeptide subunits it is likely t h a t the structure of each subunit, and of the complex, must prevent nonspecific associations. T h e structure of each folded polypeptide chain and complex must therefore provide for specific associations and for buffering against nonspecific associations which could have detrimental effects on catalytic activity.
Specific association m a y play a major role in localizing enzymes and other cell components in the proper cell structures. Allosteric interactions prob-
ably play an important role in specific association of polypeptide c h a i n s .4 8 , 4 9
5. ENZYME STRUCTURE AND THE REGULATION OF ENZYME FORMATION I t is likely t h a t whether or not an enzyme will be formed is in part determined by the interaction of specific D N A segments or messenger R N A segments with regulatory substances in the cytoplasm. Convincing evidence for the existence of D N A segments concerned with regulation, called "operator" regions, has been obtained in mutational studies with several enzyme s y s t e m s .5 0 - 5 3 I n studies on the synthesis of β-galactosidase in Escherichia coli it has been shown t h a t some mutations in the operator region also have an effect on the structure of the enzyme.5 0 I t is likely, therefore, t h a t in this case a segment of the amino acid sequence of the enzyme corresponds to a D N A segment t h a t is involved in the regulation of β-galactosidase synthesis and in the determination of the amino acid sequence of the protein.
II. G e n e t i c Control o f Protein Structure a n d Function
A . MUTATIONAL ALTERATION OF ENZYME ACTIVITY 1. INTRODUCTION
Most studies of the effects of mutation on enzyme activity, formation, and structure have been performed with induced mutants. Since a mutation is a relatively rare event, selective conditions usually must be employed in the isolation of m u t a n t strains. Therefore, the material t h a t has been ob
tained for study generally reflects the selective conditions imposed during isolation. I n microorganisms forward mutational alterations involving loss of function have usually been selected under conditions where only those strains with near complete loss of a given synthetic ability would be de
tected. Strains with a partial loss would rarely be recovered because they would be difficult to distinguish from members of the starting population.
This restriction is not always imposed ; with some systems detection meth
ods permit the recognition of m u t a n t s under nonselective conditions (e.g., alkaline phosphatase, β-galactosidase). I n recovering strains in which there is a gain in function as a result of mutation, selection is also em
ployed since there is undoubtedly a minimum level of synthetic ability which is requisite for an organism to be distinguishable from the popula
tion t h a t lacks the function. T h u s strains with a restored enzyme t h a t is only slightly active or in which only small amounts of active enzyme are formed might not be distinguishable from the original strain. I t is probable, therefore, than many—if not most—of the protein alterations t h a t do occur as a result of a change in the genetic material, go unnoticed.
8. GENE-ENZYME R E L A T I O N S H I P S 379
2 . QUALITATIVE E N Z Y M E ALTERATIONS RESULTING FROM M U T A T I O N S
Fortunately, a wide variety of enzymes have been examined in m u t a tional studies with microorganisms.2' 9 Although selective conditions are usually employed in m u t a n t isolation, nonselective conditions have been used in some c a s e s .5 4 , 5 5 I n studies of the effects of mutations within a single structural gene it has generally been observed t h a t two major
T A B L E I
EXAMPLES OF THE D I F F E R E N T T Y P E S OF PROTEIN ALTERATIONS T H A T H A V E B E E N DETECTED IN STUDIES OF G E N E - E N Z Y M E RELATIONSHIPS
Enzyme Alterations detected Reference
G l u t a m i c d e h y d r o g e n a s e (Neurospora)
C R M l e s s , u n u s u a l s u b s t r a t e r e q u i r e m e n t s , a c t i v a t i o n r e q u i r e d , s t a b i l i t y , i n a c t i v e C R M
5 7 , 7 2 - 7 4
/3-Galactoside (E. coli) C R M l e s s , s t a b i l i t y , a b i l i t y t o a g g r e g a t e , affinity for g a l a c t o s i d e s
5 0 , 56 , 76-77
T r y p t o p h a n s y n t h e t a s e (Neurospora)
C R M l e s s , i n a c t i v e C R M , p a r t i a l l y a c t i v e e n z y m e , i n h i b i t o r - s e n s i t i v e C R M
56 , 64, 78-82
T r y p t o p h a n s y n t h e t a s e (E. coli)
A p r o t e i n C R M l e s s , p a r t i a l l y a c t i v e e n z y m e , s t a b i l i t y , c h a r g e
5 9 , 6 2 , 6 3 , 6 8 , 8 3 , 84
Β p r o t e i n C R M l e s s , p a r t i a l l y a c t i v e e n z y m e , i n a c t i v e C R M
59 , 85
T y r o s i n a s e (Neurospora) s t a b i l i t y , c h a r g e 8 6 , 87 A l k a l i n e p h o s p h a t a s e
(E. coli)
C R M l e s s , i n a c t i v e C R M , p a r t i a l l y a c t i v e e n z y m e
1 1 , 54, 88
categories of m u t a n t types are recovered.5 2 , 5 4 , 5 6 - 5 9 M u t a n t s in the first category produce an altered form of an enzyme, called C R M (serologically cross-reacting material), but the protein is inactive or has altered enzymic activity. M u t a n t s in the second category appear to be totally devoid of this protein and the wild-type enzyme. Representatives of this second category
—the so-called CRMless mutants—have been examined in a number of systems (see Table I ) , using a variety of criteria which might be expected to detect a protein related to the normal protein, or a fragment of this protein. As yet, in no case has such a protein, or protein fragment, been
positively identified. With the alkaline phosphatase system, for example, isotopic labeling of the total protein of a CRMless m u t a n t , followed by subsequent fractionation, failed to detect any protein t h a t had the frac
tionation characteristics of the normal e n z y m e .6 0 Similar analyses with several t r y p t o p h a n synthetase A protein m u t a n t s also failed to detect an A protein in extracts of CRMless mutants. T h e production of an altered protein by some CRMless alkaline phosphatase m u t a n t s does seem likely, however, on the basis of complementation studies.6 1 The alkaline phos
phatase of E. coli is composed of two identical polypeptide subunits. Com
plementation studies carried out with C R M and CRMless m u t a n t s have shown t h a t alkaline phosphatase activity is detectable in some cases in which a CRMless m u t a n t is one partner in the complementation t e s t .6 1 Since a functional protein appears to be produced, it is likely t h a t the CRMless m u t a n t is capable of forming the alkaline phosphatase-polypep
tide chain but t h a t this chain cannot be recognized unless a chain with a dif
ferent alteration is available for the formation of a complex.
I n studies with t r y p t o p h a n synthetase m u t a n t s of E. coli somewhat different criteria have been employed in the examination of extracts of CRMless m u t a n t s for a protein resembling the wild-type protein.6 2 The tryptophan synthetase of E. coli consists of two separable protein subunits, designated A and B , each of which has slight activity in one of the reac
tions catalyzed at a rapid rate by the wild-type A-B complex.3 3 If a pro
tein were present in a CRMless extract, and it could combine with the normal second subunit, it could be detected by activity measurements or in competition studies. Experiments based on these detection methods have all been negative.6 2 Indirect evidence obtained with certain CRMless tryptophan synthetase m u t a n t s also suggests t h a t a protein is formed but it cannot be recognized. I n reversion studies with one CRMless m u t a n t it was shown t h a t a genetic change at a second site within the gene re
stored a functional e n z y m e .6 3 Although the enzyme activity could be dem
onstrated with cell suspensions, it was not possible to detect the protein in extracts. T h u s the protein is probably present in both the original CRMless m u t a n t and in the revertant but it is not recognizable.
Immunological studies with extracts of certain CRMless tryptophan synthetase m u t a n t s of Neurospora have led to the detection of a protein t h a t blocks the precipitation reaction between the wild-type enzyme and antienzyme.6 4 T h e nature of this protein, or protein fragment, has not been established so it cannot be stated t h a t it represents an altered form of the enzyme. Of interest in this regard is the finding t h a t tryptophan synthetase fragments obtained by proteolytic digestion of the enzyme also block the enzyme-antienzyme reaction.6 5
There are several explanations t h a t m a y be considered for CRMless
8. G E N E - E N Z Y M E R E L A T I O N S H I P S 381 mutants. First, it is conceivable t h a t a protein is formed but its structure is so altered t h a t it cannot be recognized by the detection techniques em
ployed. T h e complementing CRMless alkaline phosphatase m u t a n t s and the CRMless t r y p t o p h a n synthetase m u t a n t s of E. coli mentioned above are probably of this type. Second, it is also conceivable t h a t some amino acid substitutions affect protein stability so adversely t h a t the protein is inactivated and destroyed soon after formation. A third possible ex
planation would depend on whether there are nucleotide sequences in D N A which do not code for specific amino acids, so-called nonsense se
quences.6 6 A mutational alteration at a particular nucleotide position in a gene could result in the change of a meaningful coding unit (corresponding to an amino acid) to a nonsense coding unit. If a nonsense coding unit were present in a gene it is conceivable t h a t the corresponding nucleotide sequence in messenger R N A would prevent translation of the messenger into a continuous sequence of amino acids. This could lead to the formation of a fragment, or fragments, of the polypeptide chain rather t h a n the intact polypeptide chain, or the polypeptide fragments might not be re
leased from the template. If fragments are formed by some CRMless m u t a n t s it is not too surprising t h a t they have not been detected. A fourth possibility is t h a t the altered polypeptide chain cannot be released, or is released very slowly from the messenger-polyribosome complex. This possibility will be discussed in the section on the regulation of enzyme formation.
Most of the explanations mentioned above could apply in instances in which a mutation involved a single nucleotide substitution in D N A . I n addition, alteration of D N A by the addition or deletion of a single nucleo
tide in a gene could have m a n y of the same effects.6 7 A single nucleotide ad
dition or deletion in a gene could result in a shift of the coding unit reading frame with a consequent change of the amino acid sequence of a portion of the corresponding polypeptide chain. If a substantial portion of a polypep
tide chain had a different amino acid sequence, it probably could not be rec
ognized as being related to the unaltered protein. This explanation has been offered by Crick et al.67 to account for genetic findings obtained with acridine dye-induced m u t a n t s of phage T 4 and their revertants. Only a fraction of the CRMless m u t a n t s ,6 1 , 6 3»6 8 or any m u t a n t s6 9 - 7 1 isolated following t r e a t m e n t with other mutagenic agents, would appear to be of this type since m a n y are reverted by base analogs or alkylating agents.
M a n y different types of enzyme changes have been detected in studies with spontaneous and mutagen-induced m u t a n t s and revertants. Examples of the different effects of mutation on enzyme activity and properties are presented in Table I. I n the examples cited, changes affecting the active site seem quite common; however, as was pointed out earlier, this is
probably a reflection of the methods used in the isolation of the mutants.
Other alterations affect enzyme stability, sensitivity to naturally occurring substances *in the environment, the ability of subunits to associate to form an effective protein complex, the energy of activation of the enzyme, charge, etc. I t is apparent from these varied effects on enzyme activity and struc
ture t h a t the proper conformation and amino acid sequences of many dif
ferent regions of a protein are essential for physiological activity.
I n only a few of the cases cited is it known whether the altered protein differs from the normal protein by a single amino acid substitution. In fact, even in those cases in which single amino acid changes have been detected, it is virtually impossible to prove t h a t other changes did not occur. Nevertheless, in all cases t h a t have been thoroughly investigated, single-step mutational events have been shown to be associated with single amino acid replacements. When dealing with naturally occurring variant proteins, such as some human hemoglobins,1 0 and the tyrosinases of Neurospora,86^87 it might be expected t h a t several amino acid changes would be present in a variant protein. I n the extensive studies performed with h u m a n hemoglobins1 0 this does not appear to be the case.
3 . CHANGES IN ENZYME LEVELS AS A R E S U L T OF MUTATIONAL ALTERATIONS IN STRUCTURAL G E N E S
I n addition to alterations of protein structure resulting from mutation, effects on the formation of specific proteins are also observed. I n some cases these effects are due to changes in genie regions t h a t are not concerned with the primary structure of the protein, or proteins, t h a t are affected.
These will be considered in the section dealing with the regulation of enzyme formation.
I n other cases it has been observed t h a t mutations t h a t affect protein structure, or are mappable within the region of the gene concerned with protein structure, affect the amount of enzyme t h a t is formed. I n addition, these mutations often affect the formation of related enzymes whose con
trolling genes are located nearby. For example, several mutations in the genes concerned with arabinose utilization in E. coli affect the levels of many enzymes concerned with the metabolism of this sugar.8 9 Similarly, studies with β-galactosidase m u t a n t s (E. coli)50' 9 0 and tryptophan syn
thetase m u t a n t s (E. coli)59' 6 2>8 3 have shown t h a t the level of C R M formed is affected as well as the properties of the C R M . Furthermore, in both systems related enzymes controlled by neighboring genes were reduced in amount as a result of an alteration affecting β-galactosidase or t r y p t o phan synthetase. I t is clear t h a t an alteration in a genie region concerned with structure can have a profound effect of the formation of the corre
sponding enzyme and on enzymes controlled by neighboring genes as
8. GENE-ENZYME RELATIONSHIPS 3 8 3
well. Possible interpretations of these effects will be considered in the section dealing with the regulation of enzyme formation.
B . G E N E T I C CHANGES AND T H E I R E F F E C T S ON, AND RELATIONSHIP TO, PROTEIN PRIMARY STRUCTURE
1. PROTEIN PRIMARY STRUCTURE CHANGES ASSOCIATED WITH MUTATIONS
If mutation is defined as " a heritable change in the genetic material of an organism," then several categories of possible events must be con
sidered as mutations. At the nucleotide level mutations could involve substitution of one nucleotide for another, deletion of one or more nucleo
tides, or the addition of one or more nucleotides. Any of these changes would presumably be capable of affecting the structure of a protein. Other types of mutational alterations, such as translocations and inversions, would also be expected to have profound effects on protein structure.
I n no case is the specific nucleotide change associated with a mutational alteration known with any degree of certainty. I t is believed t h a t a very simple event is responsible for most mutational changes—probably a single nucleotide substitution. T h e principal basis for this conclusion is the fact t h a t the kinetics of m u t a n t production following mutagen treatment indi
cate t h a t single events are responsible for m u t a n t formation.6 9 Further
more, only single amino acid changes are generally observed associated with mutational alterations t h a t occur spontaneously or are induced by chemical m u t a g e n s ,1 3' 9 1 - 9 3 and often the changes are reversible.1 3
The amino acid differences t h a t have been detected in studies with m u t a n t forms of hemoglobin, tobacco mosaic virus, and the tryptophan synthetase A protein are summarized in Table I I . I n the latter case the mutational changes from active ^± inactive enzyme and stable ^± u n stable enzyme appear to be associated with single amino acid replace
m e n t s .1 3' 9 5 - 9 7
Among naturally occurring proteins t h a t differ by one or more amino acid residues it is not known, of course, how m a n y separate mutational events were responsible for each difference. Comparison of the amino acid replacements in naturally occurring variant forms of hemoglobin with those induced in tobacco mosaic virus protein and the t r y p t o p h a n syn
thetase A protein indicates t h a t several of the same amino acid changes are observed (Table I I ) . This fact would tend to favor the view t h a t single- step changes have been preserved in the hemoglobin variants.
As yet, primary structure changes have not been described in any in
stance in which an addition or deletion of a nucleotide is believed to have taken place, nor has it been demonstrated that a deletion leads to the alteration or loss of a segment of a protein. I n studies with phage T 4 an
rll m u t a n t has been isolated in which a deletion has removed segments of two functionally separate but adjacent regions of the rll gene.9 8 T h e results of complementation and mutation studies with the strain bearing this deletion have been interpreted as indicating t h a t the two presumed protein products of this genie region, which are believed to be distinct in non-
T A B L E I I
AMINO ACID DIFFERENCES BETWEEN THE NORMAL AND M U T A N T FORMS OF HEMOGLOBIN, TOBACCO MOSAIC V I R U S , AND TRYPTOPHAN
SYNTHETASE A P R O T E I N0
Amino acid change Protein Amino acid change Protein A l a -> G l u
Arg - > L y s Arg -> G l y Arg T h r Arg
A s p A s p A s p
Ser A l a G l y Ser A s p N H2 —> L y s A s p N H2 —> A r g A s p N H2 Ser G l u -> G l y G l u -> Val G l u —> L y s G l u -> G l u N H2
Glu -> A l a G l u N H2 -> Val G l y —> A s p G l y - Arg G l y -> G l u
T S G l y - > Val T S
T M V G l y -> C y s T S
T M V , T S H i s -> T y r H b
T S H i s —> A r g H b
T S l i e u -> T h r T M V
T M V H e u - > Val T M V
T M V H e u - » M e t T M V
T M V L e u —> Arg T M V
H b , T M V L e u —> P h e T M V
T M V P r o -> Ser T M V
T M V P r o —> L e u T M V
H b , T M V , T S Ser -> P h e T M V
H b , T S Ser —> L e u T M V
H b Ser —> Arg T S
H b T h r - > H e u T M V , T S
T S T h r -> M e t T M V
T M V T h r - * Ser T M V
H b , T S T y r -> C y s T S
T S V a l -> G l y T S
T S Val - » A l a T S
V a l - > G l u T S
a B a s e d o n d a t a t a b u l a t e d b y J u k e s9 4 a n d o n r e f e r e n c e s 1 2 , 1 3 , 101, 102.
K E Y : H b , h u m a n h e m o g l o b i n ; T S , t r y p t o p h a n s y n t h e t a s e A p r o t e i n ; T M V , t o b a c c o m o s a i c v i r u s p r o t e i n .
mutants, are joined together to form one polypeptide chain.9 8 This poly
peptide chain would presumably lack the amino acid sequence correspond
ing to the deleted region. Since the rll proteins have not been isolated as yet, it is not possible to verify this interpretation. There are several cases in which polypeptide chains or proteins have sufficiently similar primary structures to be interesting subjects for comparison. This is particularly true of the different chains of human hemoglobins.9 9 T h e alpha and beta chains have several similarities, and the gamma chain very closely re-
8. GENE-ENZYME RELATIONSHIPS 3 8 5
semblés the β-chain. I n view of the similarity of the amino acid sequences of these chains it seems likely t h a t one or more were derived from a common single-chain ancestral molecule." This presumably could come about by gene duplication followed by m a n y mutational alterations, with the gradual development of a new hemoglobin type.
2 . G E N E AND PROTEIN F I N E STRUCTURE RELATIONSHIPS
As mentioned previously, one of the basic assumptions in our thinking about the relationship between gene and protein is t h a t there is a linear correspondence between the two structures. Examinations of this as
sumption must of necessity be indirect at the present time. Although it is possible to determine the positions of amino acid replacements in proteins t h a t are associated with mutational events, it is not possible to determine the corresponding nucleotide changes in D N A , or their relative positions.
This obstacle stems from the fact t h a t it is not possible to isolate w h a t could be considered a D N A fragment corresponding to a single gene. I n attempting to test the concept of colinearity the best t h a t can be done a t the present time is to compare a fine structure genetic m a p with the primary structure of the corresponding protein. A number of gene-protein systems are being studied with this purpose in m i n d .1 1-1 2 , 5 4>1 0 0 T h e findings ob
tained to date demonstrate a direct relationship between the locations of alterations on a genetic m a p and the positions of amino acid substitutions in the corresponding p r o t e i n ,1 1'1 2 > 9 5'9 6 and establish the existence of a colinear relationship between gene structure and protein s t r u c t u r e .1 2
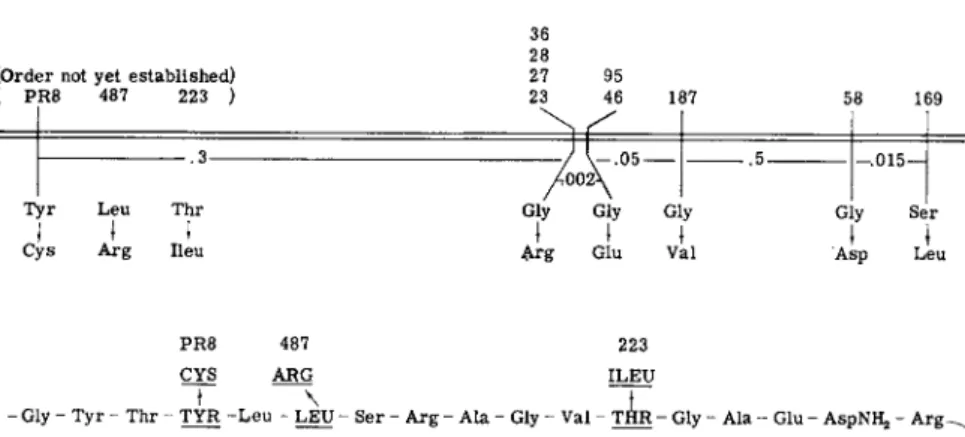
I n studies with the A protein of E. coli t r y p t o p h a n synthetase several cases have been found in which there is a correspondence between the positions on the genetic m a p at which mutations occur and the positions in the protein a t which amino acid replacements are detected (Fig. 1 ) ; i.e., alterations near one another on the genetic m a p lead to amino acid replacements near one another in the p r o t e i n .1 2 , 9 5 > 9 6 T h e same relationship has been demonstrated in studies with the alkaline phosphatase of E. coli.11 I n addition, one segment of the t r y p t o p h a n synthetase A protein has been sequenced1 2' 1 0 1»1 0 2 (Fig. 1 ) and the order of the positions of amino acid replacements in this segment is the same as the order of the mutational sites in the A gene. Furthermore, if the known lengths of the A gene ( 3 . 7 recombination units) and the A protein ( 2 8 0 amino acid residues) are considered, the distances between the positions of amino acid replacements in the protein are in fair agreement with recombination d a t a .1 2 , 1 0 1 »1 0 2 These findings provide strong support for the concept of colinearity of gene structure and protein structure.
(Order not yet established) ( PR8 487 223 )
.3 Tyr Leu Thr
ι
ι tCys Arg lieu
23 46 187 36 28
27 95 23 46 187
.5 Gly Gly Gly
I I I Arg Glu Val
58 169 .015—
Gly Ser
1 I
Asp Leu
PR8 487 223 CYS ARG ILEU
- Gly - Tyr - Thr - TYR - L e u - LEU - Ser - Arg - Ala - Gly - Val - T H R - Gly - Ala - Glu - AspNHj, - Arë~^
Ala - Ala - (Pro, Leu) - Leu - (Asp, Ala, His, Val) - Leu - Lys - Leu - Lys - Glu - Tyr - A s p N ^ - A l a - ^ Ala - Pro - Pro - Leu - GluNH,, - GLY - Phe - GLY - Ser - lieu - Ala - Pro - (Asp, Glu, Val) - L y s ^
ARG GLU VAL
(Alajlleu) - (Asp, Ser, GLY3Ala4Ileu) - SER - (Ala, Val, lieu) - Lys -
ASP LEU i ί
58 169
FIG. 1 . E v i d e n c e of a colinear relationship b e t w e e n gene structure and protein struc
ture. T h e genetic m a p of a s e g m e n t of t h e A gene is presented a b o v e , with the a m i n o acid replacement characteristic of each m u t a n t . T h e corresponding s e g m e n t of the A protein and t h e positions of t h e changes are shown below. B a s e d o n p u b l i s h e d1 2 , 9 5 - 9 7 and unpublished studies of Y a n o f s k y , Carlton, Guest, Helinski, and H e n n i n g .
3. PRIMARY STRUCTURE CHANGES ASSOCIATED WITH REVERSION E V E N T S
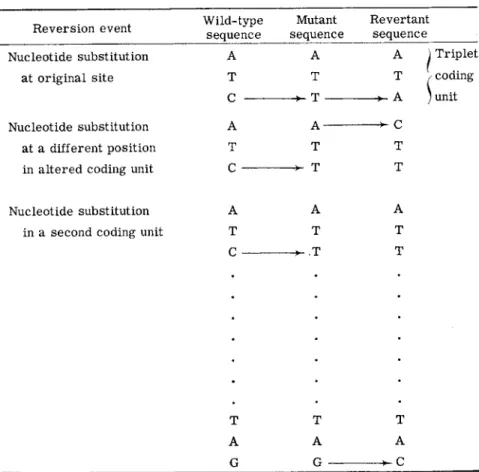
Reverse mutations have also been studied in examinations of the rela
tionship between mutational changes and protein primary structure changes. Figure 2 presents the three possible types of reversion events t h a t could involve single nucleotide substitutions. The substitution could be at the same position as the original nucleotide change, or at another nucleotide position in the same amino acid coding unit. I n either case the amino acid responsible for inactivity of the corresponding m u t a n t protein would be replaced. T h e substitution could also be in an amino acid coding unit other t h a n the one changed by the original mutation. I n the latter case it would be expected t h a t the corresponding revertant protein would have two amino acid differences from the wild-type protein. I t would have one change
8. G E N E - E N Z Y M E R E L A T I O N S H I P S 387 identical to t h a t in the protein of the original m u t a n t strain, and a second change elsewhere in the protein. This second alteration would presumably compensate in some way for the effects of the original amino acid replace
ment.
Reversion event Wild-type sequence
Mutant sequence
Revertant sequence 1. Nucleotide substitution
at original site
2 . Nucleotide substitution at a different position in altered coding unit
A Τ C A Τ C
A Τ Τ A- Τ Τ
A Τ A C Τ
τ
) Triplet / coding
; unit
3 . Nucleotide substitution in a second coding unit
A Τ C
Τ A G
A Τ Τ
Τ A G
A Τ Τ
Τ Α
FIG. 2 . T h e three t y p e s of reversion e v e n t s resulting from single n u c l e o t i d e substi
tutions.
I n studies of reversion, inasmuch as the selective conditions employed simply require the restoration of a function lacking in a mutant, it would be expected t h a t m a n y different primary structure changes would be represented among revertant strains recovered from any one m u t a n t . The amino acid changes t h a t could occur would obviously be limited by the original mutational alteration, since only those new changes t h a t could restore a functional protein would be detected. Furthermore, if each reversion event involved the substitution of only one nucleotide, the
composition and sequence of t h a t m u t a n t coding unit would restrict the possible amino acid changes.
Extensive reversion analyses have been performed with two A protein m u t a n t s (tryptophan synthetase) .1 3 , 6 3» 9 7 T h e amino acid replacements in the A proteins of these m u t a n t s are at the same position in the protein ; either arginine (A-23) or glutamic acid (A-46) replaces g l y c i n e .1 3 , 9 5 , 9 6
Strain A-23 has a very complex reversion pattern ; it gives rise to revertants which are indistinguishable from the wild type (in terms of most of their properties) and several classes of revertants, called partial revertants,
which form a functional A protein, but the protein is not as active catalyti- cally as the wild-type A p r o t e i n .6 3 , 6 8 Analyses of the A proteins of members of the first group have shown t h a t in addition to reversions restoring the wild-type amino acid, glycine, arginine is replaced by s e r i n e1 3 , 9 7 (Fig. 3 ) .
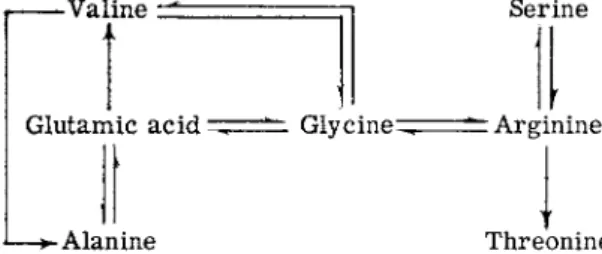
-Valine 1t Serine
Glutamic a c i d ^ = = ^ G l y c i n e ^ " Arginine
J— A l a n i n e Threonine
FIG. 3. A m i n o acid replacements at o n e position in the t r y p t o p h a n s y n t h e t a s e A protein. T h e w i l d - t y p e protein has glycine at this position. T h e A proteins with valine, alanine, serine, or threonine at this position are functional while the proteins with arginine or glutamic acid are inactive.
This serine-containing protein appears to be as active enzymically as the glycine protein. M a n y revertant proteins have been examined in these studies and only the two amino acids have been detected.1 3 Only one member of the second group, the partial revertants, has been examined and the A protein of this revertant has a threonine residue instead of the arginine residue.1 3 The other m u t a n t examined, strain A-46, also has a complex reversion pattern (Fig. 3). I t gives rise to two different partial revertant types and revertants which are indistinguishable from the wild t y p e .1 3 , 6 3 , 6 8 Analyses of the A proteins of members of this latter category have shown t h a t either glycine or alanine can replace glutamic acid.1 3 , 9 7
The alanine protein appears to be similar to the glycine protein in func
tional activity. Representatives of the two partial revertant types have been analyzed; one type forms an A protein with valine instead of glu
tamic acid at the critical position in the A protein.9 7 T h e valine protein is only slightly active enzymically. T h e second partial revertant type has been shown to have a primary structure change a t a second position
8. G E N E - E N Z Y M E R E L A T I O N S H I P S 389 in the p r o t e i n .1 0 3 T h e original m u t a n t change—glycine to glutamic acid—
is still evident in the protein of this strain, but there is a second change, in a different peptide, of a tyrosine residue to a cysteine r e s i d u e .1 0 3 This cysteine residue must in some manner compensate for the effects of the presence of the glutamic acid residue elsewhere in the protein. Recombina
tion experiments with this partial revertant have permitted the isolation of a strain with the genetic change responsible for the tyrosine —» cysteine replacement b u t lacking the A-46 alteration; i.e., glycine rather t h a n glutamic acid was present at the other relevant position in the protein.
This protein was enzymically inactive. Thus, both changes must be present in the same protein molecule for activity. Amino acid replacement analyses were carried out with approximately 30 revertants from the glutamic m u t a n t and only the four types of changes mentioned were detected.1 3 Second-site reversion (reversion at a second position within a gene) has also been studied in relation to the mutagenic effects of acridine d y e s .6 7 T h e interpretation of these effects will be discussed presently.
The findings in the studies with the two A protein m u t a n t s illustrate very clearly the restrictions on reversion possibilities t h a t are imposed by the composition of the m u t a n t coding unit. Clearly, at least five amino acids—glycine, alanine, serine, threonine, and valine—are functional at one position in the protein b u t the alanine and valine coding units can only be derived from the glutamic acid coding unit, and the serine and threonine coding units can only be derived from the arginine coding unit.
These findings suggest t h a t each mutational change involves a single nucleotide change and, therefore, t h a t the nucleotide composition and sequence of the critical coding unit in the m u t a n t gene limits the reversion possibilities.
I n one other system, the alkaline phosphatase of E. coli, evidence has also been obtained suggesting t h a t an amino acid change at a second posi
tion in the protein compensates for the effect of the primary amino acid replacement.1 1 Here, too, the second change leads to an inactive protein in an otherwise unaltered protein.
As mentioned previously, a mutational event might involve an addition or a deletion of a single nucleotide rather t h a n a substitution. I n such cases reversion would probably involve the opposite change—addition for deletion, and deletion for addition.6 7 I t is, of course, also conceivable t h a t a deletion or addition near one end of a gene could be reversed by nucleotide substitutions in this region.
Genetic and physicochemical studies with acridine dyes suggest t h a t acridine mutagenesis m a y involve the addition or deletion of single nucleo
tides.6 7' 1 0 4 Furthermore, analyses of acridine-induced rll m u t a n t s of bacteriophage T 4 and their revertants suggest t h a t translation of mes-
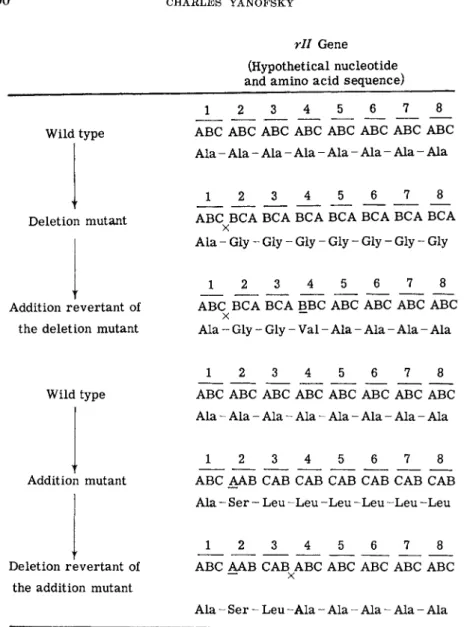
rll Gene (Hypothetical nucleotide and amino a c i d sequence)
Wild type
Deletion mutant
Addition revertant of the deletion mutant
1 6 8
ABC ABC ABC ABC ABC ABC ABC ABC A l a - Ala - Ala - Ala - Ala - Ala - Ala - Ala
1 8
ABC BCA BCA BCA BCA BCA BCA BCA χ
A l a - Gly - Gly - Gly - Gly - Gly - Gly - Gly
1 2 3 4 5 6
J_
8ABC BCA BCA BBC ABC ABC ABC ABC χ ~~
Ala - Gly - Gly - Val - Ala - Ala - Ala - Ala
Wild type
Addition mutant
Deletion revertant of the addition mutant
1 2 3 4 5 6 7 8 ABC ABC ABC ABC ABC ABC ABC ABC Ala - Ala - Ala - Ala - Ala - Ala - Ala - Ala
J 2 3 _ 4 5 6 7 8
ABC AAB CAB CAB CAB CAB CAB CAB Ala - Ser - Leu - L e u - L e u - L e u - L e u - L e u
1 8
ABC AAB CAB ABC ABC ABC ABC ABC
Ala - S e r - Leu - A l a - Ala - Ala - Ala - Ala
FIG. 4. T h e effect of single nucleotide additions or deletions o n t h e c o m p o s i t i o n of the coding units in t h e rll gene of phage T 4 .6 7 Subscript letter χ indicates nucleotide d e l e t e d ; underlined letter indicates nucleotide a d d e d ; a bar under a n u m b e r ( 1 ) re
fers t o a coding triplet. I n each case reversion restores t h e original triplets except for the region b e t w e e n t h e t w o changes, if t h e sequence is read from a fixed starting point.
8. GENE-ENZYME RELATIONSHIPS 3 9 1
senger R N A proceeds from a fixed starting point and t h a t each sequence of three nucleotides corresponds to an amino acid.6 7 On the basis of the interpretation of the results of these studies (Fig. 4) it would be expected t h a t a single nucleotide addition or deletion in a gene would lead to a change in the amino acid sequence of a protein, starting from the position corresponding to the position of the nucleotide addition or deletion in the gene. Reversion would involve the opposite change, e.g., addition for dele
tion mutant, and would restore the normal amino acid sequence except for the region of the protein corresponding to the region between the sites of the nucleotide changes. Acridine-induced phage m u t a n t s t h a t lack a functional lysozyme should be excellent material with which to test these expectations.
C . NUCLEOTIDE COMPOSITION AND SEQUENCE OF CODING U N I T S
1. NUCLEOTIDE-AMINO A C I D RELATIONSHIPS
T h e nature of the coding relationships between the nucleotides of D N A and the amino acids of proteins has been a subject of considerable theo
retical and experimental attention over the past ten years. A number of codes have been proposed in which nucleotides on both strands of D N A are involved in specifying amino acid sequence information.1 0 5 I n view of recent s t u d i e s ,8'1 6 - 2 1 which suggest t h a t the actual translation is performed on single-stranded messenger R N A ' s by the ribosomes, and t h a t messenger R N A has the complementary structure of only one of the strands of D N A ,1 6 - 1 8 the coding problem would appear to be reduced to a consider
ation of possible sequences of nucleotides on one strand t h a t could code for 20 different amino acids.
A code involving only two nucleotides per amino acid seems very un
likely. T w e n t y coding units are needed for the common amino acids in proteins and there are only 1 6 two-nucleotide combinations. Furthermore, the available data suggest t h a t there is appreciable degeneracy of the c o d e1 0 6 - 1 0 9, i.e., there are several nucleotide sequences (coding units) for each amino acid. Nevertheless, a mixed code containing some coding units with two nucleotides is certainly not ruled out by any existing data. Triplet codes, i.e., codes with three nucleotides per amino acid coding unit, have been seriously considered by several investigators.6 6 , 6 7'1 0 6-1 0 9 Overlapping codes involving three nucleotides were excluded1 1 0 on the basis of the consideration t h a t overlapping would restrict the amino acids t h a t could be adjacent to one another. There does not appear to be any such restric
tion as far as can be determined from known amino acid sequences in proteins. This argument is no longer applicable, however, in view of the recent evidence which suggests t h a t there is appreciable degeneracy of
the code. With a degenerate overlapping code it would be possible to have m a n y combinations of amino acids adjacent to one another. More con
vincing evidence t h a t is inconsistent with overlapping codes has been ob
tained in mutational studies. I n no case have adjacent amino acids in a protein been changed by a single mutational event.1 3' 9 3 > 1 1 1 Furthermore, in one study of mutational alteration of protein primary structure any one of seven different amino acids could occupy one position in a protein.1 3 I n each of these cases the amino acids on either side of this position in the protein were u n c h a n g e d .1 3 , 1 1 2 Obviously not all of these changes could be due to mutational alterations at the same nucleotide position; never
theless, there was no change of either of the adjacent amino acids. A code in which a nucleotide triplet codes for each amino acid and in which there is no overlapping of nucleotides in adjacent coding units would appear to be the simplest code t h a t would provide sufficient combinations to specify several coding units for each of the 20 amino acids.
One serious problem which arises in nonoverlapping, degenerate triplet codes is the recognition of the separation between adjacent coding units.
This problem was considered initially by Crick et al.66 before evidence of degeneracy was presented, and it was proposed t h a t there might be certain triplets, nonsense triplets, which did not code. Crick et αΖ.6 6 showed t h a t if most triplets were of the nonsense type several triplet codes could be derived, each containing only twenty meaningful coding units. I n each of these codes all overlaps of the twenty coding units were nonsense. An alternative, also proposed by Crick and co-workers,6 7 which is consistent with degeneracy of the code, is t h a t the nucleotide sequence in messenger R N A is read (translated) from a fixed starting point, three nucleotides a t a time (Fig. 4 ) . According to this interpretation it would be possible to have as m a n y as 64 different meaningful triplets. Since the reading would start from a fixed point and involve three nucleotides at a time, each coding unit would be marked off from the preceding and succeeding ones. Codes involv
ing four nucleotide coding units have also been considered.1 1 3 With four nucleotides per amino acid, m a n y more meaningful and nonsense nucleotide sequences could be written. I t is obvious t h a t there are m a n y possible codes, and we do not yet know whether every amino acid is coded by the same number of nucleotides. Certainly, it would not be too surprising if there were something unusual about the coding units t h a t correspond to the first or last amino acid in a protein.
An approach to deciphering the genetic code has recently been discovered in studies with synthetic messenger RNA's. Nirenberg and M a t t h a e i ,1 1 4 while examining the effects of ribonucleic acids on the incorporation of labeled amino acids into proteins in vitro, observed t h a t synthetic poly
ribonucleotides would stimulate the incorporation of labeled amino acids
8. G E N E - E N Z Y M E R E L A T I O N S H I P S 393 into a protein product. I t was further noted t h a t when polyuridylic acid was added phenylalanine was the predominant labeled amino acid t h a t was incorporated into polypeptides.1 1 4 This initial finding suggested t h a t the R N A coding unit for phenylalanine involved some sequence of uridylic acid residues. Extension of this observation by Nirenberg and co-work
e r s ,1 0 6 , 1 0 8 and Ochoa and c o - w o r k e r s1 0 7 , 1 0 9 , 1 1 5 has led to the designation of specific coding units for all of the amino acids (Table I I I ) . Using syn-
T A B L E I I I
CODING U N I T S DETECTED WITH SYNTHETIC POLYRIBONUCLEOTIDES"
Amino acid Coding unit
A l a n i n e U C G U C G A C G —
A r g i n i n e U C G C C G G A A —
A s p a r t i c a c i d G U A A C A G C A — •
A s p a r a g i n e U A C U A A C A A
—
C y s t e i n e U U G — —
G l u t a m i c a c i d U A G A A G A A C
G l u t a m i n e U A C A G G A A C —
G l y c i n e U G G C G G A G G —
H i s t i d i n e A U C A C C — —
I s o l e u c i n e U U A U A A U A C —
L e u c i n e U U U U U A U U C U U G
L y s i n e U A A A A A A A C A A G
M e t h i o n i n e U G A — —
—•
P h e n y l a l a n i n e U U U u c u — . —
P r o l i n e U C C c c c C C A C C G
S e r i n e e c u c u u U C G A C G
T h r e o n i n e U C A C A C C A A C G C
T r y p t o p h a n U G G U C G —
—
T y r o s i n e U U A U C G
—
— •V a l i n e U U G
° T a k e n f r o m t h e c o m p i l a t i o n b y J u k e s .9 4
thetic polyribonucleotides containing two or three of the nucleotide com
ponents of R N A , in different combinations, it was shown t h a t the specificity of amino acid incorporation was markedly affected by the composition of the polymer t h a t was provided. B y employing polynucleotides with dif
ferent ratios of two component nucleotides the relative incorporation of different amino acids was a f f e c t e d .1 0 8 , 1 1 5 T h e conclusion from these ex
periments was t h a t the coding units corresponding to amino acids t h a t were incorporated to a great extent contained two nucleotides of the major nu
cleotide component of the polyribonucleotide, while amino acids t h a t were incorporated poorly were coded by sequences in which the minority nucleo
tide was the predominant component. I t was not possible from these studies
to establish the number of nucleotides corresponding to each amino acid, but the quantitative data on relative amino acid incorporation and relative base composition of the R N A messenger was most readily explained by a triplet c o d e .1 0 8»1 1 5
I n these studies it was observed t h a t polyribonucleotides containing different nucleotides frequently stimulated the incorporation of the same amino a c i d .1 0 6 - 1 0 9 This finding led to the designation of several coding units for each of the amino acids and established t h a t the code was de
generate in the in vitro system. At the present time most of the 64 theoreti
cally possible triplet coding units have been i d e n t i f i e d .1 0 6 - 1 0 9 As the list of identified coding units grew, an unanticipated relationship between differ
ent coding units for the same amino acid became apparent. I n m a n y cases two or more coding units for the same amino acid had two nucleotides in c o m m o n .1 0 6 - 1 0 9 This relationship has been interpretated in several w a y s ,9 4 , 1 1 6 including the p r o p o s a l1 1 6 t h a t the two shared nucleotides m a y occupy the same positions in different codings units, and t h a t in the third position the two purines are equivalent in coding and the two pyrimidines are equivalent in coding. One possible implication of this suggestion is t h a t a given transfer R N A m a y pair with two different messenger R N A triplets.
Whether or not this interpretation is correct remains to be determined.
Evidence of a different nature also suggests t h a t the code consists of triplet coding units (Fig. 4 ) . I n the previously mentioned studies by Crick and co-workers6 7 with acridine-induced rll m u t a n t s of phage T 4 it was observed t h a t most of the revertants obtained from such m u t a n t s were second-site revertants; i.e., the reversion event occurred at a second site within the rll gene. Examination of the m u t a n t s and the second-site re
vertants led to two surprising findings; (1) phage with the second-site change free of the primary mutational alteration had the m u t a n t pheno
type, and (2) the original m u t a n t s and the revertants could be grouped into two categories. These were arbitrarily designated + and —. If a 4- altera
tion were combined with a — alteration, the phenotype of the doubly altered strain was often wild-type. Thus + and — appeared to represent two different types of alterations of the genetic material. As was mentioned previously, Crick et al.67 interpreted these observations in terms of addi
tions and deletions of single nucleotides. The + and — types would thus represent strains in which the mutation involved an addition or deletion of a nucleotide. If the code were triplet and read from a fixed starting point three nucleotides at a time, the effects of a single nucleotide deletion could only be reversed by adding a nucleotide at the original position or at another position in the same gene. T h e amino acids in between the two points of mutation in a + — strain would not necessarily be the same as those in the unmutated protein (Fig. 4). Since certain amino acid se-