Óbuda University
PhD thesis
Dynamic Execution of Scientific Workflows by
Eszter Kail Supervisors:
Miklós Kozlovszky Péter Kacsuk
Applied Informatics Doctoral School
Budapest, 2016
Statement
I, Eszter Kail, hereby declare that I have written this PhD thesis myself, and have only used sources that have been explicitly cited herein. Every part that has been borrowed from external sources (either verbatim, or reworded but with essentially the same content) is unambiguously denoted as such, with a reference to the original source.
Contents
List of Figures vi
List of Tables viii
1 Introduction 1
1.1 Motivation . . . 2
1.1.1 Workflow structure and fault tolerance . . . 2
1.1.2 Adaptive and user-steered execution . . . 3
1.2 Objectives . . . 3
1.2.1 Workflow structure and fault tolerance . . . 3
1.2.2 Adjusting the checkpointing interval . . . 4
1.2.3 Adaptive and user-steered execution . . . 4
1.3 Methodology . . . 4
1.4 Dissertation Organization . . . 5
2 Dynamic execution of Scientific Workflows 6 2.1 Scientific Workflow Life Cycle . . . 6
2.2 Definition of dynamism . . . 8
2.3 Taxonomy of dynamism . . . 8
2.4 Aspects of dynamism. . . 11
2.5 Fault tolerance . . . 11
2.6 Faults, failures and Fault tolerance . . . 12
2.7 Taxonomy of Fault Tolerant methods. . . 13
2.8 SWfMS . . . 15
2.8.1 Askalon . . . 16
2.8.2 Pegasus . . . 16
2.8.3 gUSE/WS-PGRADE. . . 17
2.8.4 Triana . . . 18
2.8.5 Kepler . . . 18
2.8.6 Taverna . . . 19
2.9 Provenance . . . 19
3 Workflow Structure Analysis 21 3.1 Workflow structure investigations - State of the art . . . 22
3.2 Fault sensitivity analysis . . . 23
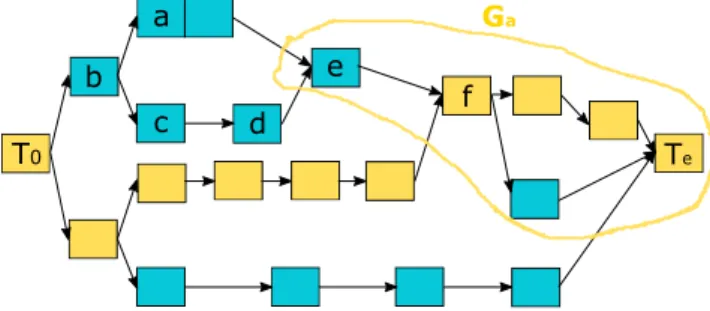
3.3 Determining the influenced zones of a task . . . 28
3.3.1 Calculating the sensitivity index and influenced zones of simple workflow graphs . . . 28
3.3.2 Calculating the Influenced Zones of complex graphs containing high number of vertices . . . 30
3.4 Investigating the possible values of the Sensitivity Index and the Time Sensitivity of a workflow model . . . 35
3.5 Classification of the workflows concerning the sensitivity index and flexi- bility index . . . 39
3.6 Conclusion . . . 40
3.7 New Scientific Results . . . 40
4 Adjusting checkpointing interval to flexibility parameter 42 4.1 Related work . . . 43
4.2 The model. . . 46
4.2.1 General notation . . . 46
4.2.2 Environmental Conditions . . . 47
4.3 Static Wsb algorithm. . . 47
4.3.1 Large flexibility parameter. . . 49
4.3.2 Adjusting the checkpointing interval . . . 49
4.3.3 Proof of the usability of the algorithm . . . 51
4.3.4 The operation of the Wsb algorithm . . . 51
4.4 Adaptive Wsb algorithm . . . 52
4.4.1 Calculating the flexibility zone for complex graphs with high num- ber of vertices and edges . . . 55
4.5 Results. . . 56
4.5.1 Theoretical results . . . 56
4.5.2 Comparing the Wsb and AWsb algorithms to the optimal check- pointing . . . 57
4.5.3 Tests with random workflows . . . 60
4.5.4 Remarks on our work . . . 62
4.6 Conclusion and future work . . . 63
4.6.1 New Scientific Results . . . 63
5 Provenance based adaptive execution and user-steering 65 5.1 Related Work . . . 65
5.1.1 Interoperability . . . 65
5.1.2 User-steering . . . 66
5.1.3 Provenance based debugging, steering, adaptive execution . . . 68
5.2 iPoints . . . 68
5.2.1 Structure and Functionality of an iPoint . . . 69
5.2.2 Designator Actions (DA) . . . 70
5.2.3 eXecutable Actions (XA) . . . 70
5.2.4 Types of iPoints . . . 71
5.2.5 The Placement of iPoints . . . 72
5.2.6 iPoint Language Support . . . 72
5.2.7 Benefits of using iPoints . . . 74
5.3 IWIR . . . 75
5.3.1 IWIR Introduction . . . 75
5.3.2 Basic building blocks of IWIR. . . 76
5.4 Specifications of iPoints in IWIR . . . 78
5.4.1 Provenance Query . . . 78
5.4.2 Time management Functions . . . 79
5.4.3 eXecutable Actions . . . 79
5.4.4 The iPoint compund tasks . . . 80
5.5 Conclusion and future directions . . . 81
5.5.1 New Scientific Results . . . 82
6 Conclusion 84
List of Figures
2.1 Simple workflow with four tasks. . . 7
3.1 A sample workflow graph with homogeneous tasks . . . 27
3.2 A 1-time-unit-long delay occurring during the execution of task a . . . 27
3.3 A 2-time-unit-long delay occurring during the execution of task a . . . 27
3.4 simple graph model containing 3 tasks . . . 29
3.5 Simple graph model containing 2 different paths . . . 30
3.6 An example workflow with one critical path . . . 32
3.7 An example workflow with one critical path . . . 33
3.8 Effect of a one-time-unit delay during the execution of task a . . . 33
3.9 Effect of a two-time-unit delay during the execution of task a . . . 33
3.10 A most flexible workflow with a T S = 59 . . . 37
3.11 A most sensitive workflow with a T S = 58 . . . 38
3.12 An example workflow for a most sensitive workflow with T S= 119 . . . 39
4.1 Total process time as a function of the number of checkpoints . . . 50
4.2 Chartflow diagram of the Wsb static algorithm . . . 52
4.3 A sample workflow with homogeneous tasks . . . 53
4.4 A two time-unit-long delay during execution of task b . . . 54
4.5 Chartflow diagram of the AWsb adaptive algorithm . . . 55
4.6 Most flexible workflow . . . 58
4.7 Most sensitive workflow . . . 59
4.8 Sample workflow with 8 tasks.. . . 60
4.9 Results of our static algorithm . . . 62
5.1 An iPoint . . . 69
5.2 iPoint placement before data arrival or after data producement . . . 72
5.3 iPoint placement before submission, or after completion . . . 73
5.4 Process of Provenance Query . . . 73
5.5 Process of Time Management . . . 74
5.6 Abstract and concrete layers in the fine-grained interoperability framework architecture. (Plankensteiner 2013) . . . 75
List of Tables
2.1 Notation of the variables of the Wsb and AWsb algorithm . . . 14
4.1 Notation of the variables of the Wsb and AWsb algorithm . . . 46
4.2 Simulation results for max. rigid and max flex. workflows . . . 57
4.3 Simulation results for sample workflow (Fig. 4.8) . . . 61
4.4 Comparison of number of checkpoints (X) and the total wallclock time (W) in the five scenarios . . . 61
Abstract
With the increase in computational capacity more and more scientific experiments are conducted on parallel and distributed computing infrastructures. These in silico experiments, represented with scientific workflows, are long-running and often time constrained computations. To successfully terminate them within soft or hard deadlines dynamic execution environment is indispensable.
The first and second thesis group deals with the topic of one of the main aspect of dynamism, namely fault tolerance. This issue is long standing in focus due to the increasing number of in silico experiments, and the number of faults that can cause the workflow to fail or to successfully terminate only after the deadline.
In the first thesis group I have investigated this topic from a workflow structure perspective. Within this thesis group I have introduced the influenced zone of a failure concerning the workflow model, and based on this concept I have formulated the sensitivity index of a scientific workflow. According to this index I gave a classification of scientific workflow models.
In the second thesis group based on the results obtained from the first thesis group I have introduced a novel (Wsb) checkpointing algorithm, which can reduce the overhead of the checkpointing, compared to a method that was optimized concerning the execution time, without negatively affecting the total wallclock time of the workflow. I have also showed that this algorithm can be effectively used in a dynamically changing environment.
The third thesis group also considers a problem on a recently emerged topic: it investigates the possibility and requirements of provenance based adaptive execution and user-steering. In this thesis group I have introduced special control points (iPoints), where the system or the user can take over the control and based on provenance information the execution may deviate from the workflow model. I have specified these iPoints in IWIR which was targeted to promote interoperability between existing workflow representations.
Absztrakt
A számítási kapacitás növekedésével egyre több tudományos kisérlet végrehajtása történik párhuzamos és elosztott számítási erőforrásokon. Ezek az úgynevezett in sil- ico kísérletek általában hosszú, de eredményeik érvényességét tekintve időben korláto- zott futásidejű számítások. Tekintettel a komplex erőforrásokra és a gyakori, valamint széleskörű hibákra a határidőn belüli sikeres lefutás érdekében a dinamikus futási környezet biztosítása nélkülözhetetlen.
Az első és második téziscsoport a dinamizmus egyik fő területével, a hibatűrő me- chanizmusokkal foglakozik. Ez a problémakör hosszú ideje a kutatások középpontjában áll köszönhetően az in silico kisérletek egyre szélesebb körű elterjedésének, valamint a gyakori és változatos hibák okozta sikertelen vagy határidőn túl befejeződő munkafolyamat futtatásoknak.
Az első téziscsoport a problémát a munkafolyamatokat leíró gráfok struktúrája felől vizsgálja. Bevezettem egy hiba hatáskörének fogalmát, majd a fogalomra alapozva ki- dolgoztam a munkafolyamatra jellemző, érzékenységi indexet. Az index értékei alapján osztályoztam a különböző munkafolyamat gráfokat.
A második téziscsoportban az első téziscsoport eredményeire támaszkodva kidolgoz- tam egy statikus (Wsb) ellenőrzőpont algoritmust, mely a futási időre optimalizált algoritmushoz képest csökkenti az ellenőrzőpontok készítésének költségét, anélkül, hogy a lefutási időt megnövelné. Munkám során megmutattam, hogy az algoritmus dinamikusan változó környezetben is hatékonyan működik.
A harmadik téziscsoport egy, az utóbbi időben jelentőssé vált problémával foglalkozik.
A provenance alapú adaptív futás, illetve a felhasználó általi vezérlés lehetőségét és követelményeit vizsgálja. A téziscsoport keretein belül olyan vezérlési pontokat (iPoint) dolgoztam ki, ahol az irányítást átveheti a rendszer vagy a felhasználó és a provenance adatbázisban tátolt adatok alapján megváltoztathatja tervezett futását. A vezérlési pontokat egy munkafolyamat leíró köztes nyelven (IWIR) specifikáltam.
List of abbreviations
Abbreviation Meaning
SWf Scientific Workflow
SWfMS Scientific Workflow Management System HPC High Performance Computing Infrastructures
OPM Open Provenance Model
DA Designator Action
XA eXecutable Action
DAG Directed Acyclic Graph
PD Provenance Database
DFS Depth-First Search
IWIR Interoperable Workflow Intermediate Representation
W3C World Wide Web Consortium
Wsb Workflow structure based
AWsb Adaptive Workflow structure based
RBE Rule Based Engine
iPoint intervention Point SLA Service-level Agreement
VM Virtual Machine
WFLC Workflow Life Cycle
1 Introduction
The increase of the computational capacity and also the widespread usage of computation as a service enabled complex scientific experiments conducted in laboratories to be transformed to in silico experiments executed on local and remote resources. In general these in silico experiments aim to test a hypothesis, to derive a summary, to search for patterns or simply to analyze the mutual effects of the various conditions. Scientific workflows are widely accepted tools in almost every research field (physics, astronomy, biology, earthquake science, etc.) to describe and to simplify the abstraction and to orchestrate the execution of these complex scientific experiments.
A scientific workflow is composed of computational steps that are executed in sequential order or parallel wise determined by some kind of dependency factors. We call these computational steps tasks or jobs, which can be data intensive and complex computations.
A task may have input and output ports where the input ports consume data and the output ports produce data. Data produced by an output port is forwarded through outgoing edges to the input ports of subsequent tasks. Mostly we differentiate data flow or control flow oriented scientific workflows. While in the former one the data dependency determines the real execution path of the individual computational steps and data movement path, in the latter one there is an explicit task or job precedence defined.
Scientific workflows are in general data and compute intensive thus they usually require parallel and distributed High Performance Computing Infrastructures (HPC), such as clusters, grids, supercomputers and clouds to be executed. These infrastructures consist of numerous and heterogeneous resources. To hide the complexity of the underlying low-level, heterogeneous architecture Scientific Workfow Managements Systems (SWfMS) have emerged in the past two decays. SWfMs tend to manage the execution-specific hardware types, technologies and protocols whilst providing user-friendly, convenient interfaces to the various user types with different knowledge about the technical details.
However, this user-friendly management system hides a complex thus, an error prone architecture, and a continuously changing environment for workflow execution.
As a consequence, when the environment is changing continuously, then a dynamically changing or adapting execution model should be provided. It means that the Scientific
Workflow Management System should provide means to adapt to the new environmental conditions, to recover from failures, to provide alternative executions and to guarantee successful termination of the workflow instances with a probability ofp and lastly, but not finally to enable optimization support according to various needs such as time and energy usage.
We differentiated three different aspects of dynamism: Fault tolerance, which is the ability to continue the execution of the workflow in the presence of failures; Optimization, which enables optimized executions according to given parameters (i.e.: cost, time, resource usage, power,...); and Intervention and Adaptive execution, which enables the user, the scientist or the administrator to interfere with workflow execution during runtime and even that the system adaptively reacts to the unexpected situations.
The present dissertation deals with two of the above mentioned research areas: the fault tolerance and the adaptive and user-steered execution.
1.1 Motivation
The following subsections summarize the motivation of our research which was conducted during the past few years.
1.1.1 Workflow structure and fault tolerance
The different scientists’ communities have developed their own SWfMs, with divergent representational capabilities, and different dynamic support. Although the workflow description language differs from SWfMS to SWfMS according to their scientific research and needs, it is widely acknowledged that Directed Acyclic Graphs (DAG) serve as a top-level abstraction representation tool. Thus, a Scientific workflow can be represented by a G(V,E→), where the nodes (V) represents the computational tasks and the edges (→E) denote the data dependency between them. Concerning graphs a wide range of scientific results have been achieved in order to provide to other scientific disciplines with a simple but easily analyzable model. Also in the context of scientific workflows it is a widely accepted tool to analyze problems in scheduling, workflow similarity analysis and also in workflow estimation problems. However, dynamic execution of scientific workflows is most generally based on external conditions for example on failure statistics about components of execution environments or network elements and provenance data from historical executions. Despite this fact, we think that the structure of the graph representing the scientific workflow holds valuable information that can be exploited in workflow scheduling, resource allocation, fault tolerance and optimization techniques.
The first two thesis groups addresses the following questions to answer:
How much information can be obtained from the structure of the scientific workflows to adjust fault tolerance parameters and to estimate the consequences of a failure occurring during one task concerning the total makespan of the workflow execution?
How can this information be built in a proactive fault tolerance method, in checkpointing?
1.1.2 Adaptive and user-steered execution
From the scientists’ perspective workflow execution is like black boxes. The user submits the workflow and at the end he gets a notification about successful termination or failed execution. Concerning long executions and due to the complexity of scientific workflows it may not be sufficient. Moreover, due to the exploratory nature of scientific workflows the scientist or the user may intend to interfere with the execution and based on monitoring or debugging capabilities to carry out a modified execution on the workflow.
In the third thesis group we were looking for the answers for the questions:
How can scientists be supported to interfere with the workflow execution? How can provenance based user-steering be realized?
1.2 Objectives
Motivated by the problems outlined in the previous subsections the objectives of this thesis can be split into two major parts. The first and second thesis groups deal with problems connected to fault tolerance and the third thesis group concerns with adaptive and user steered workflow execution.
1.2.1 Workflow structure and fault tolerance
In the first thesis group I introduce the flexibility zone of a task concerning a certain time delay, and based on this definition I formulate the sensitivity indexSI of a scientific workflow model, which gives information on the connectivity property of the workflow. I also introduce the time sensitivity of a workflow model, which gives information about how sensitive the makespan of a workflow to a failure. According to the time sensitivity T S parameter I give an upper and lower limit for the sensitivity index, and based on the sensitivity index I give a taxonomy of scientific workflows.
1.2.2 Adjusting the checkpointing interval
In the second thesis group I present a static Workflow structure based (Wsb) and an Adaptive workflow structure based (Awsb) algorithm which were targeted to decrease the checkpointing overhead compared to the optimal checkpointing intervals calculated by Young (Young1974) and Di (Di et al.2013) without effecting the total wallclock time of the workflow. The effectiveness of the algorithms are demonstrated through various simulations. At first I will show the connectivity between the sensitivity index of a workflow model and the effectiveness of the Wsb algorithm. Then I present five different execution scenarios to compare the improvements of each scenario and finally I show the results of simulations that were carried out on random graphs which properties were adjusted according to real workflow models, based on a survey on the myExperiment.org website.
1.2.3 Adaptive and user-steered execution
In the third thesis group I introduce iPoints, special intervention Points with the primary aim to help the scientist to interfere with the execution and according to provenance analysis to alter the workflow execution or to change the abstract model of the workflow.
These iPoints are also capable to realize provenance based adaptive execution with the help of a so called Rule Based Engine that can be controled or updated by the scientist or with data mining support. In this thesis group I also give a specification of the above mentioned iPoints in IWIR (Interoperable Workflow Intermediate Representation) (Plankensteiner, Montagnat, and Prodan2011) language, which was developed with the aim to enable interoperability between four existing SWfMSs (ASKALON, P-Grade, MOTEUR and Triana) within the framework of the SHIWA project.
1.3 Methodology
As a starting point of my research I thoroughly investigated the related work in the theme of faults, failures and dynamic execution. According to the reviewed literature I gave a taxonomy about most frequently arising failures during the workflow lifecycle (Bahsi2008) (Gil et al.2007) and about the existing solutions that were aimed to provide
dynamic execution at a certain level.
This thesis employs two main methodologies to validate and evaluate the introduced formulas, ideas and algorithms. The first is an analytical approach. Taking into account that scientific workflows at the highest abstraction level are generally represented with
Directed Acyclic Graphs, our validation technique is based on investigating the structure of the interconnected tasks.
As graphs can range in size from a few tasks to thousands of tasks, and values assigned to the edges and tasks may diverse, I started with simplifying the workflows with a transformation that eliminates the values assigned to the edges and homogenize the tasks.
As a next step I used simple graph models to demonstrate my hypothesis, and afterwards with use of algorithms and methods from the field of graph theory I demonstrated, validated and proved my results.
The second approach was to validate my results with simulations in Matlab, in a numerical computing environment by MathWorks. I have implemented algorithms for the invented formulas and for the checkpointing algorithms as well, and conducted numerous simulations based on special workflow patterns as well as on randomized workflows. For the randomized workflow patterns I took into account a survey on real-life workflows from the myExperiment.org website.
1.4 Dissertation Organization
The dissertation is organized as follows: In the next chapter (2) I summarize the state of the art in the topic of dynamic execution, which served as the background work to my research. In this chapter I give a brief overview about the most frequent failures that can arise during execution, about dynamic execution from a failure handling perspective, about the most popular Scientific Workflow Management Systems (SWfMS), and their capabilities concerning to the fault prevention or fault handling methods. In chapter (3) I present my work on workflow structure analysis. Chapter (4) details the Static workflow structure based (Wsb) and the Adaptive workflow structure based (Awsb) checkpointing methods as well as the simulation results. In chapter (5) I introduce a novel workflow control mechanism, which provides the user intervention points and also for the system an adaptive provenance based steering and control points. This chapter also contains the specification of these intervention points in the IWIR (Interoperable Workflow Intermediate Representation language) which was developed within the framework of the SHIWA project and was targeted to promote interoperability between four existing SWfSMs. At the end the conclusion summarize my scientific results.
2 Dynamic execution of Scientific Workflows
Scientific workflow systems are used to develop complex scientific applications by connect- ing different algorithms to each other. Such organization of huge computational and data intensive algorithms aim to provide user friendly, end-to-end solution for scientists. The various phases and steps associated with planning, executing, and analyzing scientific workflows comprise the scientific workflow life cycle (WFLC) (section 2.1) (Bahsi 2008) (Gil et al. 2007) (Deelman and Gil 2006) (Ludäscher, Altintas, Bowers, et al. 2009).
These phases are largely supported by existing Scientific Workflow Management Systems (SWfMS) using a wide variety of approaches and techniques (Yu and Buyya 2005).
Scientific workflows being data and compute intensive, mostly require parallel and distributed infrastructures to be completed in a reasonable time. However, due to the complex nature of these High Performance Computing Infrastructures (clouds, grids and clusters) the execution environment of the workflows are prone to errors and performance variations. In an environment like this dynamic execution is needed, which means that the Scientific Workflow Management System should provide means to adapt to the new environmental conditions, to recover from failures, to provide alternative executions and to guarantee successful termination of the workflow instances with a probability ofp.
In this chapter we aim to provide a comprehensive insight and taxonomy about dynamic execution, with special attention of the different faults, fault-tolerant methods and a taxonomy about SWfMSs concerning fault tolerant capabilities.
2.1 Scientific Workflow Life Cycle
• Hypothesis Generation (Modification):
Development of a scientific workflow usually starts with hypothesis generation.
Scientists working on a problem, gather information, data and requirements about the related issues to make assumptions about a scientific process and based on their work they build a specification, which can be modified later on.
• Workflow Design: At this abstraction level, the workflow developer builds a so called abstract workflow. In general this abstract workflow model is independent from the underlying infrastructure and deployed services it only contains the actual steps that are needed to perform the scientific experiment.
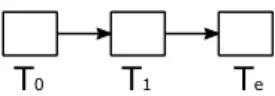
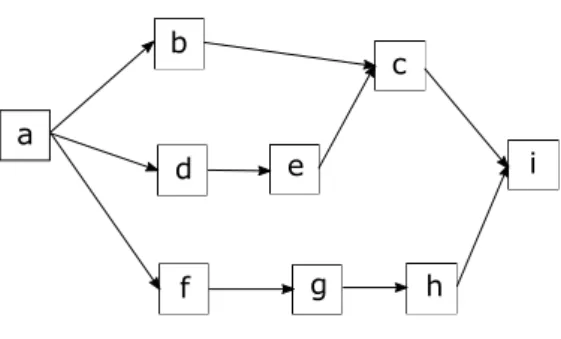
Several workflow design language has been developed over the years, like AGWL (Fahringer, Qin, and Hainzer2005), GWENDIA (Montagnat et al.2009), SCUFL (Turi et al. 2007) and Triana Taskgraph (Taylor et al. 2003), since the different scientific communities have developed their own SWfMS according their individual requirements. However, at the highest abstraction level these scientific workflows can be represented by directed graphs G(V,E→), where the nodes or vertices vi∈V are the computational tasks or jobs an the edges between them represent the dependencies (data or control flow). Fig. 2.1 shows an example of a scientific workflow with 4 tasks (T0,T1,T2,Te), withT0 being the entry task and Te being the end task. The numbers assigned to the tasks represent the execution time that is needed to successfully terminate the task and the numbers assigned to the edges represent the time that is needed to submit the successor task after the predecessor task has been terminated. This latter one can be the data transfer time, resource allocation time or communication time between the consecutive tasks.
Figure 2.1: Simple workflow with four tasks
In this phase also the configuration may take place. It means that besides the abstract workflow model a so called concrete workflow model is also generated.
The concrete workflow also includes some execution-specific information, like the resource-type, resubmission tries, etc. Once it has been configured an instantiation phase began.
• Instantiation: In this phase the actual mapping takes place, i.e.: the resource allocation, scheduling, parameter and data binding functions.
• Execution: After the workflow instantiation the workflow can be executed.
• Result Analysis: After workflow execution the scientists analyze their results, debug
the workflows or follow the execution traces if the system supported provenance data capturing. Finally, due to the exploratory nature of the scientific workflows after the evaluation of the results the workflow lifecycle may begin again and again.
2.2 Definition of dynamism
Dynamism on one hand is the ability of a system to react or to handle unforeseen scenarios raised during the workflow enactment phase, in a way to avoid certain failures or to recover from specific situations automatically or with user intervention. The adaptation to new situations may range from resubmitting a workflow to even the modification of the whole workflow model. On the other hand the dynamism is the opportunity to change the abstract or concrete workflow model or to give faster execution and higher level performance according to the actual environmental conditions and intermediary results.
We distinguish several levels at the different lifecycle phases of a workflow, where dynamic behaviour can be realized. The system level concerns with those dynamic issues that are supported by the workflow management system. The composition level includes the language or the DAG support. With task level solutions large scale dynamism can be achieved if the system is able to handle tasks as separate units. Workflow level dynamism deals with problems which can only be interpreted in the context of a certain workflow, while user level gives the opportunity for user intervention.
2.3 Taxonomy of dynamism
The dynamism supported by the workflow management systems can be realized in three phases of the above mentioned time intervals of the workflow lifecycle. (i.e.: design, instantiation, execution).
1. Design timeDuring design time, dynamism can be primarily supported by the modeling language at composition level. Several existing workflow managers have support for conditional structure in different levels. While some of them provide if, switch, and while structures that we are familiar with from high level languages, some of the workflow managers provide comparatively simple logic constructs. In the latter case, the responsibility of creating conditional structures is left to the users by combining those logic constructs with other existing ones (Wolstencroft et al. 2013).
Heinl et al. (Heinl et al.1999), (Pesic2008) gave a classification scheme for flexibility of workflow management systems. He defined two groups: flexibility by selection and flexibility by adaptation. Flexibility by selection techniques also should be implemented in the design time but of course they need some system level support.
It can be achieved by advance modeling and late modeling.
The advance modeling technique means that the user can define multiple execution alternatives during the design or configuration phase and the completion or in- completion of the predefined condition decides the actual steps processed in run time. The late modeling technique means, that parts of a process model are not modeled before execution, i.e. they are left as ’black boxes’ and the actual execution of these parts are selected only at the execution time.
During this phase the system may also support task level dynamism in a sense, that subworkflows, or tasks from existing workflows should be reusable in other workflows as well. The modular composition of workflows also enables the simple and quick composition of new workflows.
2. Instantiation time
Static decision making involves the risk that decisions may be made on the basis of information about resource performance and availability that quickly becomes outdated (K. Lee, Paton, et al.2009). As a result with system level support, benefits may appear either from incremental compilation, whereby resource allocation decisions are made for part of a workflow at a time (Deelman, G. Singh, et al.2005), or by dynamically revising compilation decisions of a concrete workflow while it is executing (Heinis, Pautasso, and Alonso 2005), (Duan, Prodan, and Fahringer 2006), (J. Lee et al. 2007). In principle, any decision that was made statically during workflow compilation should be revisited at runtime (K. Lee, Sakellariou, et al. 2007).
Another way to support dynamism at system level during instantiation is using breakpoints. To interact with the workflow for tracking and debugging, the developer can interleave breakpoints in the model. At these breakpoints the execution of job instances can be enabled or prohibited, or even it can be steered to another direction (Gottdank 2014).
We also reckon multi instance activities among the above mentioned system level dynamic issues. Multi instantiation of activities gives flexibility to the execution of workflows. It means that during workflow enactment one of the tasks should be executed with multiple instances (i.e.: parallelism), but the number of instances is
not known before enactment. A way to allow flexibility in data management at system level is to support access to object stores using a variety of protocols and security mechanisms (Vahi, Rynge, et al.2013).
A task level challenge for workflow management systems is to develop a flexible data management solution that allows for late binding of data. Tasks can discover input data at runtime, and possibly choose to stage the data from one of many locations.
At workflow level using mapping adaptations depending on the environment, the abstract workflow to concrete workflow bindings can change. The authors in (K.
Lee, Sakellariou, et al.2007) deal with this issue in details. If the original workflow can be partitioned into subworkflows before mapping, then each sub-workflow can be mapped individually. The order and timing of the mapping is dictated by the dependencies between the sub-workflows. In some cases the sub-workflows can be mapped and executed also in parallel. The partitioning details are dictated by how fast the target execution resources are changing. In a dynamic environment, partitions with small numbers of tasks are preferable, so that only a small number of tasks are bounded to resources at any one time (Ludäscher, Altintas, Bowers, et al. 2009).
In scientific context the most important applications are parameter sweep applica- tions over very large parameter spaces. Practically it means to submit a workflow with various data of the given parameter space. This kind of parallelization gives faster execution and high level flexibility in the execution environment. Scheduling algorithms can also be task based (task level) or workflow based (workflow level) and with system level support the performance and effectiveness of the algorithms can be improved with provenance based information.
3. Execution time
In a dynamically changing environment, during workflow enactment unforeseen scenarios may result in various work item failure (due to faulty results, resource unavailability, etc.). Many of these failures could be avoided with workflow manage- ment systems that provide more dynamism and support certain level of adaptivity to these scenarios.
We categorize the related issues into levels according to Table 2.1.
The first level is made up from the failure of hardware, software or network component, associated with the work item or data resources unavailability. In these cases, exception handling may or should include mechanisms to detect and to recover from failures (for example restart the job or workflow or make some
other decision based on provenance data), even with provenance based support.
In all these cases possible handling strategies should be tracking, monitoring and gathering provenance information in order to support users in coming to a decision.
The user level dynamism consists of scenarios where the system waits for user steer- ing. Here we can rate the breakpoints, where workflow execution can be suspended and enabled again by the user. Also at this time happens the interpretation of the black boxes (late modeling technique). Suspending a workflow and then continue with a new task by deviating from the original workflow model also gives more flexibility to the system at workflow level. In Heinl’s taxonomy (Heinl et al.1999), (Pesic 2008) it is defined by flexibility by adaptation. In this case we distinguish adaptive systems and ad-hoc systems. While adaptive systems modify process model on instances leaving the process model unchanged, in ad-hoc systems the model migrates to a new state, to a new model (Pesic2008).
According to the above described requirements and suggested solutions we have differentiated the different aspects of dynamism.
2.4 Aspects of dynamism
Depending on the goal of dynamic support dynamic behavior can also be classified into another three categories: 1. The dynamic and adaptive execution of the workflow from the users’ point of view. 2. The handling of the various problems and failures arising during execution that cannot be foreseen. 3. The optimizing purpose interventions of the system or the administrator. For example because of the effective or energy save usage of the system or the quick execution of a workflow [K-2].
2.5 Fault tolerance
Scientific workflows may range in size from a few tasks to thousands of tasks. For large workflows it is often required to execute them in a parallel and distributed manner in order to successfully complete the computations in a reasonable time or within soft or hard deadlines. One of the main challenges in workflow execution is the ability of documenting and dealing with failures (Wrzesińska et al.2006). Failures can happen because resources go down, data becomes unavailable, networks go down, bugs in the system software or in the application components appear, and many other causes.
2.6 Faults, failures and Fault tolerance
Investigating the literature we come across the fault, error, failure expressions, all having very similar meanings for the first sight. To clarify the concepts above the following definition is used.
Fault is defined as a defect at the lowest level of abstraction. A change in a system state due to a fault is termed as an error. An error can lead to a failure, which is a deviation of the system from its specified behavior (Chandrashekar2015) . To handle failures at first faults should be detected.
In order to detect occurrence of faults in any grid resource two approaches can be used:
the push and the pull model. In the push model, grid components by periodically sending heartbeat messages to a failure detector, announce that they are alive. In the absence of this heartbeat messages, the fault detector can recognize and localize the presence of a failure. The system then takes the necessary steps as dictated by the predefined fault tolerance mechanism. Contrariwise, in the pull model the failure detector sends live-ness requests periodically to grid components (H. Lee et al.2005).
During the different phases of the workflow lifecycle we have to face many types of failures, which lead unfinished task or workflow execution. In these cases the users, instead of getting the appropriate results of their experiment, the workflow process aborts and in general the scientist does not have knowledge about the cause of the failure. In the literature sevaral studies examine the failures occuring during the different phases of the workflow lifecycle from different perspectives (Plankensteiner, Prodan, Fahringer, et al. 2007), (Das and De Sarkar2012), (Schroeder and G. A. Gibson2007), (Schroeder and G. Gibson2010), (Alsoghayer2011), (X. Chen, Lu, and Pattabiraman 2014), (Samak et al. 2012), (Deelman and Gil 2006). Most of them base their analysis on data that was gathered from a nine-year long monitoring of the supercomputer of the Los Alamos National Labs (LANL). Mouallem (Mouallem2011) during his research, also based on the data from the Los Alamos National Labs (LANL), revealed that (50%) of the failures is caused by hardware, (20%) by the user, (10%) stems from network or other environmental sources and (20%) of them is unknown.
Based on these studies we have summarized and classified the most frequent failures that can arise during execution time on parallel and distributed environment including grids [networkshop] and clouds [doceis] environments. The arising failures are examined at four abstract levels, namely the system level, task level, workflow level and user level (Table 2.1). The system level failure deals on the one hand with errors and problems related to the infrastructure (hardware or network failures), on the other hand with
problems related to configuration parameters, which manage the execution. At workflow level we mention those failures, that have impact on the whole workflow and can corrupt the whole execution of the workflow. The task level failures can influence the execution of only one task, and the impact of any failures does not cover the whole workflow. Also we differentiate user level faults during the design time, they are mostly bounded to programming errors (i.e: infinite loop).
After categorizing the potential failures, we show how dynamic behavior (investigated in [K-3]) and provenance support can give solutions for avoiding and preventing them or to recover from situations caused by failures and problems that cannot be foreseen or predicted. In the table after the possible failures there is a ’=⇒’ sign inserted and then the potential solutions that can be carried out by a dynamic system are presented.
2.7 Taxonomy of Fault Tolerant methods
In this section I present a brief overview about the most frequently used fault tolerant techniques.
Hwang et al. (Hwang and Kesselman 2003) divided the workflow failure handling techniques into two different levels, namely task-level and workflow-level. Task-level techniques handle the execution failure of tasks individually, while workflow-level tech- niques may alter the sequence of execution in order to address the failures (Garg and A. K. Singh 2011).
Another categorization of the faults can be done according to when the failure handling occurs. Fault tolerance policy can be reactive and proactive. While the aim of proactive techniques is to avoid situations caused by failures by predicting them and taking the necessary actions, reactive fault tolerance policies reduce the effect of failures on application execution when the failure effectively occurs.
According to this classification reactive techniques include: user defined exception handling, retry, resubmission, job migration, using alternative task; proactive techniques are replication, checkpointing.
• Retrying: This might be the simplest task-level failure recovery technique to use with the assumption that whatever caused the failure, it will not be encountered in subsequent retries (Gärtner1999), (Sindrilaru, Costan, and Cristea2010).
• Alternative tasks: A key idea behind this failure handling technique is that when a task has failed, an alternative task is to be performed to continue the execution, as opposed to the retrying technique where the same task is to be repeated over and
Table 2.1: Notation of the variables of the Wsb and AWsb algorithm
Design time
system level task level user level
infinite loop
=⇒advanced language and modeling support
Instantiation time
system level task level workflow level
HW failures Incorrect output data infinite loop
network failures Missing shared libraries Input data not available
file not found =⇒data and file replication
Network congestion Input error
task submission failure =⇒data and file replication
=⇒checkpoint Data movement failed
authentication failed =⇒checkpoint
=⇒user intervention file staging
Service not reachable
Execution time
system level task level workflow level user level
Hardware failure job crashed data user defined
Network failure =⇒user intervention, movement exception
File not found =⇒alternate task failed
Job hanging in the =⇒checkpoint =⇒checkpoint
queue of the local deadlock
resource manager =⇒dynamic
=⇒dynamic resource allocation resource brokering =⇒checkpoint
job lost before uncaught exception
reaching the local =⇒exception handling,
resource manager =⇒user intervention
=⇒dynamic
resource brokering, user intervention
over again which might never succeed. This technique might be desirable to apply in some cases where there are at least two different task implementations available for a certain computation however, has different execution characteristics. (Hwang and Kesselman 2003).
• User-defined Exception Handling: This technique allows users to give a special treatment to a specific failure of a particular task. This could be achieved by using the notion of the alternative task technique.
• Workflow-level redundancy: As opposed to the task-level replication technique
where same tasks are replicated, the key idea in this technique is to have multiple different tasks run in parallel for a certain computation.
• Job Migration: During failure of any task, it can be migrated to another computing resource. (Plankensteiner, Prodan, and Fahringer 2009)
• Task resubmission: It is the most widely used fault tolerance technique in current scientific workflow systems. Whenever a failed task is detected, it is resubmitted either on the same resource or to another one. In general the number of the resubmissions can be configured by the user.
• Replication: When using replication where critical system components are du- plicated using additional hardware or with scientific workflows critical tasks are replicated and executed on more than one processor. The idea behind task replica- tion is that replication size r can tolerater−1 faults while keeping the impact on the execution time minimal. We call r the replication size. While this technique is useful for time-critical tasks its downsides lies in the large resource consumption, so our attention is focused on mainly checkpointing methods in this work. We can differentiate active and passive replication. Passive replication means that only one primary processor is invoked in the execution of a task and in the case of a failure the backup ones take over the task processing. In the active form all the replicas are executed at the same time and in the case of a failure the replica can continue the execution without intervention (Plankensteiner2013). We also differentiate static and dynamic replication. The static replication means that, when some replica fails, it is not replaced by a new one. The number of replicas of the original task is decided before execution. While in case of dynamic replication, new replicas can be generated during run time (Garg and A. K. Singh 2011)
• Checkpointing: When system state is captured form time to time and when a failure occurs, the last saved state is restored and the execution can be continued from that point on. A more detailed state-of-the art about checkpointing can be found in section4.1.
2.8 SWfMS
In this section I give a brief overview about the most dominant Scientific Workflow Management Systems (SWfMS). After a short introduction of each SWfMS the focus is on their fault tolerance capabilities.
2.8.1 Askalon
ASKALON (Fahringer, Prodan, et al. 2007) serves as the main application development and computing environment for the Austrian Grid Infrastructure. In ASKALON, the user composes Grid workflow applications graphically using a UML based workflow composition and modeling service. Additionally, the user can programmatically describe workflows using the XML-based Abstract Grid Workflow Language (AGWL), designed at a high level of abstraction that does not comprise any Grid technology details. Askalon can detect and recover failures dynamically at various levels.
The Execution Engine provides fault tolerance at three levels of abstraction: (1) activity level, through retry and replication; (2) control-flow level, using lightweight workflow checkpointing and migration; and (3) workflow level, based on alternative task, workflow level redundancy and workflow-level checkpointing. The Execution Engine provides two types of checkpointing mechanisms, lightweight workflow checkpointing saves the workflow state and URL references to intermediate data at customizable execution time intervals and is typically used for immediate recovery during one workflow execution.
Workflow-level checkpointing saves the workflow state and the intermediate data at the point when the checkpoint is taken, is saved into a checkpointing database thus it can be restored and resumed at any time and from any Grid location.
2.8.2 Pegasus
The Pegasus (which stands for Planning for Execution in Grids) Workflow Management System (Deelman, G. Singh, et al.2005), first developed in 2001, was designed to manage workflow execution on distributed data and compute resources such as clusters, grids and clouds.
The abstract workflow description language (DAX, Directed Acyclic graph in XML) provides a resource-independent workflow description. Pegasus dynamically handles failures at multiple levels of the workflow management system building upon reliability features of DAGMan and HTCondor. Pegasus can handle failures dynamically at various levels building on the features of DAGMan and HTCondor. If a node in the workflow fails, then the corresponding job is automatically retried/resubmitted by HTCondor DAGMan.
This is achieved by associating a job retry count with each job in the DAGMan file for the workflow. This automatic resubmit in case of failure allows us to automatically handle transient errors such as a job being scheduled on a faulty node in the remote cluster, or errors occurring because of job disconnects due to network errors. If the number of failures for a job exceeds the set number of retries, then the job is marked as a fatal
failure that leads the workflow to eventually fail. When a DAG fails, DAGMan writes out a rescue DAG that is similar to the original DAG but the nodes that succeeded are marked done. This allows the user to resubmit the workflow once the source of the original error has been resolved. The workflow will restart from the point of failure (Deelman, Vahi, et al. 2015). Pegasus has its own uniform, lightweight job monitoring capability: the pegasus-kickstart (Vockler et al. 2007), which helps in getting runtime provenance and performance information of the job.
2.8.3 gUSE/WS-PGRADE
The gUSE/WS-PGRADE Portal (Peter Kacsuk et al. 2012), developed by Laboratory of the Parallel and Distributed Systems at MTA SZTAKI, is a web portal of the grid and cloud User Support Environment (gUSE). It supports development and submission of distributed applications executed on the computational resources of various distributed computing infrastructures (DCIs) including clusters (LSF, PBS, MOAB, SGE), service grids (ARC, gLite, Globus, UNICORE), BOINC desktop grids as well as cloud resources:
Google App Engine, CloudBroker-managed clouds as well as EC2-based clouds (Balasko, Farkas, and Peter Kacsuk2013). It is the second generation P-GRADE portal (Farkas and Peter Kacsuk2011) that introduces many advanced features both at the workflow and architecture level compared to the first generation P-GRADE portal which was based on Condor DAGMan as the workflow enactment engine.
WS-PGRADE (the graphical user interface service) provides a Workflow Developer UI through which all the required activities of developing workflows are supported the gUSE service set provides an Application (Workflow) Repository service in the gUSE tier.
WS-PGRADE uses its own XML-based workflow language with a number of features:
advanced parameter study features through special workflow entities (generator and collector jobs, parametric files), diverse distributed computing infrastructure (DCI) support, condition-dependent workflow execution and workflow embedding support.
From a fault tolerance perspective gUSE can detect various failures at hardware -, OS -, middleware, task -, and workflow level. Focusing on prevention and recovery, at Workflow level, redundancy can be created, moreover light-weight checkpointing and restarting of the workflow manager on failure is fully supported. At Task level, checkpointing at OS-level is supported by PGRADE. Retries and resubmissions are supported by task managers. The workflow interpretation permits a job instance granularity of checkpointing, in the case of the main workflow, i.e. a finished state job instance will not be resubmitted during an eventual resume command. However, the situation is a bit worse in the case of embedded workflows, as the resume of the main (caller) workflow can involve the total
resubmission of the eventual embedded workflows (Plankensteiner, Prodan, Fahringer, et al. 2007).
2.8.4 Triana
The Triana problem solving environment (Taylor et al. 2003) (Majithia et al. 2004) is an open source problem solving environment developed at Cardiff University that combines an intuitive visual interface with powerful data analysis tools. It was initially developed to help scientists in the flexible analysis of data sets, and therefore contains many of the core data analysis tools needed for one-dimensional data analysis, along with many other toolboxes that contain components or units for areas such as image processing and text processing. Triana may be classified as a graphical Grid Computing Environment and provides a user portal to enable the composition of scientific applications. Users compose an XML- based task graph by dragging programming components (called units or tools) from toolboxes, and drop them onto a scratch pad (or workspace). Connectivity between the units is achieved by drawing cables. Triana employed a passive approach by informing the user when a failure has occurred. The workflow could be debugged through examining the inbuilt provenance trace implementation and through a debug screen. During the execution, Triana could identify failures for components and provide feedback to the user if a component fails but it did not contain fail-safe mechanisms within the system for retrying a service for example (Deelman, Gannon, et al.2009). A recent development in Triana at Workflow level light-weight checkpointing and the restart or selection of workflow management services are supported (Plankensteiner, Prodan, Fahringer, et al.2007).
2.8.5 Kepler
Kepler (Altintas et al.2004) is an open-source system and is built on the data-flow oriented PTOLEMY II framework. A scientific workflow in Kepler is viewed as a composition of independent components called actors. The individual and resusable actors represent data sources, sinks, data transformers, analytical steps, or arbitrary computational steps. Communication between actors happens through input and output ports that are connected to each other via channels.
A unique property of Ptolemy II is that the workflow is controlled by a special scheduler called Director. The director defines how actors are executed and how they communicate with one another. Consequently, the execution model is not only an emergent side-effect of the various interconnected actors and their (possibly ad-hoc) orchestration, but rather
a prescribed semantics (Ludäscher, Altintas, Berkley, et al. 2006). Kepler workflow management system can be divided into three distinct layers: the workflow layer, the middleware layer, and the OS/hardware layer. The workflow layer, or the control layer provides control, directs execution, and tracks the progression of the simulation. The framework that was proposed in (Mouallem2011) has three complementary mechanisms:
a forward recovery mechanism that offers retries and alternative versions at the workflow level, a checkpointing mechanism, also at the workflow layer, that resumes the execution in case of a failure at the last saved consistent state, and an error-state and failure handling mechanisms to address issues that occur outside the scope of the Workflow layer.
2.8.6 Taverna
The Taverna workflow tool (Oinn et al. 2004), (Wolstencroft et al. 2013) is designed to combine distributed Web Services and/or local tools into complex analysis pipelines.
These pipelines can be executed on local desktop machines or through larger infrastructure (such as supercomputers, Grids or cloud environments), using the Taverna Server. The tool provides a graphical user interface for the composition of workflows. These workflows are written in a new language called the simple conceptual unified flow language (Scufl), where by each step within a workflow represents one atomic task. In bioinformatics, Taverna workflows are typically used in the areas of high-throughput omics analyses (for example, proteomics or transcriptomics), or for evidence gathering methods involving text mining or data mining. Through Taverna, scientists have access to several thousand different tools and resources that are freely available from a large range of life science institutions. Once constructed, the workflows are reusable, executable bioinformatics protocols that can be shared, reused and repurposed.
Taverna has breakpoint support, including the editing of intermediate data. Breakpoints can be placed during the construction of the model at which execution will automatically pause or by manually pausing the entire workflow. However, in Taverna the e-scientist cannot find a way to dynamically choose other services to be executed on the next workflow steps depending on the results.
2.9 Provenance
Data provenance refers to the origin and the history of the data and its derivatives (meta-data). It can be used to track evolution of the data, and to gain insights into the analysis performed on the data. Provenance of the processes, on the other hand, enables
scientist to obtain precise information about how, where and when different processes, transformations and operations were applied to the data during scientific experiments, how the data was transformed, where it was stored, etc. In general, provenance can be, and is being collected about various properties of computing resources, software, middleware stack, and workflows themselves (Mouallem2011).
Concerning the volume of provenance data generated at runtime another challenging research area is provenance data analysis concerning runtime analysis and reusable workflows. Despite the efforts on building a standard Open Provenance Model (OPM) (Moreau, Plale, et al.2008), (Moreau, Freire, et al.2008) provenance is tightly coupled to SWfMS. Thus scientific workflow provenance concepts, representation and mechanisms are very heterogeneous, difficult to integrate and dependent on the SWfMS. To help comparing, integrating and analyzing scientific workflow provenance, authors in (Cruz, Campos, and Mattoso 2009) presents a taxonomy about provenance characteristics.
PROV-man (Benabdelkader, Kampen, and Olabarriaga 2015) is an easily applicable implementation of the World Wide Web Consortium (W3C) standardized PROV. The PROV (Moreau and Missier2013) was aimed to help interoperability between the various provenance based systems and gives recommendations on the data model and defines various aspects that are necessary to share provenance data between heterogeneous systems. The PROV-man framework consists of an optimized data model based on a relational database system (DBMS) and an API that can be adjusted to several systems.
When provenance is extended with performance execution data, it becomes an impor- tant asset to identify and analyze errors that occurred during the workflow execution (i.e.
debugging).
3 Workflow Structure Analysis
Scientific workflows are targeted to model scientific experiments, which consists of data and compute intensive calculations and services which are invoked during the execution and also some kind of dependencies between the tasks (services). The dependency can be data-flow or control-flow oriented, which somehow determine the execution order of the tasks. Scientific workflows are mainly data-dependent, which means that the tasks share input and output data between each other. Thus a task cannot be started before all the input data is available. It gives a strict ordering between the tasks and therefore the structure of a scientific workflow stores valuable information for the developer, the user and also for the administrator or the scientific workflow manager system. Therefore workflow structure analysis is frequently used in different tasks, for example in workflow similarity analysis, scheduling algorithms and workflow execution time estimation problems.
In this chapter I am going to analyze workflows from a fault tolerance perspective. I am trying to answer the questions how flexible a workflow model is; how robust is the selected and applied fault tolerance mechanism; how can the fault tolerance method to a certain DCI , or to the actually available resource assortment fine-tuned.
Proactive fault tolerance mechanisms generally have some costs both in time and in space (network usage, storage). The time cost affects the total workflow execution time, which is one of the most critical constraints concerning scientific workflows, especially time-critical applications. Fault tolerance mechanisms are generally adjusted or fine tuned based on the reliability of the resources or on failures statistics gathered and approximated by the means of historical executions stored in Provenance Database (PD), for example expected number of failures. However, when the mechanism is based on these before mentioned statistical data, the question arises: what happens when more failures occur then it was expected?
With our workflow structure analysis we are trying to answer these questions.
3.1 Workflow structure investigations - State of the art
One of the most frequently used aspect of workflow structure analysis is makespan estimation. In their work (Pietri et al.2014) the authors have divided tasks into levels based on the data dependencies between them so that tasks assigned to the same level are independent from each other. Then, for each level, its execution time (which is equal to the time required for the execution of the tasks in the level) can be calculated considering the overall runtime of the tasks of the level. With this model they have demonstrated that they can still get good insight into the number of slots to allocate in order to achieve a desired level of performance when running in cloud environments.
Another important aspect of workflow structure investigation is workflow similarity research. It is a very urgent and relevant topic, because workflow re-usability and sharing among the scientists’ community has been widely adopted. Moreover, workflow repositories increase in size dramatically. Thus, new challenges arise for managing these collections of scientific workflows and for using the information collected in them as a source of expert supplied knowledge. Apart from workflow sharing and retrieval, the design of new workflows is a critical problem to users of workflow systems (Krinke 2001). It is both time-consuming and error-prone, as there is a great diversity of choices regarding services, parameters, and their interconnections. It requires the researcher to have specific knowledge in both his research area and in the use of the workflow system.
Consequently, it would make the researcher’s work easier when they do not have to start from scratch, but would be afforded some assistance in the creation of a new workflow.
The authors in (Starlinger, Cohen-Boulakia, et al.2014) divided the whole workflow comparison process into two distinct level: the level of single modules and the level of whole workflow. First they carry out a comparison comparing the task-pairs individually and thereafter a topological comparison is applied. According to their research in the existing solutions (Starlinger, Brancotte, et al. 2014) regarding topological comparison, existing approaches can be classified as either a structure agnostic, i.e., based only on the sets of modules present in two workflows, or a structure based approach. The latter group makes similarity research on substructures of workflows, such as maximum common subgraphs (Krinke 2001), or using the full structure of the compared workflows as in (Xiang and Madey2007), where authors use SUBDUE to carry out a complete topological comparing on graph structures by redefining isomorphism between graphs. It returns a cost value which is a measurement of the similarity.
In scheduling problems workflow structure investigations are also a popular form to optimize resource mapping problems. The paper (Shi, Jeannot, and Dongarra 2006)
addresses to solve a bi-objective matching and scheduling of DAG-structured application as both minimize the makespan and maximize the robustness in a heterogeneous computing system. In their work they prove that slack time is an effective metric to be used to adjust the robustness and it can be derived from workflow structure. The authors in (Sakellariou and H. Zhao 2004) introduce a low cost rescheduling policy, which considers rescheduling at a few, carefully selected points during the execution. They also use slack time (we use this term as flexibility parameter in our work), which is the minimum spare time on any path from this node to the exit node. Spare time is the maximal time that a predecessor task can be delayed without affecting the start time of its child or successor tasks. Before a new task is submitted it is considered whether any delay between the real and the expected start time of the task is greater than the slack or the min-spare time. In (Poola et al.2014) authors present a robust scheduling algorithm with resource allocation policies that schedule workflow tasks on heterogeneous Cloud resources while trying to minimize the total elapsed time (makespan) and the cost. This algorithm decomposes the workflow into smaller groups of tasks, into Partial Critical Paths (PCP), which consist of the nodes that share high dependency between them, for those the slack time is minimal.
They declared that PCPs of a workflow are mutually exclusive, thus a task can belong to only one PCP.
To the best of our knowledge workflow structure analysis from a fault tolerance perspective has not been carried out.
3.2 Fault sensitivity analysis
Scientific experiments are usually modeled by scientific workflows at the highest ab- straction level, which are composed of tasks and edges and some simple programming structures (conditional structures, loops, etc.). Thus, these scientific workflows can be represented by graphs.
Given the workflow model G(V,E→), where V is the set of nodes (tasks) and →E is the set of edges representing the data dependency, formally V = Ti|1≤i≤ |V| ,
→
E=n Ti, Tj|Ti, Tj ∈V and∃T i→Tjo. |V|=n is the number of nodes (tasks in the workflow). Usually scientific workflows are represented with Directed Acyclic Graphs (DAGs), where the numbers associated to tasks specifies the time that is needed to execute the given task and the numbers associated to the edges represent the time needed to start the subsequent task. This latter one can involve data transfer time from the previous tasks, resource starting time, or time spent in the queue. All these values can be obtained from historical results, from a so called Provenance Database (PD) or it can
be estimated based on certain parameters for example on the number of instructions.
Definition 3.2.1. Let G(V,E→) be a DAG.V is the set of vertices, and →E is the set of directed edges. P arent(v) is the set of parent tasks ofv and Child(v) is the set of child tasks ofv. Formally, P arent(v) =
u|u→v∈E→
and Child(v) =
u|v →u∈E→
.
Definition 3.2.2. Let G(V,E→) be a DAG.V is the set of vertices, and →E is the set of directed edges. P RED(v) is the predecessor set ofv andSU CC(v) is the successor set of v. Formally P RED(v) =u|u→→v and SU CC(v) =u|v→→u . Whereu→→v
indicates that there exist a path from v tou inG.
In this work we only consider data-flow oriented scientific workflow models where their graph representations are DAGs (Directed Acyclic Graphs) with one entry taskT0 and one exit taskTe. If the original scientific workflow would have more entry tasks or more exit task, then we can introduce a T00 entry task which precedes all the original entry tasks and also an exit taskTee which follows all the original exit tasks with parameters of 0 and they were connected to the entry tasks or exit tasks respectively with the 0 value assigned edges.
In such case the calculations are not affected, because path length are not increased due to the 0 parameters.
When a failure occurs during the execution of a task then the execution time of the given task is increased with the fault detection time and recovery time. The recovery time depends from the actually used fault tolerant method.
When the used fault tolerance is a checkpointing algorithm, then the recovery time is composed of the restoring time of the last saved state and the recalculation time from the last saved state. In the case of resubmission technique the recovery time consists of the recalculation time. In the case of a job migration technique the recovery time can be calculated as in the case of using the resubmission method increased by the restarting time of the new resource.
To investigate the effects of a failure we introduce the following definitions:
Definition 3.2.3. The local cost (3.1) of a failure on task Ti is the execution time overhead of the task when during its execution one failure occurs.
Clocal,i=t(Ti) +Tr+Tf. (3.1)
Definition 3.2.4. The global failure cost (3.2) of a taskTiis the execution time overhead of the whole workflow, when one failure occurs during taskT.