DOKTORI (PhD) ÉRTEKEZÉS
BALASKÓ BALÁZS
Pannon Egyetem
2009.
Pannon Egyetem
Vegyészmérnöki és Folyamatmérnöki Intézet
Folyamat-szimulációs és adatbányászati eszközök integrált alkalmazása
a folyamatanalízisben és -optimalizálásban
DOKTORI (PhD) ÉRTEKEZÉS Balaskó Balázs
Konzulens
Dr. habil. Abonyi János, egyetemi docens Dr. Németh Sándor, egyetemi docens
Vegyészm. Tudományok és Anyagtudományok Doktori Iskola
2009.
Folyamat-szimulációs és adatbányászati eszközök integrált alkalmazása a folyamatanalízisben és -optimalizálásban
Értekezés doktori (PhD) fokozat elnyerése érdekében
a Pannon Egyetem Vegyészmérnöki Tudományok és Anyagtudományok Doktori Iskolájához tartozóan
Írta:
Balaskó Balázs
Konzulens: Dr. Abonyi János
Elfogadásra javaslom (igen / nem)
(aláírás) A jelölt a doktori szigorlaton 100 %-ot ért el,
Az értekezést bírálóként elfogadásra javaslom:
Bíráló neve: dr. Szederkényi Gábor igen /nem
……….
(aláírás)
Bíráló neve: dr. Meszéna Zsolt igen /nem
……….
(aláírás)
A jelölt az értekezés nyilvános vitáján …...%-ot ért el.
Veszprém, ……….
a Bíráló Bizottság elnöke A doktori (PhD) oklevél minősítése…...
………
Az EDT elnöke
University of Pannonia
Department of Process Engineering
Integration of Process Simulation and Data Mining Techniques for the Analysis and
Optimization of Process Systems
PhD Thesis Balazs Balasko
Supervisor Janos Abonyi, PhD Sandor Nemeth, PhD
PhD School of Chemical and Material Engineering Science
2009
Köszönetnyilvánítás
Mindenek el®tt szeretném kifejezni hálámat és csodálatomat családomnak és Andinak, akik minden létez® eszközzel támogatták tanulmányaimat és biztos lelki hátteret jelentettek mind az egyetemi, mind a doktorandusz évek során.
Köszönetemet szeretném kifejezni a Folyamatmérnöki Intézeti Tanszék mun- katársainak, kiemelten dr. Abonyi Jánosnak, dr. Németh Sándornak és dr.
Feil Balázsnak az éveken át tartó, szakmai és emberi segítséget, amik nélkül ez a doktori dolgozat nem jöhetett volna létre. Jánosnak különösképpen a MOL-os id®szak során tanusított távsegítségét és kitartását.
Szintén sokkal tartozom az azóta már a nagybet¶s életben szolgálatot teljesít® doktorandusz hallgató társaimnak, dr. Pach Ferenc Péternek és dr.
Madár Jánosnak. Petinek különösen a türelemért, az együtt végigvitt projekt- ért, Janinak a tapasztalatok önzetlen megosztásáért. Végezetül köszönöm a VIKKK-nek az anyagi támogatást.
Remélem sikerült megszolgálnom mindenki bizalmát, és a jelen munka azt mutatja, megérte a fáradságot.
Kivonat
Folyamat-szimulációs és adatbányászati eszközök integrált alkalmazása a folyamatanalízisben és -optimalizálásban
A modern technológiai rendszerek tervezése, üzemeltetése és irányítása során számos eszköz, adat, információ jön létre, melyek közül azonban csupán korláto- zott mennyiség kerül tárolásra, feldolgozásra. Pedig ezek az információk nyil- vánvalóan magukban hordozzák a technológia továbbfejlesztésének lehet®ségét is. A probléma egyik f® oka abban rejlik, hogy a különböz® forrásokból, külön- böz® eszközökkel elérhet® információk elérése korlátozott, nem kezelhet®ek egy olyan egységes keretrendszerben, amely mind horizontálisan, mind vertikálisan integrálja a rendszert - ill. tágabban értelmezve a vállalatot.
Ennek a konkrét igénynek megfelel®en a kutatás célja egy olyan hierar- chikus modellezési és adatbányászati keretrendszer fejlesztése volt, mely al- kalmas a különböz® folyamatmérnöki feladatok megoldására, és melyben a különböz® részletesség¶ és típusú információk, illetve modellek (matematikai modellekkel formalizált mérnöki ismeretek, adatokon alapuló fekete-doboz mo- dellek, nyelvi formában rögzített tapasztalati tudás) egyidej¶leg kezelhet®k. A dolgozat egy valós ipari rendszer, egy polimerizációs üzem termel® egysége kapcsán mutatja be egy ilyen keretrendszer megvalósíthatóságát.
A megvalósítás során, a keretrendszer egyes aspektusaihoz kapcsolódóan kifejlesztésre került egy olyan technológiai szimulátor prototípus, mely inte- gráltan kezeli a technológiai és folyamatirányító rendszer modelljét és inte- gráltan kapcsolódik a folyamat adattárházhoz. A konszolidált, rendszerezett adatok elemzésére a dolgozat egy szimbolikus szegmentáción alapuló módszert mutat be, valamint az eddigi eszközöket egy kísérletervezési módszer és annak továbbfejlesztett változatának bemutatásával egészíti ki.
A kifejlesztett eszközök integrált módon szolgálják a folyamatelemzést, folyamatfejlesztést és -optimalizálást.
Abstract
Integration of Process Simulation and Data Mining Tech- niques for the Analysis and Optimization of Process Sys- tems
Modern automated production systems (like chemical industry) provide large amount of information in every minute but only a small portion is stored or even smaller is analyzed although these data denitely has the potential for improving the underlying technology.
Aim of this thesis was to dene a framework integrating data mining tools and multi-scale models, which is applicable in numerous elds of chemical engi- neering tasks. During implementation as case study for a Hungarian polymer- ization plant, a process-data-warehouse-centered process simulator prototype has been developed, while for qualitative analysis of process and simulated data, a symbolic segmentation based algorithm is presented. Additionally, a novel experiment design method extends the armory of the thesis.
Auszug
Integration von Prozess-Simulation und Data Mining-Tech- niken für die Analyse und Optimierung von Prozess-Systeme
Moderne, automatische Produktionssysteme (wie chemische Industrie) liefern eine groÿe Menge Information in jeden Minuten, aber nur geringe Proportion wird gespeichert oder analysiert obwohl diese Prozessdaten für Technologieen- twicklung und -verbesserung benutzt werden könnten.
Ziel dieser Arbeit war ein solcher Rahmen der Integration von Data-Mining- Tools und mehrstuge Modellen zu entwickeln, die in zahlreichen Bereichen der Chemieingenieur-aufgaben verwendbar ist. Während der Durchführung als Fallstudie für eine ungarische Polymerisation Anlage, ein Prozess-Simulator Prototyp wurde rund um einen Prozessdata Warehouse entwickelt, und für die qualitative Analyse von Prozess- und simulierten Daten wurde eine sym- bolische Segmentierungsalgorithmus vorgestellt. Zusätzlich wurde ein neuer Versuch Design-Methode präsentiert.
Contents
1 INTRODUCTION 1
1.1 Importance of process models in chemical engineering . . . 1
1.1.1 Life-cycle of process models . . . 3
1.1.2 Model-based process analysis, control, monitoring and optimization . . . 5
1.2 Process data - from source to applications . . . 12
1.2.1 Data acquisition and retrieval . . . 12
1.2.2 Information extraction from process data: Knowledge Discovery in Databases . . . 15
1.2.3 Overview of recent advances on time series similarity . . 19
1.3 Integrated application of process data, simulation models and experiment design . . . 22
1.4 Motivation of the thesis, roadmap . . . 24
2 Integrated modeling and simulation of processes and control systems 27 2.1 An integrated framework . . . 28
2.2 Realization at a polymerization plant . . . 30
2.2.1 Implementation of the proposed methodology . . . 31
2.2.2 Model validation . . . 41
2.3 Application examples . . . 44
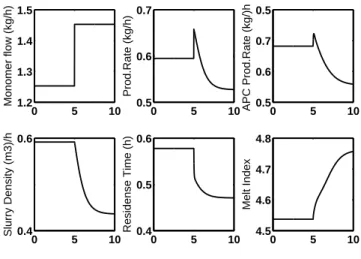
2.3.1 What-if type analysis . . . 44
2.3.2 Product transition analysis . . . 45
2.3.3 Product quality estimation by soft-sensor application . . 51
2.3.4 Operating cost estimation and analysis for polymer pro- duction . . . 54
2.4 Conclusion . . . 60
3 Semi-qualitative, Symbolic data analysis 61
3.1 A novel approach . . . 61
3.1.1 Segmentation based Symbolic Trend Representation . . . 62
3.1.2 Symbolic Sequence Comparison, Pairwise Sequence Align- ment . . . 64
3.1.3 An illustrating example . . . 66
3.2 The proposed algorithm . . . 68
3.2.1 Similarity measure . . . 68
3.2.2 Structure of the algorithm . . . 70
3.2.3 Visualization and clustering . . . 72
3.3 Evaluation and application . . . 73
3.3.1 Comparison to common distance measures . . . 73
3.3.2 Comparison to PLA-based DTW . . . 74
3.3.3 A Case Study: Product transition qualication . . . 78
3.4 Conclusion . . . 83
4 Model parameter estimation, experiment design 84 4.1 Optimal Experiment Design . . . 84
4.2 Additive Sequential Optimal Experiment Design . . . 89
4.3 Evaluation and application . . . 91
4.3.1 Evaluation of Evolutionary Strategy in OED . . . 93
4.3.2 Evaluation of Additive Sequential OED . . . 97
4.4 Conclusion . . . 98
5 Summary and Theses 100 5.1 Tézisek . . . 102
5.2 Theses . . . 104
5.3 Publications related to theses . . . 106
A Appendix 109 A.1 Integrated modeling and simulation . . . 109
A.1.1 The analyzed polymerization technology . . . 109
A.1.2 Model of a loop reactor . . . 111
A.1.3 Simulink models of process and control systems . . . 114
A.1.4 Introduction to Self-Organizing Maps . . . 118
A.2 Semi-qualitative, Symbolic Data Analysis . . . 119
A.2.1 Data Preprocessing . . . 119
A.2.2 Result table: Comparison to common distance measures 122 A.2.3 Introduction to Piecewise Linear Approximation based
Dynamic Time Warping . . . 123 A.3 Optimal Experiment Design . . . 126 A.3.1 Evolutionary Strategy . . . 126
B Acronyms and Notations 127
B.1 Acronyms . . . 127 B.2 Notations . . . 130
Chapter 1
INTRODUCTION
Chemical engineering is said to be a profession of applied natural science, but besides applying the common practice for design, maintenance and control of industrial processes, it always faces challenges to continuously improve these techniques, thus improve the eciency, eectiveness and reliability of all the chemical engineering activities. Charpentier denes the future main objec- tives of chemical engineering in four areas: (1) total multi-scale control of the process to increase selectivity and productivity; (2) equipment design based on scientic principles and new operation modes and methods of production:
process intensication; (3) product design; (4) an implementation of the multi- scale and multidisciplinary computational chemical engineering modeling and simulation to real-life situations [1].
It is clear that in every area, process data and process models play essential role to fulll these high expectations, into which this chapter gives a brief introduction whereas their linkage in process optimization is highlighted as well. At the end of this chapter, the contribution of the thesis is presented, which will be detailed in the following chapters.
1.1 Importance of process models in chemical engineering
Customers' satisfaction and the economical challenge of modern technologies claim for a continuous optimization in every eld of life. In chemical industry, products with tailored quality values have to be produced while specic costs have to be on a minimal level. Towards this goal, process modeling, simulation
Time scale
ps ns ms s min h day week month
Molecules Molecule clusters Particles, thin films Single/multi- phase systems Process units Plants Sites Enterprise
Chemical scale
small intermed.
large µm
nm mm
pm m km
Lenght scale
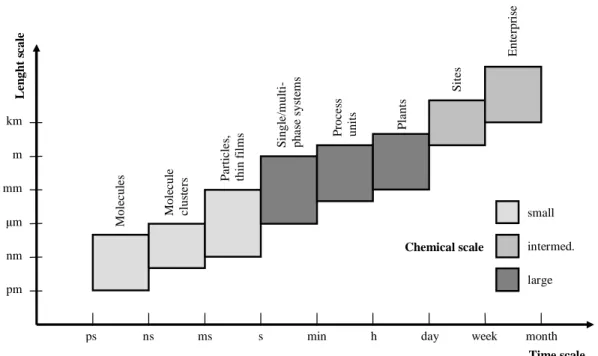
Figure 1.1: Time and scale levels in process engineering. Dierent scales dene dierent engineering problems.
and optimization tools are increasingly used in the industry besides of the design process at every level of subsequent plant operations [2], which obviously needs extraordinary communication between design, manufacturing, marketing and management. Such communication should be centered on modeling and simulation due to the need of the integration of the whole product and process development chain in all time and scale levels of the company (see Figure 1.1).
Nowadays, isolated models are used for dierent and limited purposes on dierent levels of the technology (if they exist at all). These models are het- erogeneous not only because they have dierent purposes, but also because information for the modeling and identication of the processes can be ob- tained from dierent sources:
- mechanistic knowledge obtained from rst-principles (physics and chem- istry),
- empirical or expert knowledge expressed as linguistic rules,
- measurement data obtained during normal operation or from an experi- mental process.
Dierent modeling paradigms should be used for an ecient utilization of these dierent sources of information.
Search and research
Planning Technological department
Production Business group Process analysis Planning model Techn. model Production model Business model
Time Reaction Kinetics
Measured data
Process technology
Process control
Operational methods
Operator training
Model- predictive
control
Process optimalization
Economic optimalization
ERP
Conceptual design Plant design Control impl. Procedure dev. Operator training Production Plant life-cycle
Plant construction
Knowledge
Figure 1.2: Knowledge management in "life-cycle modeling" and integrated modeling - a concept by Dow Chemical Co. Models are applied at every level of a technology and used to transfer information from conceptual design to the optimization of the production.
Therefore, novel methodologies are needed to integrate heterogeneous infor- mation sources and heterogeneous models. As it will be shown in the following subsections, this approach has been realized by many researchers in several ways.
1.1.1 Life-cycle of process models
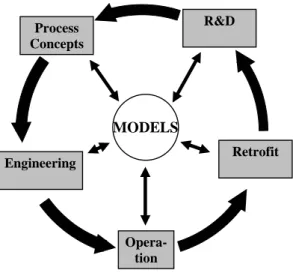
Leading chemical product companies, like DuPont and Dow Chemical Co., stand for life-cycle modeling, where an overall model is applied at every level of a plant, i.e. "the model integrates the whole organization" [3]. Dierent scales of models on Figure 1.1 mean dierent levels of knowledge as fragments about the whole company's structure from the early design phases until the op- eration phase. This led to the the idea of life-cycle modeling: integrating and connecting the model islands, which use dierent approaches and tools in each life-cycle phase and thus transfer the information and knowledge between the stages [4]. Figure 1.2 shows the knowledge management of life-cycle modeling by Dow Chemical, while Figure 1.3 shows its applicability in process optimiza-
R&D
Engineering Process Concepts
Retrofit
Opera- tion MODELS
Figure 1.3: The concept of life-cycle modeling for continuous process optimiza- tion.
tion: the continuous improvement cycle centered around the integrated models [5].
Currently, one can talk about only 'model islands' as multi-scale aggre- gates that aim the concept of life cycle modeling hence multi-scale modeling approach is a good initialization to meet the high level of expectations [6].
From modeling point of view, multi-scale models can be classied on the basis of interaction between the dierent scales and thus they form dierently integrated frameworks based on these connections of submodels [7]:
- Multi-domain. Numerous separated model domains exist according to their information level; their connection is dened by bridge applications.
- Embedded. Lower-scale models are elements of higher scales, like reaction kinetics (lab-scale) in a reactor model (operational scale).
- Parallel. Models on the same domain have dierent dominations based on their dierent purposes, like a detailed kinetics and simplied hy- drodynamic model versus a detailed hydrodynamic and simple kinetics model.
- Serial. The information of a lower scale is transferred to the higher scale model by a model transformation or direct information ow.
- Simultaneous. No macro-scale model exists, its variables are constructed from micro-scale results.
Regarding the question how such multi-scale models can be constructed, dierent policies are available based on the 'information density' of scales (i.e.
we start from where we have the most information for model building), like bottom-up, top-down, middle-out or even concurrent methods.
From chemical engineering point of view, no unifying theory governing all the complex structures exists, but three concepts can be distinguished [8]: de- scriptive, describing the appearance of structures without paying attention to the mechanism of the formation of the structures and the relationship between the dierent scales; correlative, formulating the phenomena at higher scales through analyzing the interaction at lower scales; variational, revealing the relationship between scales by formulating the stability condition of the struc- ture. The correlative method is capable of describing correlations between the scales and the levels of scales, it encapsulates the complexity at each level [9], which makes it applicable for semi-mechanistic model identication.
Multi-scale modeling had a wide range of research elds and applications in the literature (references in [8] are a good starting point).
1.1.2 Model-based process analysis, control, monitoring and optimization
Model types
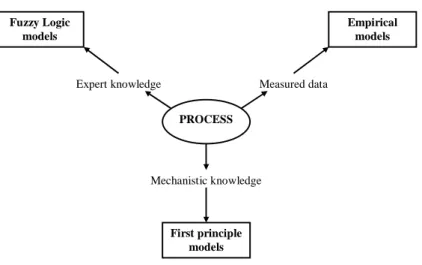
As it was already mentioned, dierent sources of information lead to dierent knowledge about the process thus dierently applicable models can be devel- oped (see Figure 1.4). Obviously the accuracy (performance), interpretability or generality attributes of the achieved model highly depend on the information source as well.
In chemical engineering practice, the experimentally measured process data based models are also called a posteriori (or black box) models where model structure is unknown, while mechanistic knowledge based models are called a priori (or white box) models. The application of fuzzy logic models is a novel approach developed in the past decade, which rapidly spreads in process analysis and control area [10]. Semi-mechanistic (gray or hybrid) models are achieved by mixing a posteriori model elements with a priori model parts in order to ll the gaps of unknown phenomena in the model. The 'whiteness' of the model depends on the ratio between the two model types. Moreover,
PROCESS Fuzzy Logic
models
Empirical models
First principle models Mechanistic knowledge
Expert knowledge Measured data
Figure 1.4: Attainable process models based on dierent information sources.
application of hybrid models can be a bridge between scales in multi-scale models.
Regarding time domain, the continuous time models are usually closer to physical considerations, whereas the discrete-time system behavior is consid- ered to be dened at a sequence of time instants related to measurements. The discrete-time models are closely related to implementation problems of digital processing.
Process models in control
Among others, process control is also an inevitable area in chemical engineer- ing. It also helps the continuous development of currently operating or upcom- ing technologies through driving the process in its predominantly optimized way of production.
The most simple control strategy where process models play an important role is PID-controller based control. This strategy can be applied eectively on controlling a single variable without extensive process knowledge for pro- cesses with dierent dynamics [11]. For a complex system, it means that each control loop needs to be considered independent and PID controllers are tuned individually. This can be done by using a reduced SISO interpretation of the process model or all other model inputs are kept constant in the original model.
Additionally, there are techniques to tune PID controllers at once parallel for dependent control loops in MIMO systems as well [12].
PID controllers have many interpretations and are applied at basic con- trol level of the DCS systems [13]. Nevertheless the implemented basic PID
algorithms do not have an explicit built-in process model for control, only sim- plied models are identied for parameter tuning of the controller. Several tuning techniques were developed, like Ziegler-Nichols [14], Cohen-Coon [15], direct synthesis method [16], which use a rst order plus time delay (FOPTD) representation of the system to be controlled. As many distributed param- eter systems cannot be modelled via FOPTD models, new techniques were developed for second order and second order plus lead models as well [17].
In the following, some advanced model-based control strategies are pre- sented, which explicitly utilize a model of the process:
- Internal model control (IMC). The IMC structure consists of a controller, a process model and a process. In an internal model control arrangement, the process model is placed parallel with the real system. The dierence between the system and model output represents the modeling error plus un-modeled process disturbances. This dierence is then fed back into the controller where it is used to compensate disturbance and eects of the modeling error. Detailed description can be found in [18, 19].
- Adaptive control. To be able to follow up time-variant parameter changes of a system, adaptive control strategy can be applied. This strategy utilizes the process model for parameter identication at every sample period and the adaptation mechanism converts the estimated system parameter changes into new controller design [20].
- Model-based robust control. Robust control of systems is based on the H-innity (H∞) control theory, which characterizes the control problem as an optimization problem for controller design of robust performance or robust stabilization. Drawbacks of the technique are the necessity of extended mathematical understanding and good model basis. For this later task, Linear Time-Invariant (LTI) or Linear Parameter-Varying (LPV) models are applied in the literature (e.g. [21, 22] and [23, 24]).
The LPV model is essentially a parameterized family of LTI models. LPV models are advantageous in the sense that they guarantee stabilization for the whole operating regime, large transients in switching are avoided and only one controller needs to be designed (instead of scheduling several LTI based controllers), but their performance can be poor. A comparison of the two model approaches can be found in [25].
- Model predictive control (MPC). MPC refers to a class of control algo- rithms, which utilize an explicit process model to predict future responses of a process. At each control interval an MPC algorithm attempts to optimize future process behavior by computing a sequence of future ma- nipulated variable adjustments. The rst input in the optimal sequence is then sent into the process, and the entire calculation is repeated at subsequent control intervals [26].
Based on these basic control strategies, several combined model-based con- trol mechanisms have been developed, like adaptive internal model control [27], adaptive internal fuzzy model control [28] or linearized IMC-MPC strat- egy [29].
From all the above mentioned strategies, MPC is the most widely applied as part of advanced process control systems while using simple PID algorithms at local control level. A survey of these can be found in [30] with numer- ous citations regarding the evolution of MPC. Currently, there are several industrial advanced process control packages on the market which apply the multi-variable model predictive control technology, like Prot Controller from Honeywell Inc. or APC Suite from Yokogawa Inc. The application of such advanced process control technologies denitely enables pushing the process to a higher level of productivity and delivering bottom line improvement.
Process models in analysis and optimization
Additionally to the crucial role of process models in control, process models are widely applicable for various purposes. Without trying to collect all of them, major areas are listed in the following with some citations as typical examples from thousands of related publications:
- Prediction or forecasting can serve to obtain better knowledge of the process, to verify theoretical models, to predict new phenomena, etc.
[31, 32]. In this context, it is important to represent external actions and external disturbances and to use knowledge of statistical characteristics of random variables, as there is usually little theoretical or practical possibility of determining such characteristics in advance.
- Control system analysis and design provide a rich eld for the application of modeling and identication [33, 34, 35], since application of models
allows quantitative predictions to be made concerning crucial features of control systems such as stability conditions and the development of oscillatory behavior.
- Models often serve as the basis of monitoring or supervision, error/fault detection and isolation and process diagnosis in large systems [36, 37, 38, 39].
- Model based alarm management/ltering is an area close to fault detec- tion. Alarm systems help operators to correct dangerous situations thus avoid emergency shutdown system to intervene [40, 41, 42].
- Industrial processes in continuous operation require system optimization for their economy, which in turn requires very accurate modeling [43, 44].
- Soft sensors can provide information on process variables, which are di- rectly cannot be measured or their measurement is troublesome or too costly. Usually, these variables can be computed from other measure- ments based on suitable models [45, 46, 47].
- Simulation based on mathematical models is widely used for the assess- ment of model complexity, for engineering design or for operator training, all of which require adequate modeling and adequate input [48].
- As a specic application of simulation purposes, operator training sys- tems have been developed to train novice operators and to enhance con- trol and maintenance abilities of operators for standard procedures and emergency operation. In this way, it is able to bridge the gap between required skills and technical experience [49]. Mostly, these advanced dy- namic model based simulator systems include replica operator stations connected to instructor PC in order to closely emulate reality and eval- uate results [50, 51].
- As systems have become more complex, operators' responsibility and role in decision making turned into a highly important requirement, for which operator support systems were developed. "An Operator Support Sys- tem (OSS) is a combination of information systems, meeting structures, mathematical models and education/training programs, aimed at the support, development and improvement of the process operation"[52].
These various tools guide the operators in decision making to run the technology more optimally in an integrated way [53, 54]: all the previ- ously mentioned model-based techniques (and the data-based techniques detailed in Section 1.2) can serve as parts of an operator decision support system. For OSS applications, several solutions and such elements can be found in the literature like in [55, 56, 57].
Modeling and simulation products on the market
Due to the extraordinary growth in information technology in the past decades, numerous softwares and software packages came into existence for various pur- poses and based on dierent programming languages to help modeling and sim- ulation of chemical engineering processes. They are applied in design as well as in operation of existing plants for process optimization, units troubleshoot- ing or de-bottlenecking, plants revamping or performing front-end engineering analysis. Only the major ones are listed here, without aiming at completeness:
- ProSimPlus (ProSim), a simulator environment for wide range of steady- state industrial processes.
- PRO/II (SimSci-Esscor), steady-state simulator for oil and gas industry integrable with BATCHFRAC by Koch-Glitsch for batch process simu- lation and extendable with interface to MS Excel (SIM4ME).
- Aspen ONE (AspenTech Inc.), a complete software package containing steady-state and dynamic process simulators for chemical industry (As- pen Plus and Aspen Dynamics), and steady-state simulators for batch processes (Aspen Batch Plus).
- HYSYS (formerly Hyprotech Ltd., then AspenTech and Honeywell Inc.), part of the Aspen ONE package steady-state and dynamic process sim- ulators for oil and gas industry (Aspen HYSYS and HYSYS Dynamics).
- UniSim family (Honeywell Ltd.) consists of four elements (steady-state design, operations, optimization and dynamic simulation packages), which are connected in the so called Unisim simulation life-cycle.
- ChemCAD (Chemstations Inc.), similarly to Aspen ONE, this pack- age provides solutions to steady-state (CC-Steady State), dynamic (CC-
Dynamic) and batch (CC-Batch) simulation, heat exchanger design (CC- Therm) or data reconciliation/parameter estimation (CC-Recon).
- Simulink (The Mathworks Inc.), a general purpose dynamic simulator, which integrates into the Mathwork's MATLAB environment, to be able to achieve overall functionality in all areas (modeling, identication, anal- ysis, control).
- gPROMS Product Family (Process Systems Enterprise Ltd.). gPROMS ModelBuilder is applicable for steady-state and dynamic simulation as well as optimization, while gPROMS Objects creates interfaces to several other, widely used softwares, like MATLAB (gO:MATLAB), Simulink (gO:Simulink), computational uid dynamics (gO:CFD) or Aspen or PRO/II (gO:CAPE-OPEN) in order to utilize both softwares' advan- tages.
In these software environments, common chemical engineering unit models and thermodynamic methods are built in and are easily connectible through a graphical screen thus designing a process owsheet is very user-friendly and fast. Model parameters are taken from the software's own data library or can be set by model identication functions.
The main disadvantage of these softwares is that they have the function- ality only for what is built in. At this point, Simulink as a general purpose simulator based on general building blocks gets a real advantage, which be- comes extraordinary if one integrates the Simulink models with other MAT- LAB packages, like Data analysis, Statistics or System Identication toolboxes.
These attributes turn MATLAB and Simulink into the most widely applicable prototype developer and scientic programming tool on the market.
Another direction on the market - as a tangible sign of aiming at integrality - is that control system provider companies already realized the potential in simulation softwares: in 2004, Honeywell Inc. acquired the intellectual rights of HYSYS simulation software from Aspen Technologies Inc. in order to extend the capabilities of its Process Knowledge System (Experion PKS) and such to extend the operator training business applicability and protability [58].
1.2 Process data - from source to applications
The high automation level provides the opportunity to collect more information (more variables) from the process and additionally, due to the large develop- ments in data storage capacities, the sampling frequency of the collected data has increased signicantly as well. On the other hand, the availability of these modern data acquisition systems has increased as well: compared to a system 20-25 years ago, modern data acquisition systems cost 20 times less while run- ning on higher performance level [59]. To serve this horizontal and vertical increase in data amount - it doubles every year -, an exceptional hardware and software development takes place in many application elds. Hence from being under-informed in the past we turned into over-informed: information moun- tains have arisen, but only ten percent of the enormous amount of collected and stored data is analyzed for further aims [60].
1.2.1 Data acquisition and retrieval
In the early years of chemical engineering processes, systems were controlled manually and data collection or data acquisition was performed by plant en- gineers as human observers as no central control system existed.
During the continuous enhancement of process control, digital equipments substituted analogue ones and analogue measurements. In modern automated systems, a redundant eld bus system is installed to bridge digital eld instru- ments with the central process control system elements connected through an inner system bus. At this level, distributed control systems are implemented with several subfunctions like data storage, basic data visualization and inter- faces to corporate business information system. Such systems were TDC2000 from Honeywell Inc., CENTUM from Yokogawa, UCS3000 from Bristol. As hardware instruments got more standardized, these companies turned to ad- vanced software packages.
These phenomena led to the development of open control systems (OCS), which are based on standard operational systems (like MS Windows, Unix) and on open network protocols. A basic attribute of these systems is inter- operability, thus products from dierent vendors can be built in the system as building blocks. OCS solutions were rst applied in supervisory control and data acquisition systems called SCADA. A SCADA system can be con- sidered as a software package, which is installed on a standard set of hardware
equipments using standard open network protocols for communication [61].
The two main weaknesses of data acquisition systems are not handling heterogenity and data inaccessibility:
1. Data from dierent sources and in dierent format cannot be handled in one environment, e.g. a priori knowledge, empirical or phenomenological knowledge cannot be incorporated into sampled data. Lots of research has been done on the problems of data compression and data integrity.
Next section deals with several solutions to these problems.
2. A mid-size chemical plant has about few thousand measured variables sampled from seconds to hours, a hundred manipulated variables to con- trol a few critical product quality related variables, which results in terra- bytes of data every year. It would mean ineciently large data storage capacity if one wants to analyze not only prompt but historical data.
In this section solutions to these problems and commercial products already available on the market are presented.
Integrated information storage and query
To solve the problem of heterogeneous data integrity several approaches have been developed. Complexity of integrating the information with their various describing models is not easy to handle, hence solution methods are dierent.
Two main solution groups can be identied: where the integrality problem is solved at the query level or at the construction level of the integrated in- formation system. Collins et al. developed an XML based environment [62], while Wehr suggests an object-oriented global federated layer above informa- tion sources [63]. In [64], Bergamaschi et al. presents an object-oriented lan- guage as well with an underlying description logic, which was introduced for information extraction from both structured and semi-structured data sources based on tool-supported techniques. Paton et al. developed a framework for the comparison of systems, which can exploit knowledge based techniques to assist with information integration [65]. Another approach to handle the het- erogeneity of information sources is the application of data warehouses (DWs) to construct an environment lled by consistent, pre-processed data [66].
The main advantage of a DW is that it can easily be adapted to a DCS and other information sources of a process while it works independently (see Table 1.1)[67].
DCS related database Data warehouse Function Day-to-day data storage Decision supporting
for operation and control
Data Actual Historical
Usage Iterative Ad-hoc
Unit of work General transactions Complex queries
User Operator Plant manager, engineer
Design Application-oriented Subject-oriented Accessed records Order of ten Order of a million
Size 100 MB-GB 100 GB-TB
Degree Transactional time Inquiry time
Region Unit, product line Product
Table 1.1: Main dierences of a DCS related database and a data warehouse.
Appropriate time-series representation for data compression
Data compression is rather a contribution of the signal and image processing society where lossless information transmission is a key feature within limited time or bandwidth. In chemical engineering society, data compression has beside storage capacity rationalization another important issue: retrieve the data in a manner that they are easily interpretable for later engineering tasks.
In this manner, data compression problem is turned into trend representa- tion problem. Lin et al. gave a classication of process trend representation methods in [68], which can be seen in Fig 1.5. Many of these representation techniques refer to segmentation of time series, which means nding time in- tervals where a trajectory of a state variable is homogeneous [69], representing data by its segments and storing only the segments instead of raw data.
Time series representations
Data-adaptive Non-data-adaptive
Piecewise Agregate Approximation Spectral
Random mappings Wavelets
Piecewise Linear Approximation
Adaptive Piecewise Const Appr.
Natural Language
Strings Orthonormal Bi-orthonormal Discrete Fourier Transform
Discrete Cosine Transform
Interpolation Regression
Lower Bounding
Non-lower bounding
Haar Daubechies dbn (n>1)
Coiflets Symlets Trees
Symbolic Piecewise
Polynomial
Singular Value Decomposition Sorted
coefficients
Figure 1.5: Hierarchy of various time series representations for data mining.
14
Products on the market
The modern distributed control systems (DCSs), which are widely imple- mented in modern automated technologies, have the direct access to the eld instrument signals and measurements, while have data storage functions as well. Today several software products in the market provide the capability of integration of historical process data of DCS's: e.g. Intellution I-historian [70], Siemens SIMATIC [71], the PlantWeb system of Fisher-Rosemount [72], Won- derware Factory- Suite 2000 MMI software package [73] or the Uniformance PHD modul (Process History Database) from Honeywell [74].
Concluding, modern data acquisition systems need to be capable of han- dling diverse types of data in a way that data are applicable for further anal- ysis. The next section deals with this topic where a widely-applied procedure is presented.
1.2.2 Information extraction from process data: Knowl- edge Discovery in Databases
Integration of heterogeneous data sources is strongly connected to knowledge discovery and data mining [75, 76]. One of its main purposes is to store data in a logically constructed way that some deeper information and knowledge can be extracted through data analysis. Knowledge discovery in databases (KDD) is a well known iterative process in the literature, which involves several steps that interactively take the user along the path from data source to knowledge [77].
Figure 1.6 shows the KDD process and its connection to the process devel- opment scheme: KDD can be considered as the analysis step of the technology improvement process. In the following, we go through the steps of KDD, highlighting the presence of "data mining in chemical engineering" (note, that although data mining is a particular step of KDD, it is often associated to it as an independent technique).
1. Data selection. Developing and understanding of the application domain and the relevant prior knowledge, and identifying the goal of the KDD process.
2. Data pre-processing. This step deals with data ltering and data recon- ciliation.
Selection
Preprocessing
Transformation
Data mining
Interpretation
Data
Knowledge
Data
Knowledge
Technology
Analysis
Figure 1.6: Knowledge Discovery in Databases process (left) and the data- driven process development scheme (right).
3. Data transformation. Finding useful features to represent the data de- pending on the goal of the task.
4. Data mining. It is an information processing method, the extraction of interesting (non-trivial, implicit, previously unknown and potentially useful) information or patterns from data.
5. Interpretation of mined patterns, i.e. discovered knowledge about the system or process. The interpretation depends on the chosen data mining representation.
Data selection, pre-processing and transformation activities are often re- ferred to as the data preparation step. A wealth of approaches have been used to solve the feature selection problem, such as principal component analysis [78], Walsh analysis [79], neural networks [80], kernels [81], rough set theory [82, 83], neuro-fuzzy scheme [84], fuzzy clustering [85], self-organizing maps [86], hill climbing [87], branch&bound algorithms [88], and stochastic algo- rithms like simulated annealing and genetic algorithms (GAs) [89, 90].
Process data have several undesirable attributes which need to be handled before any analysis can take place: they may be time-dependent, multi-scale, noisy, variant and incomplete at the same time. All these problems need to be solved in the data preparation steps, hence it takes the largest part, approx. 60
% of eorts in the whole KDD process. For industrial data reconciliation, OS- Isoft and Invensys have developed packages such as Sigmane and DATACON [91, 92].
In the data mining step, the goals are achieved by various methods:
- Clustering. Cluster is a group of objects that are more similar to one another than to members of other clusters. The term "similarity" should be understood as mathematical similarity, measured in some well-dened sense. Clustering is widely used for feature selection [86], feature extrac- tion method, which is applied in operating regime detection [93, 94], fault detection [95, 96] or system identication, like model order selec- tion [97, 98, 99], state space reconstruction [100].
- Segmentation. Time series segmentation means nding time intervals where a trajectory of a state variable is homogeneous. In order to formal- ize this goal, a cost function with the internal homogeneity of individual segments is dened. The linear, steady-state or transient segments can be indicative for normal, transient or abnormal operation, hence seg- mentation based feature extraction is a widely known technique for fault diagnosis, anomaly detection and process monitoring or decision support [101, 102, 103, 104]. A more detailed description and illustration can be found in Section 1.2.3.
- Classication. Map the data into labelled subsets, i.e. classes, which are characterized by their specic attribute called the class attribute. The goal is to induce a model that can be used to discriminate new data into classes according to class attributes. In chemical engineering problems, classication is used in fault detection, anomaly detection problems [84, 102, 104, 105, 106, 107].
- Regression. The purpose of regression is to give prediction for process or so called dependent variables based on the existing data (independent variable). In other words, regression learns a function which maps a data item to a real-valued prediction variable and it discovers functional relationships between variables [108, 109]. Uses of regression include curve tting, prediction (forecasting), modelling of causal relationships and testing scientic hypotheses about relationships between variables.
Applied mainly in system identication problems, see e.g. [110].
Representation of patterns of interest, i.e. output of data mining, can be in various forms like regression models [94, 84, 102, 105], association rules [111]
or decision trees [104, 106].
As last step of the knowledge discovery process, mined patterns, i.e. dis- covered knowledge about the system or process needs to be interpreted. The interpretation depends on the chosen data mining representation.
Exploratory Data Analysis (EDA) deals with visualization of the mined patterns. Although it is often stated as an independent analysis technique, it can be considered as a special application of the KDD process, where the knowledge is presented by the information embedded into several types of visualization tools. It focuses on a variety of mostly graphical techniques to maximize insight into a data set.
The seminal work in EDA is written by Tukey [112]. Over the years it has beneted from other noteworthy publications such as Data Analysis and Re- gression by Mosteller and Tukey [113], and the book of Velleman and Hoaglin [114]. Data preprocessing step in EDA refers to several projection methods in order to be able to visualize high dimensional data as well: techniques of principal component analysis (PCA) [115], Sammon-mapping [116], Projec- tion to latent structure (PLS) [117], Multidimensional Scaling (MDS) [118] or Self-Organizing Map (SOM) [119] are applicable, from which PCA, MDS and SOM techniques are applied in the later chapters. Data mining methods also use these techniques, but in EDA projection is used for visualization purpose.
First, to give a short introduction to plots of this area, denition of a quantile is needed: it means the fraction (or percent) of points below the given value. That is, the 0.25 (or 25%) quantile is the point at which 25% of the data fall below and 75% fall above that value. The 0.25 quantile is called the rst quartile, 0.5 quantile is called second quartile (or median) and 0.75 quantile is the third quartile. A quantile-plot serves as a good indication for cumulative probability function of a given time series by visualizing the distribution of the data set.
Quantile-quantile plot (q-q plot) is a plot of quantiles of the rst data set against quantiles of the second data set thus they can serve as visual proof for correlation between two data sets. The basic idea behind is that if two variables have similar distribution, their tail behaviors are similar as well, thus q-q plots are applicable to identify connections between them. Both axes are in units of their respective data sets. That is, the actual quantile level is not plotted. For a given point on the q-q plot, we know that the quantile level is the same for both points, but not what that quantile level actually is. If two sets come from a population with the same distribution, points should fall
approximately along the reference line. Based on q-q plots, connection between operating cost, energy consumption and process variables can be detected.
Considering three quartiles, minimum and maximum of the given data set, a ve-number-summary by Tukey can be collected, which is visualized in a box- plot giving very compact and informative graphical results about the given set (for example about production).
Besides the above plots, EDA techniques have a wide spectrum including plots of raw data (histograms, probability plots, block plots), basic statistics or advanced multidimensional plots (scatterplot matrices, radar plots, bubble charts, coded maps, etc.).
The most common software for EDA is MS Excel with numerous non- commercial add-ins, but there are several products on the market as well:
IBM's DB2 Intelligent Miner (which is no longer supported), Mathworks's MATLAB Statistics Toolbox [120] and the open-source WEKA developed by Waikato University [121].
Note that most EDA techniques are only a guide to the expert to under- stand the underlying structure in the data in a visual form. Hence their main application is process monitoring [122, 123], but these tools are already used for system identication [124], ensuring consistent production [125] and product design as well [126].
As it can be seen from the numerous citations, solutions based on the KDD process were proven to be extremely useful in solving chemical engineering tasks as well and showed that instead of simple queries of data, potential prot can be realized using the knowledge given by data analysis. The mined and discovered knowledge about the system or process is fed back to the beginning of the process to help continuous development (see Figure 1.6).
1.2.3 Overview of recent advances on time series similar- ity
In process engineering, time series similarity was always a popular topic be- cause it is not a trivial problem to create functions and/or numeric values from a highly subjective abstraction [103]. Actually, every method tries to approach the ability of the human mind [127]: e.g. if process engineers and process op- erators want to control a system, then they compare the resulted trajectories with their pre-imagined ones and decide whether the control strategy was
suciently good or bad. It is also a dicult task to copy the operators' qual- ication strategy that decides how similar two trajectories are, because their work experience automatically neglects unimportant features in the trend and handles shifts in time.
After the optimal pre-imagined trajectories are mapped into time series data as a function of time, and any specic similarity (or dissimilarity) measure is predened, time series similarity algorithms can begin to work to compare these data sets. A large dierence between these algorithms and human mind is that algorithms work in an objective manner, so qualitative trend analysis (QTA) or time series analysis is based on objective functions and values instead of subjective fuzzy categories, like 'quite good' or 'moderate high', thus its results can be more adequate and reliable.
Another advantage of QTA is that it helps the users to decide in a multi- objective environment where modern automated processes provide large amount of data in every minute. It is getting more and more dicult to monitor the trends and trajectories for a human observer, where undiscovered correlations may be in the highly multidimensional data space [104].
The original trend analysis techniques were rather nancial than engineer- ing tools. They were applied on sales forecasting or pattern recognition for seasonality based on historical data [128]. Recent algorithms have rather pro- cess engineering relations to analyze process data for e.g. fault diagnosis or monitoring applications. In the following, a brief review is given related to (rather quantitative) trend analysis.
The simplest way of comparing two equi-sized and normalized data se- quence ordered by time is dening a distance measure and a threshold value, where the sum of calculated distances should be below that threshold to con- sider two trends as similar. These distance measures can be Lp-norms, where L2 means Euclidean distance norm in the metric space. To handle time shifts as well, dynamic time warping (DTW) was developed, which resulted in an optimal alignment of two time series based on dynamic programming [129].
Its continuity constraint does not allow injecting gaps in the alignment, so it cannot align dierent-sized sequences. These disadvantages are solved in another technique called longest common subsequence (LCS) [130]. A lot of research has been done on DTW and LCS like measures of time series similarity [131][132].
Similarity is also a common feature in other scientic areas where qualita-
tive analysis of symbolic sequences take place, e.g. string comparison is typical and well-described in the eld of text retrieval and bio-informatics. Optimal alignment of amino acid or nucleotide sequences is solved by a dynamic pro- gramming based fast algorithm developed by Needleman and Wunsch [133]. It is analogous to DTW, but it allows injecting gaps into a sequence or mutating a part of the sequence, so it has the advantages of LCS as well. Additionally, there are not only injection and deletion, but also mutation and substitution operators to present how far the evolved sequences are from each other. In bio- informatics, instead of metric distance measures, empirically computed similar- ity matrices are widely spread (PAM and BLOSUM matrices)They usually do not fulll all requirements of a metric (non-negativity, identity, symmetry, sub- additivity) but are ecient base for amino-acid sequence comparison. Apply- ing user-dened similarity values instead of empirical transformation weights, this general sequence aligning technique is able to reach the goal of optimally aligning symbolic sequences with dierent length.
As an input of pairwise sequence alignment, data need to be preprocessed in order to have string sequences instead of variable values. Hence a technique is needed that results in an adequate symbolic representation of a trend. A hier- archy of trend representation techniques with numerous references is presented in [68]. Most of these are more preferred in data mining community than sym- bolic representation, and these are already combined with many comparing algorithms, like piecewise linear approximation (PLA) based DTW [134], but symbolic representation based trend analysis is still highly unnoticed. Actually, to the author's knowledge, Symbolic Aggregate approXimation (SAX) devel- oped by Lonardi et al. [68] is the only work in this area, which uses piecewise aggregate approximation as a segmentation basis for string conversion. SAX itself is a very powerful trend compression and representation technique, but it is rather quantitative in the sense that it encodes dierent value levels into symbolic sequence of a trend.
To get to a qualitative analysis of trends by symbolic representation, this thesis proposes the application of the formal framework developed by Che- ung and Stephanopoulos to represent our process data as triangular episode sequences [135]. Triangular episodes use the rst and second derivatives of a trend on a geometrical basis, hence seven primitive episodes can be achieved as characters, which note the shape of the time series over a time interval (see Section 3.1). Many researchers in the literature found feature extrac-
tion by episodes useful for fault diagnosis, decision support service or system monitoring, but also a lot of them modied the denition or set of primitives [104, 136, 103, 101]. In [102] episodes are partitioned into fuzzy episodes by change of magnitude and duration to have a larger symbol set for representing trends.
Concluding all the above cited results, there is still a need for eective algorithms that can convert quantitative time series data into qualitative trend analysis and are able to nd similarities in those trends.
1.3 Integrated application of process data, sim- ulation models and experiment design
As it was shown in the previous section, process data, process models and their application as simulators are all present in the chemical engineering practice, but mostly these diverse research elds are not integrated together nor inte- grated individually. The application of process models is typical in planning areas of chemical engineering, where steady-state process design and dynamic control strategy development are the main tasks [137]. Therefore, integrated design of processes and their model based (quality) control system had its attention in the literature based on economical analysis [138, 139, 140] or op- erability indicators [141].
On the contrary, the recycled usage of models in automation and control is not widely realized at the operational level, thus it might be concluded that the protability of life-cycle-modeling and model re-usage is still out of the research scope [5]. A possible cause of that problem may be that process knowledge is already distributed: process models owned by process and control system designers, laboratory and plant experience of plant engineers is not incorporated into an integrated framework.
The integration of process data and data analysis tools to modeling and simulation is tending to be applied through the experiment design process [142], which is also an iterative cycle as knowledge discovery. Figure 1.7 presents the systematic linkage of integrated experimentation, modeling and simulation [143].
To get more information out of the experiment measurements, model-based experiment analysis (MEXA) is needed, which shows that modeling, simula-
Experiment
Design Experiment
Measure- ment techniques
Inverse problem formulation and
solution
Numerical simulation
Mathematical models
A priori knowledge and intuition Exp. conditions
Input parameters Computed states
Measurements
Input states, confidence regions
Iterative model refinement
Extended understanding
Iterative experiment improvement and measurements
Init. conditions
Model structure, param.
Figure 1.7: Systematic link of modeling and experimentation.
tion and experimentation are highly depending activities, which should be handled in an integrated way. As presented in Figure 1.7, this linkage de- nitely enlightens the following inevitable features of a technology improvement process:
- Extended understanding of underlying processes (operating regimes, con- straints, etc.);
- Experiment improvement for further analyzes (experimental conditions, what and where to measure);
- Model renement (model structure, parameters, condence regions);
- Control improvement (basic control and model based control parame- ters);
- Simulation environment renement (initial states);
These considerable advantages turn experiment design a valuable "brick" in the wall of integrated process improvement schema. The accuracy of model pa- rameters largely depends on the information content of the experimental data presented to the parameter identication algorithm [144]. Therefore, Optimal Experiment Design (OED) can maximize the condence on model parameters through optimization of the input prole of the system during model identi- cation. For parameter identication of dierent dynamic systems and models, this approach has already been utilized in several studies [145], [146],[147],[148], [149]. OED is based on an iterative algorithm where the optimal conditions
of the experiments or the optimal input of the system depends on the current model, whose parameters were estimated based on the result of the previous experiment. Consequently, experiment design and parameter estimation are solved iteratively, and both of them are based on nonlinear optimization.
That means in practice, the applied nonlinear optimization algorithms have great inuence on the whole procedure of OED, because for nonlinear dynam- ical models the design of the experiment is a dicult task. This problem is usually solved by several gradient-based methods e.g. nonlinear least squares method or sequential quadratic programming. Several gradient computation methods are described in [150]. In [151] extended maximum likelihood theory is applied on optimizing the experiment conditions.
1.4 Motivation of the thesis, roadmap
Concluding the previously described need for integration, the main motivation of the thesis is to create an integrated framework, which exploits all three components in Fig. 1.7 i.e. whereto data mining, modeling and simulation, experimentation tools can be incorporated. To achieve model integrity, the existing models should be reapplied, the non-existing models created, and all the models connected in an appropriate way. If it is possible to collect suciently large amount of data from the process, Knowledge Discovery in Databases (KDD) technique can be applied to extract information focused on the maintenance or control operation problems to make the production more ecient [152].
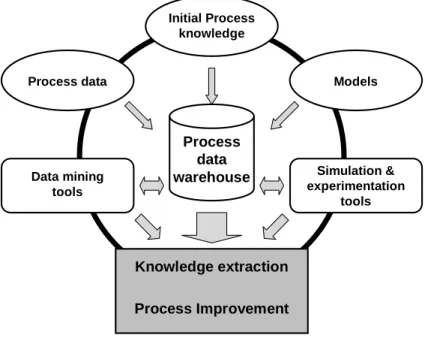
As I suggest in Figure 1.8, the information ow of such integrated method- ologies should be centered around a process data warehouse in a process im- provement cycle. Sources come from available process data, current process knowledge (rules, constraints, etc.) and an integrated global model of prod- ucts, process and process control. As these information are collected in the data warehouse, data mining tools, modeling and experimentation tools can be applied to aid the improvement of the process while extracting further knowledge.
This study concentrates on integrated handling of models. It touches the topic of data analysis but data mining tool development as part of the inte- grated framework was a key topic in the PhD study of one of my colleagues, Ferenc Péter Pach, entitled as "Rule-based knowledge discovery for process data
Process data warehouse Process data
Initial Process knowledge
Models
Data mining tools
Simulation &
experimentation tools
Knowledge extraction Process Improvement
Figure 1.8: An integrated framework for process improvement.
mining", thus it is out of the scope of this thesis.
Concluding all the sources, tools and possibilities, four levels of integrity can be distinguished as stairs to a thoroughly integrated information environment:
Level 1: Data integrity. Connecting all data sources vertically and horizontally in the company into a data system (database, data mart, data universe, data warehouse), from future business plan data through schedule order data to production/logistics/laboratory measurement data. Reporting functions attached to these basic information sources can alone guide decisions in every level of the company.
Level 2: Model integrity. Connecting multi-scale models to data sources leads to large information base extension, experiments on models and model outputs support (among others) business decisions, estimation of current and future eciency and optimization asset utilization.
Level 3: Knowledge integrity. Taking the initial (process, business, etc.) knowl- edge connected to the central information base and expanding it by deeper understanding extracted by simulation or data mining while re- solving generated contradictions leads to knowledge integrity in the sys- tem.
Level 4: Information integrity. Having all the three levels in a systematically
structured way results in an extended, multi-level Enterprize Resource Planning (ERP) system.
As such integration level exceeds the scope of a PhD thesis, commercial Enterprize Resource Planning systems cover only parts of such a exible, in- tegrated information system and even for small companies it would take years to connect their islands into "a knowledge continent", the current thesis tries to collect elements from every aspect of the previously described environment.
Consequently, the main goals of the thesis are the following:
1. Develop an integrated model based simulator where process model is integrated with control model, which can eectively serve as a base for process improvements and is connected to a data warehouse.
2. Improve experimentation for model parameter estimation by a novel ex- periment design technique.
3. Develop an easy-to-use but ecient data analysis tool for stored and simulated data.
All these developments and the process data warehouse, which they are centered around, were created within the research project of the Cooperative Research Centre of Chemical Engineering Institute entitled as "Optimization of multi-product continuous technologies" with implementation at the Polypropy- lene plant of Tisza Chemical Group Plc., Hungary.
According to the motivations and main goals explained above, the thesis is structured as follows:
Chapter 2 describes an integrated process simulator development for a poly- merization process with applications to product quality and operating cost es- timations, while Chapter 3 presents a novel segmentation based data analysis tool to be able to analyze data queried from or transferred to the data ware- house. As shown previously, process data and the simulator models are linked together through experimentation, hence a genetic algorithm based novel ex- periment design scheme was developed, which is detailed in Chapter 4. Finally, all the theses of the study are summarized in Chapter 5.
Chapter 2
Integrated modeling and
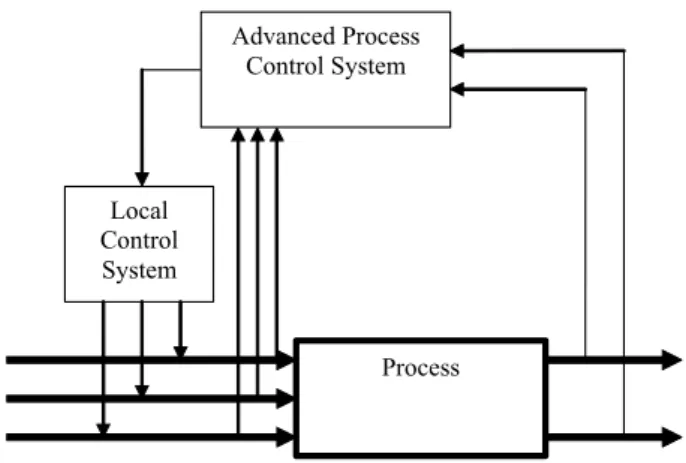
simulation of processes and control systems
Approaches to fulll customers' expectations and market demand in the chem- ical industry are under continuous development. In the near future communi- cation between design, manufacturing, marketing and management should be centered on modeling and simulation, which could integrate the whole product and process development chains, process units and subdivisions of the com- pany. Solutions to this topic often set aside one or more component from product, process and control models. As a novel know-how, an information system methodology is introduced in this chapter with a structure that in- tegrates models of these components with process Data Warehouse. In this methodology, integration means information source, location, application and time integrity. It supports complex engineering tasks related to analysis of sys- tem performance, process optimization, operator training systems (OTS), de- cision support systems, reverse engineering or software sensors (soft-sensors).
This chapter presents a realization of the proposed methodology framework introduced in Section 1.4. As part of a R&D project, the proposed method- ology was implemented as an information system prototype in an operating polymerization plant in Hungary.