RESEARCH
Scope marking and prosody in Hungarian
Beáta Gyuris1 and Scott R. Jackson2
1 Research Institute for Linguistics, Hungarian Academy of Sciences, 33 Benczúr utca, H-1068 Budapest, HU
2 University of Maryland, 7005 52nd Ave, College Park, MD 20742, US Corresponding author: Beáta Gyuris (gyuris.beata@nytud.mta.hu)
The paper presents an analysis of the results of three perception experiments that aimed to investigate the scope of postverbal quantifiers in Hungarian. These experiments found no correlations between wide vs. narrow scope readings of postverbal quantifiers and their stressed vs. unstressed pronunciations, contradicting a widespread assumption. In addition to the dominance of scope interpretation that corresponds to the linear order of constituents, previously unnoticed effects of the syntactic or thematic role of the postverbal quantifier and of the type of preverbal operator in the same sentence were found. These might indicate a more complex interaction of several factors or point to a greater role of extra-grammatical effects in determining the scope of quantifiers in Hungarian than previously assumed. The paper also addresses methodological issues that arise in the course of eliciting scope judgments experimentally.
Keywords: quantifier scope; prosody; perception experiment; Hungarian
1 Syntactic structure and scope in Hungarian: An introduction
The study of factors influencing the relative scope of operators in natural languages constitutes an important field of research at the syntax-semantics interface, which profited in recent years from a variety of experimental studies on different languages (cf. Szabolcsi 2010 and Bott et al. 2011 for overviews). The Hungarian language has traditionally been assumed to “wear its LF on its sleeve” (Szabolcsi 1997: 111), since, with the exception of the case of two postverbal expressions, the linear order of quan- tificational expressions (and other operators) reflects their relative scope. These data have been accounted for in the generative syntactic tradition by postulating a hier- archically structured preverbal field, where a constituent that precedes another one also c-commands it, and a non- hierarchical postverbal field (cf. É. Kiss 2002 for an overview).
This paper is concerned with one of the special cases where the default scope relations described above seem to be modifiable through different prosodic realizations of the con- stituents concerned. Katalin É. Kiss and László Hunyadi argued in several papers (to be discussed below) that postverbal quantifiers bearing heavy stress scope over preverbal operators either obligatorily or optionally in Hungarian (depending on certain properties of the quantifier and of the preverbal operator, discussed below). The aims of our inves- tigations reported on here were i) to see whether the scope reversal effect discussed by the above authors can in fact be confirmed experimentally, and ii) to find out whether the effect is really due to prosody or should be attributed to some other factors known to influence the scope of operators cross-linguistically.
Gyuris and Jackson: Scope marking and prosody Art. 83, page 2 of 32
In what follows, we introduce the basic assumptions about Hungarian sentence struc- ture and scope from the literature that we have taken for granted in the course of planning the experiments.
(1) below illustrates the hierarchical structure of the Hungarian preverbal field, following É. Kiss (2002).1 In this framework, [Spec,TopP] is the projection that is assumed to host topical DPs, i.e. those that can introduce individual discourse referents, whereas [Spec,DistP] is the projection where only distributive quantifiers can appear. The [Spec,FocP] projection hosts the focus constituent (to be discussed below). The ‘*’ marks iterable projections.
(1)
field (cf. É. Kiss 2002for an overview).
This paper is concerned with one of the special cases where the default scope relations described above seem to be modifiable through different prosodic realizations of the constituents concerned. Katalin É. Kiss and László Hunyadi argued in several papers (to be discussed below) that post- verbal quantifiers bearing heavy stress scope over preverbal operators either obligatorily or optionally in Hungarian (depending on certain properties of the quantifier and of the preverbal operator, discussed below). The aims of our investigations reported on here were i) to see whether the scope reversal effect discussed by the above authors can in fact be confirmed ex- perimentally, and ii) to find out whether the effect is really due to prosody or should be attributed to some other factors known to influence the scope of operators cross-linguistically.
In what follows, we introduce the basic assumptions about Hungarian sentence structure and scope from the literature that we have taken for granted in the course of planning the experiments.
(1)below illustrates the hierarchical structure of the Hungarian prever- bal field, followingÉ. Kiss (2002).1 In this framework, [Spec,TopP] is the projection that is assumed to host topical DPs, i.e. those that can intro- duce individual discourse referents, whereas [Spec,DistP] is the projection where only distributive quantifiers can appear. The [Spec,FocP] projection hosts the focus constituent (to be discussed below). The ‘*’ marks iterable projections.
(1) TopP*
Spec DistP*
Spec FocP
Spec VP
In the following example, which contains a DP in each of the preverbal positions indicated above, the scopes of the quantificational expressions are
1The other frameworks discussed in Section 2 share É. Kiss’s assumptions on the preverbal ordering of different constituent types, though not necessarily her views on how it should be modeled.
In the following example, which contains a DP in each of the preverbal positions indi- cated above, the scopes of the quantificational expressions are unambiguous: a quantifier c-commanding and preceding another one also has scope over it (É. Kiss 2002: 111).2 (2) [TopP Sok lány [DistP minden fiúnak [FocP két könyvet
many girl every boy.dat two book.acc [VP mutatott meg.]]]]
showed.3sg vm
‘Many girls are such that what they showed to every boy was (exactly) two books.’3
Other things being equal, “the heaviest grammatical stress” of the Hungarian sentence is assumed to fall on the first accentable position of the predicate part of the sentence, the latter being identical to the highest of the DistP, FocP and VP constituents (cf. É.
Kiss 2002: 111). In (2), this stress falls on the first syllable of the determiner minden
‘every’.
In the literature, significant attention has been devoted to consequences of the obser- vation that the range of quantificational expressions that can appear in [Spec,TopP], or the topic position for short, and [Spec,DistP], or the quantifier position for short, are not identical, and the interpretations of DPs that are allowed to appear in two different posi- tions change according to the position itself. (Cf. Szabolcsi 1997; 2010; É. Kiss 2002 and Csirmaz & Szabolcsi 2012 for overviews.)3
(3) illustrates some of the DP types Szabolcsi (1997) lists among the possible occupants of the topic and the quantifier positions, respectively.
1 The other frameworks discussed in Section 2 share É. Kiss’s assumptions on the preverbal ordering of different constituent types, though not necessarily her views on how it should be modeled.
2 Note that the reason why the immediately preverbal constituent in (2) is taken to occupy [Spec,FocP], and not a second [Spec,DistP] position, for example, is that the verbal prefix meg, situated immediately in front of the verb in the absence of focus, is found in a postverbal position. Verbal prefixes belong to the class of verbal modifiers, and are thus glossed as ‘vm’ here.
3 The specifics of the interpretation of the constituent in [Spec,FocP], which are also reflected in the English translations, will be discussed below.
(3) a. topic position: valamely fiú/bizonyos fiúk ‘some boy(s)’, Péter, Péter és Mária
‘Peter and Maria’, a fiú(k) ‘the boy(s)’, hat fiú ‘six boys’, sok fiú ‘many boys’, a legtöbb fiú ‘most boys’
b. quantifier position: sok fiú ‘many boys’, minden fiú ‘every boy’, valamennyi fiú ‘each boy’, hat fiú is ‘even/as many as six boys’, legalább hat fiú ‘at least six boys’, több mint hat fiú ‘more than six boys’
According to the characterization provided by Szabolcsi (1997: 122), DPs in the topic position “contribute an individual to the interpretation of the sentence”, and the DPs in the quantifier position, denoting right monotone increasing, distributive quantifiers “con- tribute a set to the interpretation of the sentence”.
It was pointed out first by Szabolcsi (1981) that the constituents situated in the [Spec,FocP]
position, traditionally referred to as the focus position of the Hungarian sentence, are asso- ciated with an exhaustive interpretation. This means that whenever the person answering the wh-question in (4-a) knows that János not only missed the bus but also the train, her utterance of (4-b) is not only considered inappropriate but is downright false:
(4) a. Mit késett le János?
what.acc missed.3sg vm János
‘What did John miss?’
b. [FocP A buszt (késte le János).]
the bus.acc missed.3sg vm János
‘What János missed was the bus.’ or
‘It was the bus that János missed.’
Szabolcsi (1994) formalized this intuition (based on suggestions by Kenesei 1986) by postulating an operator responsible for the exhaustive/identificational reading, shown in (5). This means that the meaning of (6-a), with the DP két ember ‘two people’ in focus position, is to be represented as in (6-b):4
(5) Szabolcsi (1994: 181, ex. (22))
λzλP[z = ιx [P(x) & ∀y [P(y) → y ⊆ x]]]
(6) Szabolcsi (1994: 181, ex. (25)) a. [FocP Két ember fut.]
two person run.3sg
‘It is two people that run.’4
b. ∃g [man(g) & |g| = 2 & g = ιx[run(x) & ∀y [run(y) → y ⊆ x]]]
In plain English, (6-b) means that there is a plural individual in the denotation of man that has two atomic parts and is identical to the maximal individual that runs. The use of the ι-operator reflects the intuition that sentences with preverbal focus presuppose that there is a unique (possibly plural) individual that possesses the property characterized by the rest of the sentence, and assert that the latter is identical to the denotation of the constituent in focus position.5
4 Szabolcsi does not provide an English translation for this sentence. The translation given here is modeled after her translation of an analogous example.
5 An analogous proposal in a different framework is made by van Leusen & Kálmán (1993). The same obser- vation, namely, that the preverbal focus constituent (or an accented subconstituent thereof) identifies the unique holder of the property described by the rest of the sentence underlies the proposal defended in É.
Kiss (2006; 2009) about focus being an identificational predicate. For a detailed summary of the reasons why structural focus in Hungarian must be attributed an exhaustive interpretation see É. Kiss (2010b).
This observation is reflected in the practice of translating Hungarian sentences contain- ing a preverbal focus into English with the help of a cleft or pseudocleft construction, as in Szabolcsi (1994) and É. Kiss (1998; 2002), which will also be followed in this paper.
Although the above solution might give the impression that a declarative containing a preverbal focus in Hungarian is not a congruent answer to an ordinary wh-question, it reflects the truth-conditional meaning of the relevant construction better than an English declarative where the focus is marked prosodically. (Note that it is due to the obligatory exhaustive/identificational reading of the preverbal focus that DPs with bare numeral determiners in this position, like két ember ‘two people’ in (6-a), are interpreted as if the numeral were modified by exactly.)
The interpretation of Hungarian sentences containing a preverbal focus given above might appear analogous to the interpretation of sentences containing the exclusive particle csak ‘only’, as in (7):
(7) [FocP Csak két ember fut.]
only two person run.3sg
‘Only two persons run.’
Szabolcsi (1994) convincingly argues that the structures shown in (6-a) and (7) differ as to where the dividing line between presupposed and asserted content lies. (This can be proven by comparing negated versions of (6-a) and (7), which, crucially, are not synony- mous.) According to her proposal, (7) presupposes that two people run, and asserts that these two people are not part of a larger plural individual that runs.6
Given that the constituent in the preverbal focus position is associated with an exhaus- tive/identificational operator, it can enter into scope relations with other operators in the sentence.7 Exhaustive/identificational focus is c-commanded by and thus takes narrow scope with respect to preceding quantificational expressions, illustrated in (2) and (8):
(8) [TopPMari [DistP minden fiút [FocP a moziba hívott meg.]]]
Mari every boy.acc the movies.into invited.3sg vm
‘Every boy is such that it was to the movies that Mari invited him.’
As illustrated above, the focus position can host non-quantificational DPs, as in (4-b) and (8), as well as DPs with (modified) numeral determiners, as in (2) or (6-a).
On the assumption that scope is determined by c-command relations at overt structure, the relative scopes of the two preverbal operators in (9) and of the preverbal and postverbal operators in (10), where main stress falls on the sentence-initial constituents, have to correspond to their linear order, which is indeed the case:
(9) [DistP Minden képet [FocP Péter nézett meg.]]
every picture.acc Peter looked.3sg vm
‘Every picture is such that it was Peter who looked at it.’
(∀ > Exhaustive Focus)
6 Readers who find translations like the one in (4-b) or (6-a) clumsy can, however, substitute the cleft for an only-phrase for comprehensibility, since it will not lead to truth-conditional differences in the case of the examples discussed in this paper. Thus, an alternative translation for (4-b) would be the following: János only missed the bus.
7 The assumption that the constituents in the preverbal focus position of the Hungarian sentence have an exhaustive or identificational reading has recently been called into question by researchers on the basis of certain processing experiments, e.g. Onea & Beaver (2011), Kas & Lukács (2013), and Gerőcs et al. (2014).
However, we are not convinced that the experimental data reported on in these papers necessarily forces one to the conclusions drawn by the respective authors. It appears to us that they can also be accounted for by attributing special flexibility to the domain of alternatives activated by the constituent in focus position.
Experimental support for the latter approach is provided by É. Kiss & Zétényi (2017).
(10) [FocP Péter nézett meg minden képet.]
Peter looked.3sg vm every picture.acc
‘It was Peter who looked at every picture.’
(Exhaustive Focus > ∀)
Having reviewed some basic assumptions on the syntactic structure of the Hungarian sentence and the interpretation of constituents in the preverbal operator positions, in the next section we turn to the discussion of the specific claims of four theoretical studies regarding the scope properties of different kinds of postverbal quantifiers depending on their prosody. Sections 3 and 4 present the perception experiments we conducted in order to gain information about how speakers interpret Hungarian sentences containing post- verbal quantifiers. The theoretical implications are discussed in Section 5, and the paper ends with the conclusions in Section 6.
2 The effect of prosody on the scope of postverbal quantifiers: Data and theories
Hunyadi (1981) argued that stress on a postverbal universal DP can overwrite the pre- dictions concerning scopal relations that are made on the basis of c-command relations at overt syntax, forcing the constituent in question to take wide scope over preverbal exhaustive/identificational focus. Thus, in his judgment, the only reading of (11) is iden- tical to that of (9): ‘Every picture is such that it was Peter who looked at it.’ (In this and the following examples, stress on a postverbal constituent is marked by small capitals.) (11) [FocP Péter nézett meg minden képet.]
Peter looked.3sg vm every picture.acc
É. Kiss (1987; 1992; 2002; 2010a) extends Hunyadi’s predictions on the effect of stress to all types of postverbal distributive quantifiers. Regarding topical DPs in postverbal position, she claims that they are capable of taking inverse scope with respect to prever- bal quantifiers independently of whether they are stressed. É. Kiss (1987; 1992; 2002) accounts for these data by assuming that at Spell-Out, the postverbal stressed quantifi- cational expressions occupy the preverbal operator positions that are available for them (i.e. [Spec,TopP] or [Spec,DistP], respectively). At PF, they undergo stress-assignment in these positions, but after that, they are moved back to postverbal position by a stylistic postposing rule. A different approach is proposed by É. Kiss (2010a), which assumes that the stress of postverbal distributive, upward monotonic quantifiers indicates that they are right-adjoined to FocP and thus c-command the latter, deriving the wide scope reading on standard assumptions.
Hunyadi (1996; 1999; 2002) breaks with the view that the scope of operators in Hungarian is determined by c-command relations. In his theory, scope is derived from the interaction of stress and certain properties of operators, such as their place within an independently given operator hierarchy (Hunyadi 2002: 90).
Brody and Szabolcsi (2003) assume a hierarchical VP, where sequences of the operator projections RefP (corresponding to TopP in other frameworks, cf. (1) above), DistP and FocP are iterated. (This enables postverbal quantifiers to occur in any order, since adja- cent constituents may always belong to different scopal series.) The theory predicts that for a pair consisting of a preverbal and a postverbal quantifier an inverse scope reading is possible, provided the latter precedes the former in the following ranking of quantifi- cational expressions: topical indefinites, most-phrases > distributive quantifiers > counters (including focused number words). The authors claim that for speakers of one dialect “high stress” is a necessary condition of the wide scope of a postverbal quantifier.
Surányi (2002; 2004; 2006) proposes that distributive universals, increasing “ modified numeral indefinites”, and “increasing proportionals” like many N occupy their scope positions in Hungarian not as a result of Q-feature checking but as a result of quantifier raising. Quantifier raising can optionally be overt or covert, and does not depend on stress.
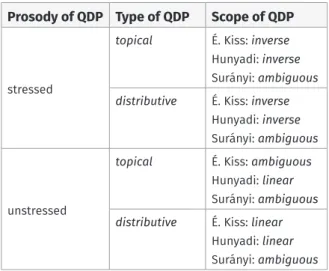
Here we cannot go into a detailed discussion of how exactly the theories mentioned above derive the wide scope readings of postverbal quantifiers for the cases they predict such readings to exist. We limit ourselves to presenting their different predictions regarding the relative scopes of pairs of operators in two configurations: i) a non- quantificational DP in preverbal focus position is followed by a stressed or unstressed postverbal quantificational DP, cf. Table 1, and ii) a DP containing a bare numeral determiner in preverbal focus position is followed by a stressed or unstressed postverbal quantificational DP, cf. Table 2.
The following two examples illustrate the structure of the sentences under discussion, for Table 1: Scope of a postverbal quantifier with respect to a non-quantificational DP in focus
position.
Prosody of QDP Type of QDP Scope of QDP
stressed
topical É. Kiss: inverse Hunyadi: inverse Surányi: ambiguous distributive É. Kiss: inverse
Hunyadi: inverse Surányi: ambiguous
unstressed
topical É. Kiss: ambiguous Hunyadi: linear Surányi: ambiguous distributive É. Kiss: linear
Hunyadi: linear Surányi: ambiguous
Table 2: Scope of a postverbal quantifier with respect to a DP with bare numeral determiner in focus position.
Prosody of QDP Type of QDP Scope of QDP
stressed
topical É. Kiss: inverse Hunyadi: ambiguous
Brody & and Szabolcsi: ambiguous Surányi: ambiguous
distributive É. Kiss: inverse Hunyadi: ambiguous
Brody & Szabolcsi: ambiguous Surányi: ambiguous
unstressed
topical É. Kiss: ambiguous Hunyadi: linear
Brody & Szabolcsi: linear/inverse Surányi: ambiguous
distributive É. Kiss: linear Hunyadi: linear
Brody & Szabolcsi: linear/ambiguous Surányi: ambiguous
the case where the postverbal quantifier is a universal one. With the non-quantificational expression Klára in the focus position, (12) represents configuration i) above, whereas (13), with the DP két lány ‘two girls’ in the focus position, illustrates configuration ii).
The two potential readings of (12)–(13), which differ as to the relative scopes of the exhaustive/identificational focus and the postverbal quantificational DP, are both shown in the translations. Linear scope (abbreviated as ‘LS’) refers to the configuration where the linearly first constituent (i.e. the one situated in the focus position) takes scope over the postverbal quantifier, where the former also c-commands the latter, and inverse scope (abbreviated as ‘IS’) to the one where the preverbal focus constituent takes narrow scope with respect to the quantifier.
(12) Klára próbált fel minden / minden ruhát.
Klára tried.3sg vm every every dress.acc
‘It was Klára who tried on every dress.’ – LS
‘Every dress is such that it was Klára who tried it on.’ – IS (13) Két lány próbált fel minden / minden ruhát.
two girl tried.3sg vm every every dress.acc
‘It was two girls who tried on every dress.’ – LS
‘Every dress is such that it was two girls that tried it on.’ – IS
In Tables 1 and 2, the top row lists properties of the postverbal quantiicational DP (abbre- viated as QDP), also referred to as quantifier in what follows, such as its prosody, its type and its scope. For brevity, we have only indicated the authors’ names in the tables with- out explicit reference to the publications, since the predictions of the individual authors concerning the scope relations between a preverbal focus and a postverbal quantifier do not change across their different publications. Since Brody & Szabolcsi do not make predictions for the case of non-quantificational expressions in the focus position, their suggestions are not included in Table 1.
As Tables 1 and 2 show, the four approaches make different predictions as to whether the availability of the inverse scope reading depends on the postverbal quantifier being stressed. Whereas the proposals by É. Kiss and Surányi do not differentiate between quantificational and non-quantificational DPs in the preverbal focus position, Hunyadi makes different predictions for them. As mentioned above, Brody & Szabolcsi only con- sider quantificational foci, and assume that speakers of two different dialects assign scope differently to postverbal unstressed quantifiers.
As the tables indicate, among the four approaches discussed here, É. Kiss and Hunyadi predict for the majority of the configurations that the prosody of the postverbal quan- tifier determines its scope with respect to an exhaustive/identificational focus. Brody
& Szabolcsi argue that stress only has an impact on scope for speakers of one dialect, whereas Surányi does not attribute any significance to it.8
Interestingly, all the theories assume that there is no distinction within the classes of the topical and distributive DPs themselves regarding the availability of the inverse scope reading in postverbal position. These theories do not discuss the impact of any other potential factors on scope, such as the grammatical or thematic roles of the relevant scope-taking expressions, for example. The next section describes the experiments we carried out to test the above predictions.
8 For a more detailed discussion about the implications of the theories discussed above, see Gyuris (2008) and Jackson (2008).
3 Experiments 1 and 2
The aim of the experiments reported on in this section was to systematically test the scope of postverbal QDPs with respect to exhaustive/identificational focus. Specifically, we wanted to find out whether i) inverse scope readings are possible for postverbal QDPs at all, and, if they are, ii) whether these readings arise as a result of the QDPs being stressed. We hypoth- esized, based on previous discussions in the literature, that the answer to both of these questions will be positive. We considered the possibility that the syntactic/thematic role of the postverbal quantificational expression or the type of constituent in the preverbal focus position will also make a difference regarding the availability of the relevant readings, and thus the experimental items were created in a manner that makes a comparison along these parameters to be possible, but we did not formulate specific hypotheses concerning them.
Experiments 1 and 2 were designed to elicit scope judgments using non-verbal forced- choice responses. They were identical except for minor adjustments, which were deemed necessary due to the fact that in Experiment 1 no evidence was found of an effect of pro- sodic stress on scope judgments. For the above reasons, we present these two experiments together.
3.1 Methods 3.1.1 Materials
Inspired by previous work, e.g. Hunyadi (2002), suggesting that rich discourse environ- ments may be crucial in allowing participants to make valid scope judgments, we pre- sented the critical sentences together with an introductory context that we considered ambiguous and unbiased as to the relative scopes of the operators in question.
An item consisted of a context description with a particular critical sentence frame. The critical QDP whose scope was being tested was always postverbal, and the other scope bearing element was a constituent in the preverbal focus position (thus, having an exhaus- tive/identificational reading).
The experimental items were of four types, to be referred to by the letters A, B, C, and D. They differed in the grammatical/thematic status of the critical QDP, as well as in the type of the phrase in the focus position within the critical sentence frame, as described in (14). Each type was represented by 16 items.
(14) A: QDP – object or theme; focus – DP with a numeral determiner B: QDP – subject (and agent); focus – DP with a numeral determiner C: QDP – object or theme; focus – non-quantificational DP
D: QDP – subject (and agent); focus – non-quantificational DP
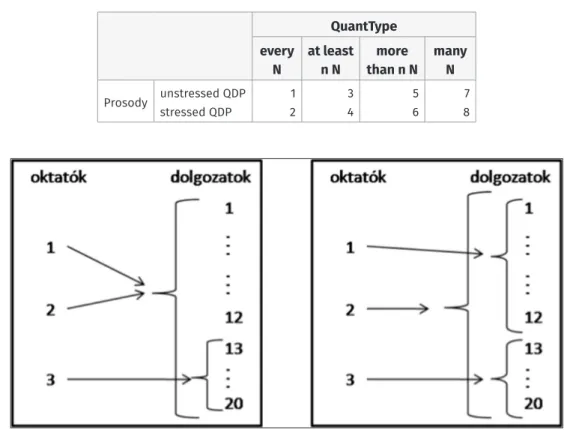
There were two experimental factors: the type of the QDP (QuantType) and Prosody. The first factor had four levels: the QDP could contain the determiners minden ‘every’, legalább n ‘at least n’, több mint n ‘more than n’ and sok ‘many’. All DPs containing the determin- ers above are right upward monotonic, and can appear in the preverbal quantifier posi- tion. Among them, DPs with minden ‘every’ can only occupy the quantifier position in the preverbal field; DPs with legalább ‘at least’ and több mint ‘more than’ can additionally appear in the focus position; and those with sok ‘many’ may occupy both the topic and the focus positions in addition. The second factor, Prosody, had two levels: the QDP could be stressed or unstressed. The combination of the two factors resulted in 8 conditions, numbered as shown in Table 3.
Each sentence frame containing a particular QDP was associated with a pair of diagrams intended to depict the two possible readings of the sentence (LS vs. IS), presented side-by-side.
The diagrams contained representations of individuals arranged in two columns, and arrows
that aimed to indicate which individuals the relation described by the verbs is assumed to hold between. In all diagrams, the first column corresponded to the subject noun phrase and the second column to the object/patient noun phrase. The side of the linear scope interpreta- tion was balanced: half of the items in each set are linear-left, and half are linear-right.
Below we illustrate one experimental item of type A, which consists of a context description, whose English translation is shown in (15), and the sentence frame filled in according to the requirements of the eight conditions in (16)–(19). The pair of dia- grams that were used to represent the two readings of the two prosodic variants of the critical sentence in (16) is shown in Figure 1. The two readings of the prosodic variants of the critical sentences in (17)–(19) were represented with identical pairs of diagrams, shown in Figure 2. In these examples, the diagram on the left corresponds to the linear scope reading of the respective sentence and the diagram on the right corresponds to the inverse scope reading. The English translations of oktatók and dolgozatok are professors and papers, respectively.
(15) This year the papers for the Student Research Competition were evaluated locally by a committee consisting of three professors. Since the members of the committee are not on good terms with each other, the other faculty members at the department were wondering about how they distributed the work among themselves. Fortunately, the reviewers wrote a detailed report, from which the following also became evident:
(16) Két oktató olvasott el minden / minden dolgozatot.
two professor read.3sg vm every every paper.acc
‘It was two professors who read every paper.’ – LS
‘Every paper is such that it was two professors who read it.’ – IS Table 3: List of conditions.
QuantType every
N at least
n N more
than n N many N Prosody unstressed QDP
stressed QDP
1 2
3 4
5 6
7 8
Figure 1: Diagram pair accompanying the two variants of (16).
(17) Két oktató olvasott el legalább / legalább hét dolgozatot.
two professor read.3sg vm at.least at.least seven paper.acc
‘It was two professors who read at least seven papers.’ – LS
‘At least seven papers are such that it was two professors who read them.’ – IS (18) Két oktató olvasott el több / több mint hat dolgozatot.
two professor read.3sg vm more more than six paper.acc
‘It was two professors who read more than six papers.’ – LS
‘More than six papers are such that it was two professors who read them.’ – IS (19) Két oktató olvasott el sok / sok dolgozatot.
two professor read.3sg vm many many aper.acc
‘It was two professors who read many papers.’ – LS
‘Many papers are such that it was two professors who read them.’ – IS
The next examples illustrate an item of type B, in Conditions 1 and 5 (without the intro- ductory context):
(20) Három képet választott ki minden látogató.
three picture.acc chose.3sg vm every visitor
‘It was three pictures that were chosen by every visitor.’ – LS
‘Every visitor is such that it was three pictures that she/he chose.’ – IS (21) Három képet választott ki több mint hat látogató.
three picture.acc chose.3sg vm more than six visitor
‘It was three pictures that were chosen by more than six visitors.’ – LS
‘More than six visitors are such that it was three pictures that they chose.’ – IS (12) above, repeated here as (22), illustrates an item of type C, in Conditions 1 and 2. (23) illustrates the same item in Condition 3:
(22) Klára próbált fel minden / minden ruhát.
Klára tried.3sg vm every every dress.acc
‘It was Klára who tried on every dress.’ – LS
‘Every dress is such that it was Klára who tried it on.’ – IS Figure 2: Diagram pair accompanying the variants of (17)–(19).
(23) Klára próbált fel legalább hét ruhát.
Klára tried.3sg vm at.least seven dress.acc
‘It was Klára who tried on at least seven dresses.’ – LS
‘At least seven dresses are such that it was Klára who tried them on.’ – IS
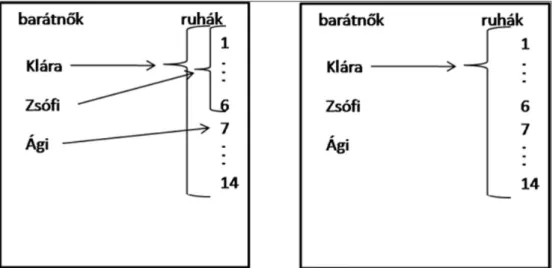
Figure 3 shows the pair of diagrams used in the trials where variants of (22) appear, where the labels lányok and ruhák stand for girlfriends and dresses, respectively.
As a comparison of Figures 1, 2 and 3 shows, there was a difference between the dia- grams associated with items of types A–B and of types C–D: in the case of the latter, the col- umn representing the set of individuals in the domain introduced by the focus constituent contained names of individuals, whereas in the case of the former the same column only contained numbers that were supposed to stand for different individuals in the domain.
Here we would like to call attention to one feature of the diagrams associated with items of types C–D, which could have led to unwanted effects: whenever there is a non- quantificational DP in focus position, the linear scope reading is true in both situa- tions represented by the diagrams. According to the linear scope reading of (22), Klára is identical to the individual that tried on every dress (which is compatible with the fact that others tried on some but not all dresses, too), thus this reading is true in both situations depicted in Figure 3. The inverse scope reading says that for every dress, Klára is identical to the individual that tried on that dress (thus being incompatible with a situation where any of the dresses were tried on by somebody other than Klára). This reading is only true in the situation represented by the second diagram in Figure 3. As a result, whereas the first diagram is only compatible with the linear scope reading, the second diagram is com- patible with both readings. This means that the choice of the second diagram among the two does not necessarily indicate that the speaker is opting for an inverse scope reading.
Thus, it is expected that the higher rate of choices of the second diagram does not mean that the participants prefer the inverse scope reading. Moreover, the second diagram in Figure 3 is the simpler one among the two,9 thus it is quite likely that when speakers con- template their choice, they first check whether the simpler diagram matches the reading they have in mind, and if it does, they do not study the other one. We come back to this issue in the course of discussing the results of the experiment.
9 We thank an anonymous reviewer for calling attention to this fact.
Figure 3: Diagram pair accompanying the two variants of (22).
The fillers used in the experiments consisted of a context description, an unambiguous sentence containing one or two QDPs, and two diagrams, presented side-by-side. The sentences appearing in the fillers realized three types of structure. In nine fillers, a proper name or adverbial in the topic position was followed by a verb and a postverbal QDP, illustrated in (24) below:
(24) Ede bácsi már járt két orvosnál is.
Ede uncle already visited.3sg two doctor.at too
‘Uncle Ede has already seen as many as two doctors.’
In nine other fillers sentences with one preverbal quantificational expression were used, as illustrated in (25):
(25) Kevés gyerek szereti a Doktor Bubót.
few child like.3sg the Doctor Bubo.acc
‘Few children like Doctor Bubo.’
The critical sentences in the third group of 18 fillers contained two preverbal quantifica- tional expressions: the first one was situated in the topic or quantifier positions, and the sec- ond one in another quantifier position or in the preverbal focus position, illustrated in (26):
(26) Hatan is két mobiltelefonnal rendelkeznek már.
six also two mobile.phone.with possess.3pl already
‘As many as six people already possess two mobile phones.’
For fillers, there was a correct and an incorrect diagram choice, and this was also balanced left-right, though fixed for each filler.10
Eight presentation lists were created according to a latin square design, eight items per condition. Each list consisted of 100 trials, 64 of which were experimental trials and 36 fillers.
Order was a fixed pseudo-random order, such that critical quantifiers were not repeated next to each other, conditions per set were divided evenly between the first half and second half of the experiment, and diagram order was not repeated more than three times in a row.
Four fillers were used as practice items, and the remaining fillers were spread through- out the experiment pseudo-randomly.
3.1.2 Procedure
In Experiments 1 and 2, participants were tested individually, with the help of a laptop computer and headphones. In Experiment 1, the procedure was the following. First, the three-sentence introductory text was displayed on the screen. Participants were asked to press a button after they had read the text, and then were presented with an experimental item or filler aurally. Next, a screen with the two diagrams appeared. Participants were asked to choose the diagram that corresponded better to the meaning of the critical or filler sentence in their opinion, by pressing the appropriate button on the keyboard. On the next screen, they were asked to provide ratings (between “1” and “7”, the latter being the best) as to their confidence in their choice. The intent of the confidence ratings was to help confirm that participants were not confused by the diagrams and simply guessing.
The experiments were put together using the software package DMDX (Forster & Forster 2003), which controlled stimulus presentation and recorded responses.
10 The full list of the original Hungarian experimental items and fillers, together with their English transla- tions, can be found in a supplementary file referenced in Section 6.
The procedure in Experiment 2 differed in one respect from the one described above.
In this case, participants were asked to listen to the test sentences twice, both before and after seeing the diagrams (in case they were merely “forgetting” how the critical sen- tence was pronounced). As mentioned above, phonological stress was exaggerated by the recorded speaker in Experiment 2, to rule out the possibility that the stress manipulation in Experiment 1 was simply too subtle to be noticed.
3.1.3 Participants
For the two experiments, participants were recruited from various universities in Budapest (43 and 33 persons, mean ages: 23.6 and 24.3, respectively). They were all native speakers of Hungarian, and had received no previous training in linguistics. They received instruc- tions on paper, and then were tested individually. Testing took approximately 50 minutes, and participants were paid 2500 HUF. Detailed instructions were given at the beginning of the protocol, and participants were allowed to ask questions following the practice items.
3.1.4 Results
The results of the two experiments turned out to be interesting in several ways. First, they contradict the view according to which stress has an effect on the scope of postverbal quantifiers, and second, they indicate that scope judgments might be influenced by other grammatical features whose effects have not yet been investigated for Hungarian.
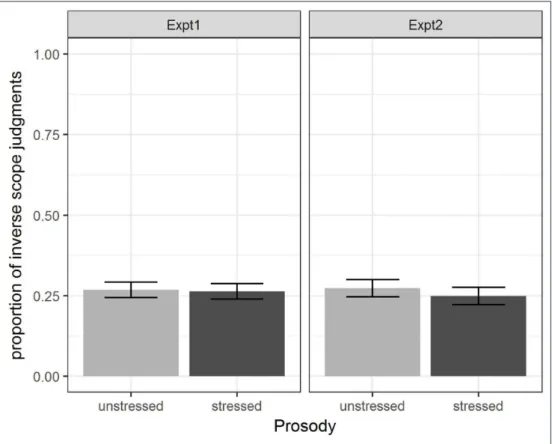
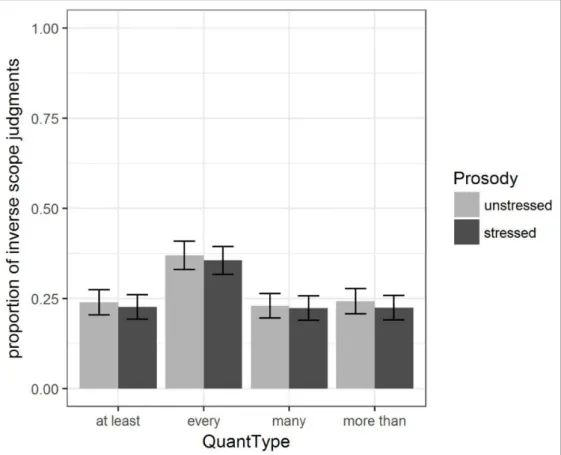
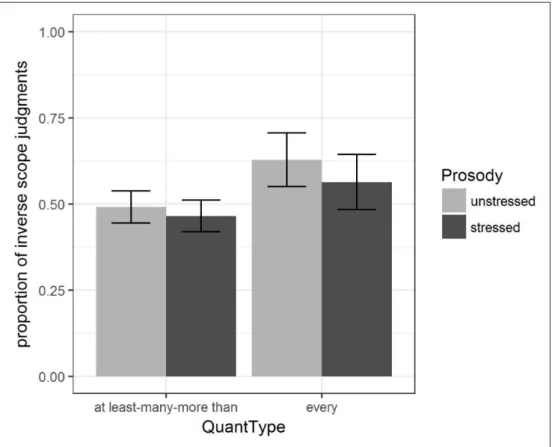
Figure 4 shows the overall proportion of inverse scope judgments across the two experi- ments. For both stressed and unstressed postverbal quantifiers, inverse scope judgments were given roughly 25 per cent of the time. This is in stark contrast with those reports in the literature that consider inverse scope judgments to arise exactly in those cases where the postverbal quantifier is stressed. As is also evident from Figure 4, the different pro- sodic realizations of the stimuli in Experiment 2 had virtually no impact on the results.
Figure 4: Effect of prosody in Experiments 1 and 2.
More interestingly, as Figure 5 indicates, there were some differences in scope judg- ments across the different postverbal QDPs: those containing the universal determiner minden ‘every’ received more inverse scope judgments than the others. However, the lack of effect of prosody on scope appears to hold across all of the quantifiers inves- tigated. Finally, Figure 6 shows that these patterns are similar across Experiments 1 and 2.
Figure 5: Effects of prosody and quantifier, collapsing Experiments 1 and 2.
Figure 6: Effects of prosody and quantifier, split across experiments.
The overall accuracy rate of fillers was 95% in Experiment 1 and 97% in Experiment 2.
Thus, there were no concerns that response patterns may have been a result of partici- pants simply not paying attention, or their inability to decipher the diagram stimuli.
3.1.5 Statistical analysis
We analyzed these results statistically with logistic mixed-effects (Gelman & Hill 2007;
Jaeger 2008), using the lme4 package in the statistical software platform R (Bates et al.
2014; R Development Core Team 2011). We fit several models, corresponding to differ- ent sets of predictors, predicting the binary response of scope judgment (i.e. 0 = linear scope, 1= inverse scope). The most striking result here is a null result, demonstrating no effect of prosody. However, p-values obtained from standard null-hypothesis significance testing can only inform when a null hypothesis should be rejected, and cannot assess the degree of evidence for a null effect. That is, especially since these results run counter to strong claims by certain authors in the literature, it is not sufficient to merely demonstrate
“non-significance” of the effect of prosody. Therefore, we carried out an Akaike weight analysis (see Burnham and Anderson 2002 for a comprehensive review, and Wagenmakers and Farrell 2004 for a brief, accessible tutorial), using the AICcmodavg package for R (Mazerolle 2015). In this type of analysis, model comparisons are made on the basis of the (corrected) Akaike Information Criterion (AICc), a commonly-used model-fit statistic.
All candidate models are compared at once, and Akaike weights are computed, which represent the relative strength of evidence for each model as compared to the set of mod- els, and which sum to 1 over the set of candidate models. The ratio of the Akaike weights between different models can be interpreted as relative strength of evidence.
In logistic mixed-effects models, random effects are specified in order to capture the hierarchical (e.g. repeated-measures) nature of the data. Following the recommendations of Barr et al. (2013), we fit random intercepts for subjects and items, but also the “maxi- mal” random slopes for each model. That is, for any within-subject factor, we fit a random slope that allowed the effect to vary by subject, and the same for items. This is arguably the most appropriate way to model standard assumptions about possible between-item and between-subject variation, and the best way to generalize beyond the current set of subjects and items.
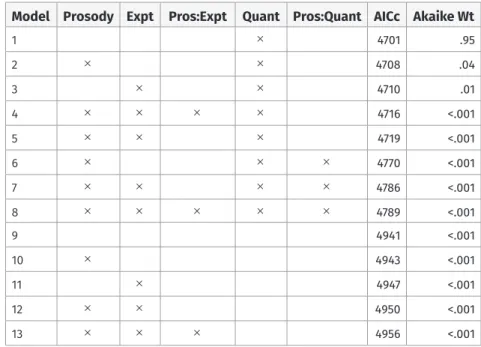
The first set of model comparison results is summarized in Table 4. Each row corre- sponds to a fit model, and marks indicate which factors and interactions were included in that model. The models are given in order from best (top) to worst (bottom), and the corresponding AICc values and Akaike weights are given in the rightmost columns.
The results in Table 4 very clearly rank the model with only QuantType as a factor (Model 1 in the table) as the best model. The next best model has QuantType and Prosody as predictors (without the interaction), but the ratio of Akaike weights between these models is 26-to-1 in favor of the model without Prosody. This indicates that not only is there a lack of evidence for a robust effect of prosody on scope judgments, there is strong evidence against an effect of prosody, such that among the factors investigated here (including prosody and its interactions with quantifier and experiment), a model with only QuantType as an explanatory factor is the far superior model.
For completeness, we also provide a coefficient table for Model 6 in Table 5, which is the model including the effects of Prosody, QuantType, and their interaction. Estimates, standard errors, and p-values are provided for each effect in the model, and on the right side of the table, the standard deviations are provided for the random effects in the model.
Note that these random effect standard deviations are on the same scale as the effect estimates, thus giving a sense of how much variability was observed in the effects across
items and subjects. The estimates themselves indicate the size of the effect in (log-odds) probability of an inverse scope judgment due to that factor, such that positive coefficients mean a greater probability of inverse scope judgments. Note also that because QuantType is a four-level factor, it must be dummy-coded into three effect coefficients. In the model represented in Table 5, legalább ‘at least’ is used as the “reference” level, and the coef- ficients represent how the other quantifiers differ from this one. Table 5 confirms what is shown in the graphs above, that inverse scope judgments are significantly more likely for the universal quantifiers, but there is no evidence of effects of prosody.
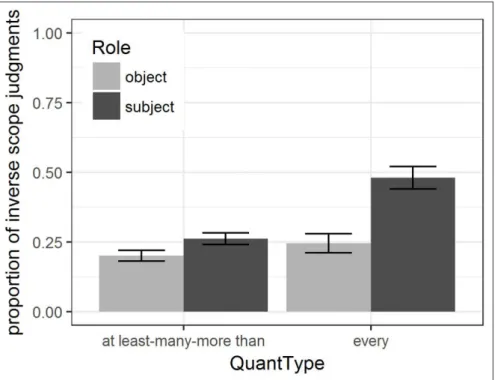
In contrast to this pattern of null effects for prosody, we found consistent effects of both the grammatical/thematic role of the postverbal quantifier and the type of preverbal operator, such that postverbal subjects (agents) took inverse scope more readily than objects/themes, illustrated in Figure 7, and postverbal quantifiers took inverse scope more easily over a non-quantificational focus than over focused number phrases, shown in Figure 8.
We conducted a similar analysis for these factors as before, applying the Akaike weight anal- ysis for a series of logistic mixed-effects models. For these models, we included QuantType as a factor, but in order to simplify the models, we simplified the QuantType factor to a binary Table 4: Model comparisons including Prosody for Experiments 1 and 2.
Model Prosody Expt Pros:Expt Quant Pros:Quant AICc Akaike Wt
1 × 4701 .95
2 × × 4708 .04
3 × × 4710 .01
4 × × × × 4716 <.001
5 × × × 4719 <.001
6 × × × 4770 <.001
7 × × × × 4786 <.001
8 × × × × × 4789 <.001
9 4941 <.001
10 × 4943 <.001
11 × 4947 <.001
12 × × 4950 <.001
13 × × × 4956 <.001
Table 5: Model coefficients and random effects for Model 6 from Table 4.
Coefficients Random effect std devs Effect Estimate std err p-value by-Item by-Subject
(intercept) –1.57 0.22 <.01* 0.88 1.12
Prosody (stressed) 0.07 0.21 .74 0.65 0.50
QuantType (every) 0.76 0.26 <.01 * .93 1.35
QuantType (many) –0.15 0.24 .55 0.97 0.66
QuantType (more than) –0.02 0.21 .94 0.55 0.53
Pros × Q (every) –0.20 0.27 .45 0.75 0.44
Pros × Q (many) –0.34 0.35 .33 1.26 1.13
Pros × Q (more than) –0.02 0.28 .95 0.56 0.77
factor, since in the results above, the effect of QuantType reduced to a difference between minden ‘every’ and the others. In order to confirm that this simplification was justified, we carried out a larger set of model comparisons, and all of the models that reduced QuantType to a binary variable (minden ‘every’ vs. the others) were superior to models which kept them all separate. For reasons of space, we do not give the full details here, but the Akaike weight evidence ratio was well over 1000-to-1 for the binary-factor models, indicating very clear results. Therefore, in the following analyses we collapse the QuantType factor into a binary factor. Additionally, since no effects of Experiment or Prosody were observed above, we do Figure 7: Effect of grammatical/thematic role.
Figure 8: Effect of focus constituent type.
not examine those factors here. The table of models is given in Table 6, along with the cor- responding AICc values and Akaike weights. Since our items were constructed such that all grammatical subjects were also agents, we simply term this factor “Role.”
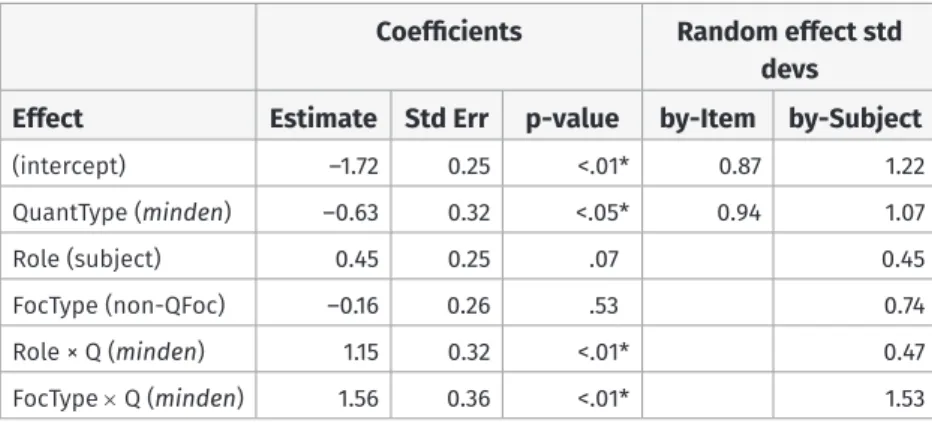
The results in Table 6 suggest that Role and FocType both play a role in affecting scope judgments, and furthermore that there is some interaction between these effects and the QuantType. The model coefficient table for the best model (Model 1 in Table 6) is given in Table 7. The statistical results confirm what is apparent in Figures 7 and 8, namely that there are clear effects of Role and FocType when the determiner of the critical postverbal QDP is minden ‘every,’ but with the other quantifiers, the effect is smaller for Role and not apparent at all for FocType.
Table 6: Model comparisons including Role and FocTypefor Experiments 1 and 2.
Model Q Role Q:Role FocType Q:FocType Role:FocType Q:Role:FocType AICc Akaike Wt
1 × × × × × 4605 .67
2 × × × × 4607 .27
3 × × × × × 4610 .05
4 × × × × × × 4613 .01
5 × × × × × × × 4624 <.001
6 × × × 4633 <.001
7 × × × × 4637 <.001
8 × × × 4637 <.001
9 × × × × 4639 <.001
10 × × × × × 4640 <.001
11 × × 4664 <.001
12 × × × 4681 <.001
13 × × 4683 <.001
14 × 4693 <.001
15 × × 4896 <.001
16 × × × 4897 <.001
17 × 4921 <.001
18 × 4930 <.001
19 4941 <.001
Table 7: Model coefficients and random effects for Model 1 from Table 6.
Coefficients Random effect std devs Effect Estimate Std Err p-value by-Item by-Subject
(intercept) –1.72 0.25 <.01 * 0.87 1.22
QuantType (minden) –0.63 0.32 <.05 * 0.94 1.07
Role (subject) 0.45 0.25 .07 0.45
FocType (non-QFoc) –0.16 0.26 .53 0.74
Role × Q (minden) 1.15 0.32 <.01 * 0.47
FocType × Q (minden) 1.56 0.36 <.01 * 1.53
3.2 Discussion
The results of the first two experiments can be summarized as follows. First, there appears to be no effect of prosody on scope judgments, even taking into account the exaggerated prosodic manipulations in Experiment 2. The results of the Akaike weight analysis indicate that this is not merely a “failure to reject” the null hypothesis, but rather that there is strong evidence for a null effect of prosody, at least in the context of this experimental paradigm.
Second, there is an overall bias towards linear scope interpretation, since inverse scope interpretations were chosen in much less than 50% of the cases. The fact that roughly a quarter of the responses indicated an inverse scope reading, even in the canonical struc- tures where the postverbal quantifier is not stressed, appears problematic for the theories that postulate lack of ambiguity for a given prosodic realisation, e.g. those by É. Kiss and Hunyadi. The data are compatible with approaches that consider postverbal quantifica- tional expressions to be scopally ambiguous with respect to preverbal focus, such as the ones proposed by Brody & Szabolcsi and by Surányi.
Third, universal DPs containing the determiner minden ‘every’ received many more inverse scope judgments than the other QDPs containing the determiners legalább n ‘at least n,’ több mint n ‘more than n,’ and sok ‘many.’ We discuss this further when we turn to certain methodological issues below. However, the null effect of prosody appeared to be the same across all quantifiers.
Finally, we observed effects of the Role of the postverbal QDP (subject/agent vs.
object/theme) and the type of the focus constituent (non-quantificational DP vs. DP with a numeral determiner). However, these effects appeared to differ among the different postverbal QDPs. For DPs containing minden ‘every,’ there were robust effects: inverse scope readings were much more frequent when the postverbal DP was a subject/agent, and when the focus constituent was a non-quantificational DP (proper name). However, the effect of Role appeared to be much milder for the other quantifiers, and the effect of FocType appeared not to obtain for the other quantifiers at all.
While the experimental paradigm was based on previous work using these kinds of line- drawings to represent scope judgments (Gillen 1991; Jackson & Lewis 2005; Bott & Radó 2007), the technique is still somewhat novel, especially with such complex judgments as those in these experiments. Thus we raise several potential issues that might explain some of the results as methodological artifacts, and address them in turn.
First, there is the question of why universal DPs containing minden ‘every’ appear to behave differently. It seems that the QuantType effect in particular sentence frames can be accounted for in terms of the structure of the associated diagrams. As discussed in Section 3.1.1, in the case of sentence-frames of type C–D, where a non-quantificational DP occupies the focus position, the diagram that is supposed to represent the inverse scope reading (e.g. the second one in Figure 3) is actually compatible with both of the readings.
Thus, the choice of this diagram, which is the simpler one among the two, in addition, is compatible with the speaker’s preference for a linear scope reading. These considerations suggest that the effect of FocType, which was only discernible in the case of DPs with minden ‘every’ is due to the particular methodology.
Second, with respect to the effect of Role, the finding that postverbal subjects take wide scope more easily over preverbal objects might also plausibly be due to the design of the diagrams: the entities in the set referred to by the subject DP were always on the left, with arrows pointing towards the entities referred to by the object/theme on the right. While this would not necessarily induce a bias, it is plausible that participants have mentally rehearsed the critical sentences in a way that matched the visual layout, which could lead to a bias. It is, however, unclear to us why such a bias would have a greater effect on universal DPs than on the others.
An anonymous reviewer for the paper notes, however, that since it is “intuitively inher- ently easier to judge that a predicate holds of a full set of items than that it holds for a subset of it” the pictures associated with the sentences containing universal DPs were easier to judge.11 We believe that these observations might reasonably account for why the effect of Role differs across the various quantifiers in the two experiments. The above considerations suggest that the effects of FocType and Role that were found in the course of the statistical analysis for QDPs with minden ‘every’ can be accounted for in terms of extra-grammatical (processing) and methodological factors.12
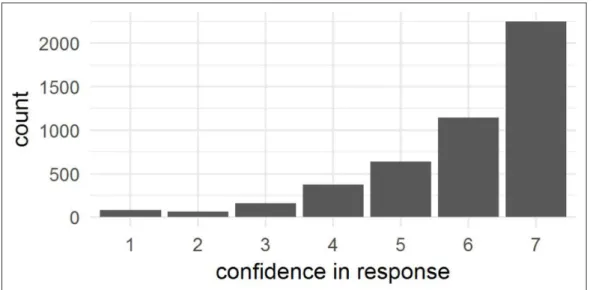
More generally, one might question the complexity of the methodology in effectively elicit- ing scope judgments. That is, one concern is that making judgments on complex line draw- ings like the ones used in these experiments is too difficult, and thus the results do not really reflect speakers’ intuitions. Although we cannot explicitly contradict this suggestion, there are some indications against it. First, the very low error rate with filler sentences, as discussed above, indicates that participants were closely attending to the stimuli and could interpret the diagrams appropriately. Second, participants provided extremely high confidence ratings, as shown in Figure 9, which might not have been the case if the task had been confusing.
Nonetheless, given the unexpected patterns of results, both the null effect of prosody as well as the novel effects of Role and FocType, we carried out a third experiment using the same materials, but in a different task, to see whether the same patterns would obtain.
4 Experiment 3
The third experiment was designed to avoid potential difficulties arising from the use of diagrams to represent scope; it was based instead on a simple metalinguistic judgment task.
4.1 Methods 4.1.1 Materials
In Experiment 3, the same experimental items and fillers were used as in Experiments 1 and 2, including the 3-sentence texts setting up the context. The audio files were identical to those used in Experiment 1. For each item in each condition, we created an unambiguous
11 This suggestion is corroborated by the fact that confidence ratings are in general significantly higher for sentences containing minden- ‘every’ phrases than for the others, and that they drop slightly (by about half a point) in the case of inverse scope judgments for quantificational expressions other than those containing minden ‘every’.
12 We thank an anonymous reviewer for suggestions regarding possible interpretations of the relevant data.
Figure 9: Confidence values in Experiments 1 and 2.
paraphrase of the inverse scope reading that consisted of two preverbal QDPs, the scope of which is assumed by all theoretical accounts in the literature to be unambiguous. (27-a)–
(27-d) illustrate the unambiguous13 paraphrases provided for (16)–(19) above:
(27) a. Minden dolgozatot két oktató olvasott el.
every paper.acc two professor read.3sg vm
‘Every paper was read by two professors.’
b. Legalább hét olyan dolgozat volt, amit két oktató olvasott el.
at.least sevensuch paper was that.acc two professor read.3sg vm
‘There were at least seven papers that were read by two professors.’
c. Több mint hat olyan dolgozat volt,amit két oktató olvasott el.
More than six such paper was that.acc two professor read.3sg vm
‘There were more than six papers that were read by two professors.’
d. Sok olyan dolgozat volt, amit két oktató olvasott el.
many such paper was that.acc two professor read.3sg vm
‘There were many papers that were read by two professors.’
In response to concerns about participants being fatigued by the length of Experiments 1 and 2, we took the same experimental lists that we used in the previous experiments, but only used the first half of each. This resulted in having 32 experimental trials (four in each condition) and 16 fillers in each list.
4.1.2 Procedure
The participants were tested again individually with the help of a computer. First, the three- sentence context-description appeared on the screen. Next, the critical sentence was pre- sented aurally. After this, the written paraphrase of the inverse scope reading appeared on the screen. On the next screen, the participants were asked to indicate on a five-point scale how well they thought the critical sentence matched the meaning of the (unambiguous) sentence presented in writing. (“1” stood for minimal and “5” for a great deal of similarity.) 4.1.3 Participants
Thirty-three participants (mean age: 27.2) without previous training in linguistics took part in the experiment, recruited again from universities in Budapest. They received 1500 HUF for their participation.
4.1.4 Results and statistical analysis
In order to simplify the discussion and analysis of results, we dichotomized the ratings such that responses of “1” or “2” were coded as “linear scope” judgments and responses of “4” or “5” as “inverse scope” judgments. Ratings of “3” were taken to be ambiguous or undecided, and were excluded from the statistical analysis. This decision is justified in
13 A reviewer points out a potential problem with the paraphrases used for sentences containing universal DPs, illustrated in (27-a). As noted first in Szabolcsi (1981), and discussed by É. Kiss (2002) and Gyuris (2009), among others, if universal quantifiers preceding the focus or the negative particle are pronounced with a specific, (fall)-rise (“contrastive topic”) intonation, they get a narrow scope reading with respect to these operators. The reviewer argues that since the paraphrases were presented in writing, the experiment did not control for their pronunciation, and thus it is possible that the participants assigned them a reading where the universal quantifier actually took narrow scope. Although we were aware of this problem, we still opted for presenting the paraphrases containing the universal DP with the help of the simpler structure illustrated in (27-a), instead of the more complex one shown in (27-b)–(27-d) because we assumed, follow- ing the literature, that in the absence of contextual support for the contrastive topic interpretation, speakers will have no reason to believe that the paraphrases were intended to be pronounced with the (fall-)rise.
part by the fact that the distributions of ratings peaked at “1” and “5”, indicating that the judgments were essentially binary judgments with some uncertainty superimposed. The patterns shown in the dichotomized results are the same as revealed by the full ordinal scale, and are easier to read and interpret. Therefore in the statistical analysis, we report the results of logistic mixed-effects models, comparable to the models fit for Experiments 1 and 2. We also fit ordinal mixed-effects models (using the ordinal package, Christensen 2015), which showed the same pattern of results as the logistic models reported below.
But again, because the dichotomized results are easier to follow and interpret, we present only those here. Likewise, we focus on the binary QuantType variable, comparing the pat- tern of results for DPs with minden ‘every’ vs. the rest of the quantificational expressions, following the approach taken in the case of Experiments 1 and 2.
First we consider the effect of prosody on scope readings. Figure 10 shows the pattern of judgments, broken down by quantifier. If prosody had the effect reported in É. Kiss’s and Hunyadi’s works, the heights of the darker bars should be close to 1.00 (“inverse”
judgment), and the heights of the lighter bars should be close to 0.00 (“linear” judgment).
As Figure 10 shows, still no effect of prosody is observed. The only (non-significant) numerical trend is for minden ‘every’, in the opposite direction than expected.
The results of the model comparison analysis are given in Table 8, and the model coefficients for the full prosody by quantifier interaction (Model 5 in Table 8) in Table 9.
Note that Experiment is no longer a factor because we are examining only the results of Experiment 3. These results unambiguously replicate the pattern of results from the first two experiments. Notably, the overall rates of inverse scope judgments are much higher than in Experiments 1 and 2. As in Experiments 1 and 2, inverse judgments are more acceptable with postverbal DPs containing the determiner minden ‘every’, though the effect is milder, and just shy of p < .05 significance (see Table 9). And just as in the
Figure 10: Effect of prosody in Experiment 3.