Adatok gyűjtésének és értékelésének módszerei
Domokos, Endre
Csom, Veronika
Adatok gyűjtésének és értékelésének módszerei
Domokos, Endre Csom, Veronika
Tartalom
1. Jelmagyarázat és rövidítésjegyzék ... 1
2. Bevezetés ... 2
3. Nagy mennyiségű adatok feldolgozásának statisztikai alapjai ... 3
1. Alapfogalmak ... 3
1.1. Sokaság ... 3
1.2. Ismérv (attribútum) ... 4
1.3. Mérés ... 4
1.4. Statisztikai sor ... 5
2. Viszonyszámok ... 6
2.1. Dinamikus viszonyszám ... 6
2.2. Megoszlási viszonyszám ... 7
2.3. Intenzitási viszonyszám ... 7
2.4. Számításértelmezési feladat ... 8
3. Eloszlás-elemzés ... 8
3.1. Gyakorisági sorok ... 9
3.1.1. Osztályközös gyakoriság számításának lépései ... 10
3.1.2. Kumulálás (halmozott összeadás) ... 12
3.1.3. Értékösszegsor ... 15
3.2. Kvantilisek ... 16
3.3. Középérték ... 18
3.3.1. Medián (Me) ... 18
3.3.2. Módusz (Mo) ... 20
4. Statisztikai mutatók ... 24
4.1. Terjedelem ... 24
4.1.1. (Rendes) terjedelem ... 25
4.1.2. Interkvantilis (nyesett) terjedelem ... 26
4.2. Statisztikai momentumok ... 27
4.2.1. Szóródás (σ) ... 27
4.2.2. Relatív szóródás ... 29
4.2.3. Általános (abszolút) különbség ... 31
4.2.4. Momentum ... 33
4. Adatbázisok fellelhetősége az interneten ... 36
1. OKIR (Országos Környezetvédelmi Információs Rendszer) ... 36
2. Zöldhatóságok ... 38
3. OLM (Országos Légszennyezettségi Mérőhálózat) ... 39
4. Központi Statisztikai Hivatal ... 41
5. Vízügyi adatbank ... 41
6. OMSZ (Országos Meteorológiai Szolgálat) ... 41
7. River Monitoring ... 42
8. Integrált Drávai Monitoring ... 44
9. Nemzetközi kitekintés ... 44
5. Adatbázisok használatának jogi háttere ... 47
1. örnyezetvédelmi vonatkozású adatok szabályozása ... 47
2. A környezetvédelmi vonatkozású közérdekű adatok megismerésének korlátai ... 48
3. Az elektronikus információszabadság ... 48
6. Adatminőségi osztályok (adatok pontossága, adatok megbízhatósága) ... 50
7. Adatok előkészítése kiértékelésre (szűrés, normalizálás, u-próba, t-próba) ... 53
1. Szűrés ... 53
2. Hibaszámítási adatok ... 54
3. Student-féle egymintás t-próba ... 55
4. Gyakorisági eloszlás ... 56
5. Szórás, konfidencia intervallum ... 60
6. Kiugró értékek ellenőrzése (normalizálás) ... 64
8. Környezetvédelem során mért adatok különleges feldolgozása ... 67
1. A mérőeszközök megválasztása ... 67
2. Megfelelő mérési körülmények biztosítása ... 67
9. Adattárolási módok számítógépes feldolgozás során ... 69
1. Osztott adatbázisok ... 69
1.1. GRID rendszerek ... 69
2. Adatbiztonság ... 69
10. Adatábrázolási technikák, mérési hibák vizuális ábrázolása, görbe és trendvonal illesztése adatsorokra ... 73
1. Adatábrázolási technikák ... 73
1.1. Poláris diagram – sugár diagram ... 73
1.2. Pontdiagram és a vonaldiagram ... 74
1.3. Területdiagram ... 76
1.4. Kör- és perecdiagram ... 76
1.5. Oszlopdiagram ... 78
11. Nagy mennyiségű adatok kezelése és összehasonlítási módszerei ... 80
1. Lorenz görbe és a Gini együttható ... 80
12. Adattrendek használatának lehetőségei a fenntartható fejlődés tervezésének támogatására ... 88
1. Várpalota térségének levegőminősége és változása az elmúlt évtizedekben ... 88
1.1. NO2 koncentrációk változása ... 88
1.2. SO2 koncentrációk változása ... 89
1.3. Ülepedő por koncentrációk változása ... 90
1.4. Ammónia koncentrációk változása ... 90
2. Várpalota és térsége levegőminőségének jellemzése ... 91
13. Kérdések ... 92
14. Ajánlott irodalom ... 96
15. Segédtáblázatok ... 97
Az ábrák listája
3.1. Statisztikai sorok fajtái (vastagon kiemelve a leggyakoribb előfordulás) ... 5
3.2. Adatok rendezésének gombja MS Excelben ... 11
3.3. Adatok rendezésének gombja LibreOfficeban ... 11
3.4. A kumulált gyakoriság ábrázolása ... 14
3.5. Módusz kiemelése a sokaságból ... 22
3.6. Vizsgált adatsor jellemzői számegyenesen ... 26
3.7. Vizsgált adatsor jellemzői ... 26
3.8. A standard deviancia ábrázolása ... 31
4.1. Veszprém levegőt terhelő pontforrásai ... 37
4.2. Volán telephely éves szennyezőanyag kibocsátása (kg) ... 38
4.3. Veszprém – Kádár utcai mérőkonténer adatlapja ... 40
4.4. Vízügyi adatbank kezdőlapja ... 41
4.5. Vízügyi adatbank lekérdező felülete ... 41
4.6. Met.hu legfrissebb mért meteorológiai adatai ... 42
4.7. UV index várható napi menete ... 42
4.8. Tisza-vízgyűjtő monitoring rendszer ... 42
4.9. Európai Statisztikai Hivatal témakörei ... 45
6.1. A kezdő és a pontosan célzó „találatai” ... 50
6.2. A kezdő és a pontosan célzó „találatai”- szóródási görbe ... 50
6.3. Szisztematikus hiba – torzítás illusztrációja ... 51
6.4. Véletlen hiba – szórás/pontosság illusztrációja ... 51
7.1. Probléma az adatbázisban ... 53
7.2. ÉDT-KTVF adatbázisából részlet ... 53
7.3. SO2 koncentráció változása a mintahónapban ... 57
7.4. SO2 koncentráció változása a mintahónapban ... 58
7.5. SO2 tartalom relatív gyakorisági eloszlása ... 59
7.6. SO2 összegzett relatív gyakorisági eloszlása ... 60
7.7. Párhuzamos mérési helyszínek - Veszprém ... 60
7.8. PM10 - párhuzamos mérések eredményei ábrázolva ... 62
7.9. PM2,5 - párhuzamos mérések eredményei ábrázolva ... 63
7.10. A standard normáleloszlás sűrűségfüggvénye ... 65
8.1. Nagytérfogat-áramú pormintavevő, és a szűrőpapíron felfogott porminta ... 67
9.1. A hardver, szoftver és az adat árainak egymáshoz viszonyított aránya a számítástechnika korai korszakában és ma ... 69
9.2. Klasszikus – adatbiztonságra kiépített – adatbázis hardver környezet ... 70
9.3. Osztott – adatbiztonságra kiépített – adatbázis hardver környezet ... 70
9.4. Korszerű – adatbiztonságra kiépített – adatbázis hardver környezet ... 71
10.1. Összes só-tartalom csillagábra ... 74
10.2. Példaként bemutatott 9.3 diagramjának adatsora – részlet a 24 órás mérés eredményeiből .... 74
10.3. Hőmérséklet – UVA sugárzás pont (felső)- illetve vonaldiagramon (alsó) ... 75
10.4. 2010. október 8-9. – Devecseri mérésünk PM10 koncentráció értékei és a határérték ... 76
10.5. Földhasználat művelési ágak szerint (2010) – KSH adatai szerint ... 76
10.6. Földhasználat művelési ágak szerint – KSH adatai szerint ... 77
10.7. Földhasználat művelési ágak szerint (2010-külső perec, 2008-belső perec) – KSH adatai szerint 77 10.8. Balaton Pláza – egyidejűleg mért PM10/PM2,5 szálló por frakciók koncentráció értékei ... 78
10.9. Balaton Pláza – PM2,5 frakció aránya a PM10 koncentrációban ... 79
10.10. Diagram rajzolása ... 79
11.1. Szennyvízkibocsátók az ipari parkban. ... 81
11.2. Osztályközök ... 83
11.3. Lorenz görbe. ... 85
12.1. Várpalota, Inota, Pétfürdő – NO2 koncentrációk éves átlagértékeinek változása 1979-2008 között 88 12.2. Várpalota, Pétfürdő – SO2 koncentrációk éves átlagértékeinek változása 1979-2008 között .. 89
12.3. Várpalota, Inota, Pétfürdő – Ülepedő por koncentrációk éves átlagértékeinek változása 1979-2008 között ... 90
12.4. Pétfürdő – Ammónia koncentrációk éves átlagértékeinek változása 1979-2006 között ... 90 13.1. Jelen és jövő ... 92
A táblázatok listája
3.1. Megoszlási viszonyszám számítása táblázatkezelő rendszerben ... 7
3.2. Szmogriadók száma 2008-2011 között ... 8
3.3. Osztályközös gyakoriság alaptáblázata ... 9
3.4. Veszprémi légszennyezettség-mérő állomás órás NOx töménység-mérési adatai ... 10
3.5. Osztályköz táblázat egyenletes osztályköz esetén ... 12
3.6. Kumulált gyakoriság ... 13
3.7. Felfelé kumulált gyakoriság számítása ... 13
3.8. Lefelé kumulált gyakoriság számítása ... 13
3.9. Relatív kumulált gyakoriság ... 14
3.10. Mérőcsoportok ... 15
3.11. Értékösszegsor számítása. ... 16
3.12. Kvantilisek. ... 16
3.13. Kvantilisek meghatározásához kiindulási adattábla. ... 17
3.14. Medián számítás alapadatai felfelé kumulált gyakorisággal ... 19
3.15. Medián számítás alapadatai relatív kumulált gyakorisággal ... 20
3.16. Módusz meghatározásának lépései ... 21
3.17. Módusz meghatározása makróval. ... 22
3.18. Terjedelem meghatározása. ... 25
3.19. Szórás meghatározása. ... 27
3.20. Súlyozott szórás meghatározása. ... 28
3.21. Relatív szóródás meghatározása. ... 30
3.22. Különbség számításához alapadatok ... 32
3.23. Momentum számítás (berendezés megbízhatósága) ... 34
4.1. Monitorállomások alap-műszerezettsége ... 43
7.1. Hibaszámítási adatok – feladat megoldása ... 54
7.2. Egymintás t- próba – feladat megoldása ... 55
7.3. A feladat megoldása – 1. rész ... 56
7.4. A feladat megoldása – 2. rész ... 58
7.5. PM10 - párhuzamos mérések eredményei ... 61
7.6. PM2,5 - párhuzamos mérések eredményei ... 62
7.7. Statisztikai vizsgálatok eredménye ... 64
7.8. Feladat megoldása standardizálással ... 65
10.1. Vizsgált mintavételi helyre jellemző összessó-tartalom jellemző és számított adatsorai ... 73
11.1. Szennyvízkibocsátók az ipari parkban. ... 80
11.2. Előzetes számítások a Gini-együtthatóhoz. ... 82
11.3. Osztályközök létrehozása. ... 83
11.4. Gyakoriságok értékei. ... 84
11.5. Gyakoriságok számítása. ... 84
11.6. Érkékösszegsorok. ... 85
11.7. Értékösszegsorok számítási módja. ... 85
11.8. Gini együtthatóhoz szükséges segédtábla ... 86
11.9. Gini együtthatóhoz szükséges segédszámítások. ... 86
1. fejezet - Jelmagyarázat és rövidítésjegyzék
dB deciBell, a hangnyomásszint mértékegysége
WGS84 A GPS által használt vonatkoztatási rendszer
GPS global positioning system (globális helymeghatározó
rendszer)
EOV egységes országos vetület
b kiindulási (bázis) érték jelölése
bi bázis-viszonyszám értéke az i. adatra
y statisztikai adat illetve egyed (elemi információegység)
yi az i. adat
li lánc-viszonyszám értéke az i. adatra
Vm megoszlási viszonyszám
n elemek száma
Vi intenzitási viszonyszám
fi abszolút gyakoriság
gi relatív gyakoriság
xi osztályközép értéke
Yi0 az i. osztályköz alsó határértéke
Yi1 az i. osztályköz felső határértéke
hi hosszúsága
k osztályközök száma
abszolút kumulált gyakoriság
relatív kumulált gyakoriság
2. fejezet - Bevezetés
MIÉRT FONTOS AZ ADATKEZELÉS?
Jelen jegyzet a leendő fenntartható fejlődés szakértő hallgatók számára a szükséges részletességig ismerteti az adatgyűjtés és –értékelés matematikai hátterére, ugyanakkor a fenntartható fejlődés témaköréből választja a példákat, és azokon keresztül mutatja be adatok felhasználásának módját és lehetőségeit.
A környezetvédelmi elemzések során rendszerint hatalmas mennyiségű – jellemzően – számadat keletkezik. Az emberi agy felépítéséből következően inkább analitikus, elemző munkára képes, mint manuális, monoton számítások elvégzésére. e összhangot kell találni az emberi gondolkodás és a gépi számítások között. Ebben szintén segítséget nyújt e könyv, bemutatva mit lehet a gépre bízni és mi az amit emberi elmére.
A jegyzet elektronikus tanulásra készült és feltételezi, hogy megfelelő számítógépes alapismeretekkel rendelkezik a felhasználó a példák LibreOffice (régebben OpenOffice) Calc vagy Microsoft Office Excel szoftveren történő gyakorlására. Az anyag megértéséhez – mivel bármilyen felsőfokú végzettséggel rendelkező hallgató számára érthető kíván maradni – csak alapvető matematikai ismeretekkel kell rendelkezni. Éppen ezért az anyag egy része a mérnök és gazdálkodás szakon végzettek számára már ismert lehet, de a példák környezetvédelmi vonatkozásai miatt nekik is célszerű átolvasni e részeket.
A digitális technológia kiszélesíti a tanulási lehetőségeket, és egyben meg is változtatja a tanítási módszereket.
Az elektronikus tananyagoknak mindenekelőtt felhasználóbarátnak kell lenniük, hiszen ha nem élvezetes a velük való foglalkozás az elveheti a hallgatók kedvét a tanulástól, az adott témától, anyagrésztől.
Az anyagból meg fogjuk ismerni az adatokkal való dolgozás buktatóit és hogyan vehetjük észre e csapdákat.
Megismerjük, hogyan lehet ugyanabból a hiteles mérési adatsorból kiindulva „bizonyítani”, hogy a légszennyezés egy településen 50%-kal nőtt és azt is, hogy 30%-kal csökkent; és azt is hogyan lehet az ilyen típusú adatfeldolgozásokat felismerni.
3. fejezet - Nagy mennyiségű adatok feldolgozásának statisztikai alapjai
A világunkat a számok mozgatják. Mégis egyre többen vannak, akik idegenkednek a számok világától és nem értik vagy nem akarják érteni azok jelentését. A természet és a világgazdaság folyamatainak megértéséhez elengedhetetlenül szükséges a számok elemzésének ismerete, a statisztika. E fejezet célja, hogy közérthetően, példákkal szemléltetve megismertesse az olvasóját a statisztika alapjaival. Nem célja, hogy statisztikusokat képezzen, ezért csak szemezget a mindennapi életben leggyakrabban előforduló ismeretekből. Ezen ismeretekkel könnyebben kivédhetjük azt a – sajnos – egyre gyakoribb tapasztalatot, hogy mind több és több gazdasági és politikai szereplő kihasználja az emberek statisztikai hiányosságait. Ez legtöbbször abban nyilvánul meg, hogy olyan összefüggéseket hitetnek el velünk, amilyeneket – ha nem a számok nyelvén mondanák – senki nem hinne el.
1. Alapfogalmak
Mi is a statisztika? A következő két megfogalmazás két híres magyartól származik:
• Lukács Ottó: „Tapasztalati adatokból (mintákból) következtetni az egész sokaság valószínűségeire, eloszlás- és sűrűségfüggvényeire, azok paramétereire.”
• Besenyei Lajos: „A valóság tényeinek tömegét tömören, a számok nyelvén jellemző tudományos módszertan illetve gyakorlati tevékenység.”
Mindkét állítás jól leírja a lényeget, de Besenyei megfogalmazása közelebb áll a környezetvédelemmel, a fenntartható jövővel foglalkozó szakemberek munkájához. Az adatokkal való munka során célunk a valóság folyamatainak elemzése, amit legtöbbször a jövőre vonatkozó becslések követnek. Ahhoz, hogy megértsük, a statisztika alapjait néhány fogalmat tisztázni kell:
• Sokaság (populáció): A vizsgálat (megfigyelés) tárgyát alkotó egyedek összessége. Napjainkban egyre többször azonosítjuk az adat megnevezéssel. Ezen irányzat a számítástechnika előretörésével egyre inkább terjed.
• Megfigyelési egység: amelyre/akire a megfigyelés irányul
• Számbavételi egység: amely/aki információt szolgáltat a megfigyelési egységre vonatkozóan
1.1. Sokaság
Az adatokkal való munka egyik kulcslépése, hogy képesek legyünk besorolni az adatunkat a megfelelő sokasági kategóriákba. E kategóriák a következő képen oszthatóak fel:
• Vonatkozás szerint
• Időpontra: Egy jól meghatározható időpontra (tegnap, tavaly, 1974.09.01-én, stb).
• Időtartamra: Két időpont között (hétfőtől péntekig, 1974-2000-ig). De például tavaly január 1-től december 31-ig szintén időtartam, bár megegyezik az időpontban példaként felsorolt „tavaly” fogalommal. A különbség: itt a 365 darab napot értjük rajta, míg az időpontnál a teljes évet, mint „év” vesszük figyelembe.
• Érték szerint
• Diszkrét: Ide tartoznak, azok az adatok, amelyek már nem változnak meg az idő előrehaladtával. Időpontra és időtartamra is vonatkozhat. Például a települések száma egy adott időpontban vagy a tavalyi évben (időtartam) bejelentett szmog-riadók száma egy településen.
• Folytonos: Ezen adatoknál csak az adott pillanatig bekövetkezett eseményeket tudjuk számszerűsíteni, amely akár már a következő időpillanatban megváltozhat. Vonatkozhat időpontra és időtartamra is.
Például: szmogos napok száma idén (időtartam) vagy jelenleg belvízzel borított területek mérete (időpont).
• Típusra:
• Álló (állomány): Ebben az esetben a sokaság egy darab jó meghatározható értékből áll, ami önmagában is értelmezhető. Csak időpontra vonatkozhat. Például a talaj-közeli ózon napi átlagos töménysége tegnap (időtartam esetén) vagy talaj-közeli ózon jelenlegi átlagos töménysége (időpont esetén).
• Mozgó (áramlás): E típus esetén egy adattömeggel dolgozunk, amely azonos jelenségnek írja le az időbeni változását. Csak időtartamra vonatkozhat. Például a talaj-közeli ózon óránkénti átlagos töménysége (időtartam).
A sokasági kategóriába történő besorolást nagy mértékben segíti ha pontosan utánajárunk az adatok forrásának és jelentésének. E megállapítás bár köznapinak tűnik, nem szabad könnyelműen kezelni: nagyon sokszor még a gyakorlott tudósok is gondban vannak egy adat jelentésének megállapításánál. Ennek oka, hogy számos adatközlő nem tájékoztat arról, hogy pontosan mit is takar az adott adat (hogyan mérték, milyen pontosságú a műszer, stb.).
1.2. Ismérv (attribútum)
Az ismérv a sokaság egységeit jellemző tulajdonság vagy az adott szempont szerint lehetséges tulajdonságok halmaza. Gyakorlatilag olyan szempontok, amelyek alapján a sokaság egymást át nem fedő részekre bontható.
Az egyes ismérvkategóriákra adható válaszok az ismérvváltozatok, amelyek lehetnek megszámlálhatóak (például a kémhatás csak savas, lúgos vagy semleges lehet, de a NOX töménység értéke – majdnem – bármilyen nagy szám lehet és csak a mérés pontosság határozza meg, hogy hány változata fordulhat elő). Azoknál az ismérvváltozatoknál, ahol csak két változat van, alternatív ismérvnek is hívjuk. A mennyiségi ismérvek ismérvváltozatait ismérvértéknek is nevezhetőek.
Az ismérveket több féle képen csoportosíthatjuk. Fő csoportosítás alapján lehet
• közös (a sokaság minden tagjára igazak) vagy
• megkülönböztető (az egyedek vagy azok egy csoportja elkülöníthető).
Ezen kívül jellemzőjük alapján négy csoportba soroljuk az ismérveket:
• Tárgyi ismérvek
• Minőségi ismérv: A sokaság számszakilag, időponttal vagy térbeli adattal ki nem fejezhető (jellemzően azonosításukat szolgáló) ismérvei. Ilyen ismérv például a légszennyező anyag, ismérvváltozatai az NOX, O3, CO2, stb.para>
• Mennyiségi: A sokaság számokkal kifejezhető (mérhető) egyedei. A statisztika ezen ismérvekkel foglalkozik a leggyakrabban. Ilyen ismérv például a föld-közeli ózon töménysége.
• Időbeli ismérv: A sokaság adott elemének időpontját tároló érték. Értéke lehet egy pontos időpont, de lehet időtartam is. Például a mérés ideje (időpont) vagy a mérés időtartama.
• Területi ismérv: A sokaság adott elemének földrajzi rögzítésére szolgáló ismérv. Lehet számszerűsített (például a mérés GPS koordinátája), közismert nevekhez kötött (például Veszprém) vagy viszonylagos (például „a második emeleten”).
1.3. Mérés
Mérésnek az egységek számokkal való jellemzését értjük. A környezetvédelemben négy mérési skálát (szintet) használunk.
• Nominális (névleges) mérési skála: Az egységekhez rendelt számértékek egyező vagy különböző voltát engedi meg. Például:
• Két talajminta higany töménysége azonos-e vagy sem. (Figyeljük meg a példát: az információból nem tudjuk magasabb-e, vagy alacsonyabb a higany töménysége, sem egyéb ismeretet.)
• Van-e higany a talajban vagy nincs.
• Ordinális (sorrendi) mérési skála: Az egységek a tulajdonságok szerint rangsorba állíthatók. (Tudunk nagysági különbséget tenni közöttük. Tudjuk, hogy nagyobb, kisebb, de a mértékét nem.). Például:
• A talajminta higanytartalma alapján milyen szennyezettség-osztályba tartozik. (De nem tudjuk – vagy nem érdekes – az osztályok közötti pontos koncentráció-különbség.)
• A mérési adatok higanytartalom szerinti sorrendje. Ez esetben nem ismert az adatok közötti távolság.
• Intervallum mérési skála: A rangsorba rendezett tulajdonságokat egyenlő közök választják el, de nem tudjuk a kezdőértéket. Figyeljünk rá, hogy a „0” is köznek számít! Például:
• A minta a 0-10 μg/kg, 10-20 μg/kg közötti higany töménységű talajok csoportjába tartozik-e? (De nem mondhatjuk, hogy a 20 μg/kg töménységű talaj kétszer szennyezettebb, mint a 10 μg/kg-os, mivel nem tudjuk mennyi a „tiszta” talaj higanytartalma.)
• Arányskála: A kezdőpont egyértelműen adott és rögzített, s így a skálaértékek egymáshoz való aránya is meghatározható. Ezen skálába tartozó adatok valók teljes elemzési műveletek elvégzésére. Példa:
• Tudjuk, hogy mennyi a talaj általános higany koncentrációja.
Fontos, hogy a besorolásoknál nem az számít, hogy mi az adat tényleges információtartalma, hanem, hogy milyen információ érdekes számunkra. Például egy éjszakai szórakozóhely hangnyomásszintjének („zajosságának”) felmérése során percenként rögzítjük öt ponton, egy-egy órán keresztül a hangnyomásszinteket. Ez az adatsor nominális skálának számít, ha csak arra vagyunk kíváncsiak, hogy átlépte-e a megengedett hangnyomásszintet a létesítmény, vagy sem. Ugyan ez az adatsor ordinális skálának minősül, ha arra vagyunk kíváncsiak, hogy a hangnyomásszint milyen súlyos a zajszennyezés (nincs büntetés, pénzbüntetés, bezárás). Végül lehet intervallum vagy arányskála is, ha a mérési adatokat 10 dB-ként csoportosítjuk és tudjuk a hallásküszöb értékét is.
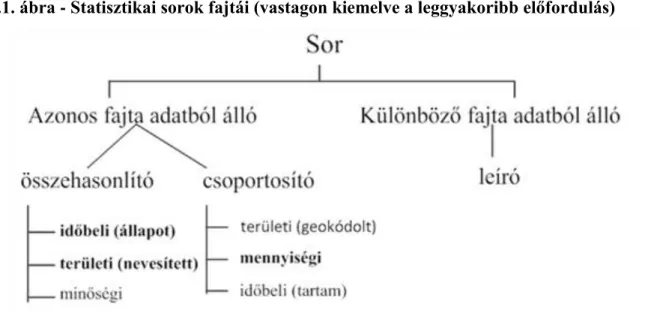
1.4. Statisztikai sor
A sokaság egységeinek bizonyos ismérvek szerinti csoportosítása, rendezése.
3.1. ábra - Statisztikai sorok fajtái (vastagon kiemelve a leggyakoribb előfordulás)
A benne szereplő adatok összegezhetősége szerint lehet:
• Csoportosító statisztikai sor: adatai összegezhetők, számszakilag értelmezhetők (például árvízzel borított területek összes felülete).
• Összehasonlító sor: adatai nem összegezhetők, számszakilag értelmetlen (például a minta színe)
A sorban szereplő adatok fajtái szerint:
• idősor: időbeli ismérv alapján csoportosítva az adatokat
• állapot idősor: Adatai számszakilag nem összegezhetők, egy adott időpontra vonatkoznak (például a mérés időpontja 2011.12.20. 08:15).
• tartam idősor: Adatai számszakilag összegezhetőek (de nem felétlenül értelmesek is az összegzés után!), adatai időtartamra vonatkoznak (például az egymás követő mérések időtartama).
• minőségi sor: Az adatoknak minőségi ismérv szerinti rendezése (például a minta szaga).
• mennyiségi sor: Az adatoknak mennyiségi ismérv szerinti rendezése (például a hangnyomásszint mért értéke).
• területi sor: Az adatok területi hovatartozást jelentenek.
• nevesített területi sor: A területi adatok nem számszerűsített formában állnak rendelkezésre. Ilyen adat például: „a mérés a gyárkapu előtt történt”.
• geokódolt területi sor: A területi adatok számszerűsített (geokódolt) formában állnak rendelkezésre, amelyekkel térbeli műveletek végezhetőek (például vektorműveletek). Ilyen adat jellemzően WGS84 („GPS”) vagy EOV koordináta.
• leíró sor: Ebbe a kategóriába azok a sorok tartoznak, ahol egy mérés különböző tulajdonságát soroljuk fel.
Jellemzően ezek az adatok a „megjegyzés” rovatban szoktak feltüntetésre kerülni egy mérés során.
2. Viszonyszámok
Amikor két adatot vagy adatcsoportot szeretnénk összehasonlítani, akkor két vizsgált érték hányadosát statisztikai viszonyszámnak nevezzük. Az általunk érintett témakörben három viszonyszámot használunk nagy gyakorisággal:
• Összehasonlító sorból: összehasonlítási viszonyszám (dinamikus, területi)
• Csoportosító sorból: megoszlási viszonyszám
• Leíró sorból: intenzitási viszonyszám számítható.
2.1. Dinamikus viszonyszám
Két időszak adatának hányadosa. Csak idősorokból lehet számítani, a számított eredmény az idősor két adatának egymáshoz való aránya. A két adatot tárgy időszaknak (időben a vizsgálat céljához közelebbi adat) és bázis időszaknak (időben a vizsgálat céljától távolabbi adat)
Ha több időszakunk van (például egy év napi átlagos hőmérséklet adatai), akkor az viszonyíthatjuk egymáshoz (láncviszonyszám), vagy az időben első adathoz, amit bázisnak nevezünk (bázisviszonyszám). Számításuk a következő:
• Bázis-viszonyszám: bi = yi / yb
• Láncviszonyszám: li = yi / yi-1
A két viszonyszám egymásból is számítható a következő képletekkel:
Bázisviszonyszámból láncviszonyszám:
Láncviszonyszámból bázisviszonyszám:
2.2. Megoszlási viszonyszám
Egy adott sokaságból egy kiválasztott tartomány része. Értéke megmutatja, hogy a sokaságban milyen súllyal találhatók az adott csoport tagjai. Ezt a viszonyszámot használjuk leggyakrabban, ha valamilyen esemény előfordulásának gyakoriságára vagyunk kíváncsiak.
Számítása:
vagy
Számítása táblázatkezelő rendszerben:
3.1. táblázat - Megoszlási viszonyszám számítása táblázatkezelő rendszerben
A B
1 Minta azonosítója Szennyezett?
2 AD231 igen
3 AB322 nem
4 AS231 nem
5 AB343 nem
6 AA231 igen
7 Megoszlási viszonyszám a
szennyezett mintára: KÉPLET*
*ahol a képlet helyére a következőt kell írni, MS Office és LibreOffice esetében egyaránt:
=DARABTELI(B2:B6;"igen")/DARAB2(B2:B6)
2.3. Intenzitási viszonyszám
Egy adott sokaság egészéből (pl. városok) egy másik sokaság egészére (pl. lakosság) mennyi jut. Célja, hogy meghatározhatjuk a sokaság egyedeit érő átlagos terhelést vagy megoszlást. (Ne keverjük össze a MEGOSZLÁSSAL!)
Számítása:
vagy
A számítás során az osztóban szereplő adatot a statisztikai gyakorlat – a könnyebb kezelhetőség érdekében - sok esetben nagyobb egységként veszi figyelembe. Például a második számítási minta esetében sokkal gyakoribb,
hogy az osztó nem fő, hanem ezer fő. Ezzel egynél nagyobb számot tudunk kapni, amit könnyebben értelmezünk.
2.4. Számításértelmezési feladat
Egy vizsgáljuk meg, hogyan alakul a szmog-riadót hirdetett napok száma egy településen. Az adatok a következőek:
3.2. táblázat - Szmogriadók száma 2008-2011 között
Év Szmog-riadók száma (nap)
2008 3
2009 6
2010 8
2011 5
Számítsuk ki a 2008-hoz, mint bázisévhez viszonyítva 2011 viszonyszámát:
Számítsuk ki 2011 láncviszonyszámát 2010-es évhez képest:
Mit olvashatunk ki a számokból? Ha 2011-et vizsgáljuk, akkor írhatunk egy újságcikket, amiben megállapíthatjuk – és számszakilag bizonyíthatjuk is –, hogy a szmog-riadós napok száma több mint másfélszeresére nőtt (bázisviszonyszám) de írhatunk olyat is, hogy a szmog-riadós napok száma több mint harmadával csökkent (láncviszonyszám). Ezen egyszerű példa is jól megvilágítja, hogy a statisztika kétélű tudományos módszer, amellyel szándékosan vissza lehet élni, de tudatlanságunkból fakadóan akaratlanul is félrevezethetjük magunkat és másokat.
Ahhoz, hogy az ilyen félreértelmezéseket elkerüljük:
• Mindig tisztába kell lennünk az adatok forrásával: sok vizsgálat esetében attól függően, hogy milyen szabvány, milyen metódus szerint végezzük a mérést máshogy és máshogy értelmezendő adatokat kapunk.
Kiemelten igaz ez a nagy léptékű társadalmi és gazdasági események mérésére, ahol nem homogén és nagyon nagy méretű a minta, ezért csak (reprezentatív) mintavétellel lehet mérni.
• Lehetőleg az adatoknak a környezetét is ismerjük meg. Mint azt előző példafeladat alapján is látjuk, ha csak két adatot ismerünk, akkor nagyon könnyen belefuthatunk a folyamat egészére nem jellemző rendellenességbe, mérési hibába, váratlan eseménybe.
• Értelmezzük az eredményt! Például ha csak annyit olvasunk, hogy a viszonyszám nézzük meg lánc- vagy bázisviszonyszám-e. Ha az olvassuk „arány”, akkor nézzük meg minek is az aránya? Egyáltalán összehasonlítható a két adat? Mialatt ezeket a kérdéseket feltesszük magunkban és megkeressük rá a választ az esetek döntő hányadában megbizonyosodhatunk arról, hogy megfelelően feldolgozott adattal van-e dolgunk.
3. Eloszlás-elemzés
A környezetvédelemben és általában a természettudományokban nagy szerep jut az empirikus eloszlásoknak.
Amely a megfigyelések (kísérletek) eredményeként kapott adatok eloszlását jelenti. Amikor nem – csak – valós
megfigyelések eredményeiről van szó, azt elméleti elosztásnak nevezzük és a valószínűség-számítás tárgykörébe tartozik.
Az eloszlás elemzés legfontosabb eszközei a következők:
• Gyakorisági sorok
• Kvantilisek
• Középértékek
• Szóródás
3.1. Gyakorisági sorok
Valamely sokaságnak egy mennyiségi ismérv szerinti csoportosítása. Segítségével különösen a nagy mennyiségű adatok kezelésénél tudjuk könnyebben áttekinteni sokaságot. Célja, hogy a sokaság összetételéről kapjunk áttekintést. Leggyakrabban osztályközös gyakoriság formájában használjuk.
Az osztályközös gyakoriság alapvetése a következő: Vegyünk egy Y ismérv valamely N számú egységéhez tartozó Y1,Y2,…Yn változatait (ezek lehetnek számszerűek és nem számszerűek is). Legyen az Y ismérv különbség- vagy arányskálán mért számérték Az Y neve változó, az Yi-ket pedig (ismérv)értékeknek nevezzük.
Rendezzük sorba monoton nem csökkenő módon. Ezt nevezzük rangsornak. Nagy N esetén osztópontok kijelölésével a rangsort feldaraboljuk, ezek a részek az osztályközök. Osztályközökkel szembeni fontos követelmény, hogy azok nem fedik át egymást és az osztályközök összessége lefedi a teljes sokaságot.
3.3. táblázat - Osztályközös gyakoriság alaptáblázata
Az Y szerint képzett osztály Osztályközép Abszolút fi
Relatív gi
alsó felső xi gyakoriság
határa
Y10
Y20
: Yi0
: Yk0
Y11
Y21
: Yi1
: Yk1
x1
x2
: xi
: xk
f1
f2
: fi
: fk
g1
g2
: gi
: gk
Összesen N 1 (100%)
Az osztályközös gyakoriság esetében használt fogalmak a következőek:
• Az abszolút gyakoriság (jele: fi) megadja, hogy az adott osztályba hány darab egység tartozik sokaságból.
• A relatív gyakoriság (jele: gi) megadja, hogy az adott osztályba tartozó elemek milyen súllyal szerepelnek a sokaságban. Számítása: gi=fi / N;
• Az osztályközép értéke kifejezi az adott osztályköz középértékét. Számítása: xi=1/2 × (yi0 + yi1);
• Az osztályköz hosszúság értéke az adott osztályköz két határértékének távolsága. Számítása: hii=yi1-yi0;
Első kérdés, amit el kell dönteni, hogy hány osztályközt alkossunk? A legjobb megoldás, ha az adatok ismeretében magunk határozzunk meg a szükséges osztályközök számát, de ez általában nem lehetséges. Ezért a
(amiből )
képlettel határozzuk meg a közelítő osztályköz-számot, amit szükség esetén kézzel korrigálunk.
Ha egyenletes osztályközöket akarunk képezni, akkor az osztályköz hossza:
Ha egyenetlen az adatok megoszlása, akkor egyenlőtlen közöket alkalmazunk:
ahol sz – az ismérvérték utolsó fontos számjegyének helyértéke.
3.1.1. Osztályközös gyakoriság számításának lépései
Y legyen a veszprémi légszennyezettség-mérő állomás órás NOx töménység-mérési adatai a tegnapi napra. (N = 24; Y1 jelentse az 1. óra átlagát, Y2 jelentse a 2. óra átlagát, stb.)
3.4. táblázat - Veszprémi légszennyezettség-mérő állomás órás NOx töménység-mérési adatai
Időpont Ismérv Érték Rangsort
készítünk
→
Rangsor
0-1 Y1 40 35
1-2 Y2 45 36
2-3 Y3 43 36
3-4 Y4 36 38
4-5 Y5 39 39
5-6 Y6 46 39
6-7 Y7 51 40
7-8 Y8 57 43
8-9 Y9 93 43
9-10 Y10 98 45
10-11 Y11 67 45
11-12 Y12 56 45
12-13 Y13 45 46
13-14 Y14 56 51
14-15 Y15 35 54
15-16 Y16 76 56
16-17 Y17 89 56
17-18 Y18 92 57
18-19 Y19 54 67
19-20 Y20 45 76
20-21 Y21 43 89
21-22 Y22 38 92
22-23 Y23 39 93
23-24 Y24 36 98
Osztályközök száma:
Számítása táblázatkezelő rendszerben: A kiválasztott adatsort nagyság szerint kell rendezni.
Ezt a feladatot MS Office esetén az adatok kijelölése után a következő gombbal tudjuk megtenni:
3.2. ábra - Adatok rendezésének gombja MS Excelben
Ugyanezt a feladatot a LibreOffice-ban az adatok kijelölése után a következő gombbal tudjuk megtenni:
3.3. ábra - Adatok rendezésének gombja LibreOfficeban
Egyenletes osztályköz esetén:
Az osztályköz táblázat a következő képen néz ki egyenletes osztályköz esetén:
3.5. táblázat - Osztályköz táblázat egyenletes osztályköz esetén
Yi0 Yi1 Xi fi gi
35 47 41 13 ~0,54
48 60 54 5 ~0,21
61 73 67 1 ~0,04
74 86 80 1 ~0,04
87 99 93 4 ~0,17
24 1
3.1.2. Kumulálás (halmozott összeadás)
A kumulálás célja, hogy meghatározzuk hány darab adatunk (mintánk) értéke 1. kisebb vagy egyenlő (felfelé kumulált gyakoriság) illetve
2. nagyobb vagy egyenlő (lefelé kumulált gyakoriság)
mint a vizsgált osztályköz. A kumulált gyakoriság jele: fi'; A kumulált gyakoriságot lehet abszolút gyakoriságból és relatív gyakoriságból is számolni.
A kumulált gyakoriság igen gyakran használt mérőszám, ha arra vagyunk kíváncsiak, hogy a mérések közül hány darab lépte át az adott vizsgálathoz tartozó környezetvédelmi határértéket (vagy éppen maradt alatta).
A kumulálás menete a következő:
Felfelé kumulálás esetén: azaz ahhoz, hogy az abszolút felfelé kumulált gyakoriság értékét megkapjuk minden sorban összeadjuk az adott sor és a megelőző sorok abszolút gyakorisági (fi) értékeit.
Lefelé kumulálás esetén: azaz ahhoz, hogy az abszolút lefelé kumulált gyakoriság értékét megkapjuk minden sorban összeadjuk az adott sor és a megelőző sorok abszolút gyakorisági (fi) értékeit, majd a kapott értéket kivonjuk a mintaszámból (n).
Példa: Kumulált gyakoriság
A veszprémi légszennyezettség-mérő állomás órás NOX töménység-mérési adatait alapként használva (lásd:
Osztályközös gyakoriság számításának lépései) a következő eredményt kapunk:
3.6. táblázat - Kumulált gyakoriság
Yi0 Yi1 Xi fi felfelé kumulált
gyakoriság (f'i)
lefelé kumulált gyakoriság (f'
i)
35 47 41 13 13 24
48 60 54 5 13+5=18 24-13=11
61 73 67 1 13+5+1=19 24-13-5=6
74 86 80 1 13+5+1+1=20* 24-13-5-1=5**
87 99 93 4 13+5+1+1+4=24 24-13-5-1-1=4
A felfelé kumulált gyakoriság számítása mind MS Excel mind LibreOffice táblázatkezelő rendszerben a következő:
3.7. táblázat - Felfelé kumulált gyakoriság számítása
A B C D E
1 Yi0 Yi1 Xi fi felfelé kumulált
gyakoriság (f’i)
2 35 47 41 13 =SZUM($D$2:D2)
3 48 60 54 5 =SZUM($D$2:D3)
4 61 73 67 1 =SZUM($D$2:D4)
5 74 86 80 1 =SZUM($D$2:D5)
6 87 99 93 4 =SZUM($D$2:D6)
Megjegyzés: Elég az E2 cellába megírni a képletet, utána le lehet húzni az összes többi cellába.
A lefelé kumulált gyakoriság számítása mind MS Excel mind LibreOffice táblázatkezelő rendszerben a következő:
3.8. táblázat - Lefelé kumulált gyakoriság számítása
A B C D E
1 Yi0 Yi1 Xi fi felfelé kumulált gyakoriság
(f’i)
2 35 47 41 13 =SZUM($D$2:D6)
3 48 60 54 5 =SZUM($D$2:$D$6)- SZUM($D$2:D2)
4 61 73 67 1 =SZUM($D$2:$D$6)-
SZUM($D$2:D3)
5 74 86 80 1 =SZUM($D$2:$D$6)-
SZUM($D$2:D4)
6 87 99 93 4 =SZUM($D$2:$D$6)-
SZUM($D$2:D5) Megjegyzés: Elég az E2 és az E3 cellába megírni a képletet, utána az utóbbit le lehet húzni az összes többi cellába.
Példa: Relatív kumulált gyakoriság
A veszprémi légszennyezettség-mérő állomás órás NOx töménység-mérési adatait alapként használva (lásd:
Osztályközös gyakoriság számításának lépései) a következő eredményt kapunk:
3.9. táblázat - Relatív kumulált gyakoriság
Yi0 Yi1 Xi gi felfelé kumulált
relatív gyakoriság (g’i)
lefelé kumulált relatív gyakoriság
(g’i)
35 47 41 ~0,54 0,54 1,00
48 60 54 ~0,21 0,54+0,21=0,75 1,00-0,54=0,46
61 73 67 ~0,04 0,54+0,21+0,04=0,
79
1,00-0,54- 0,21=0,25
74 86 80 ~0,04 0,54+0,21+0,04+0,
04=0,83
1,00-0,54-0,21- 0,04=0,21
87 99 93 ~0,17 0,54+0,21+0,04+0,
04+0,17=1,00
1,00-0,54-0,21- 0,04-0,04=0,17
3.4. ábra - A kumulált gyakoriság ábrázolása
Táblázatkezelő rendszerekben történő számítása megegyezik a kumulált gyakoriság (f’i) számításával.
3.1.3. Értékösszegsor
Az osztályközökhöz az azokba tartozó egységek ismérvértékeinek szorzatát rendeli. A mennyiségi ismérv értékeinek egyes osztályokon (osztályközökön) belüli összegeit értékösszegnek nevezzük.
Az értékösszeg gyakorlatilag az osztályköz ismérvvel súlyozott értékét adja meg. Ez önmagában is hasznos lehet, de az értékösszegsor környezetvédelemben leggyakrabban használt formája a relatív értékösszegsor (Zi).
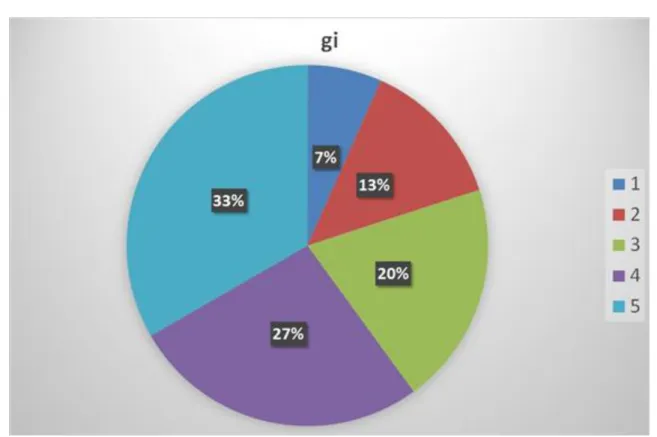
Ebben az esetben az értékösszegeket a teljes értékösszegsorral arányosítjuk, így arányszám formájában kapjuk meg a súlyozások értékét:
Példa:
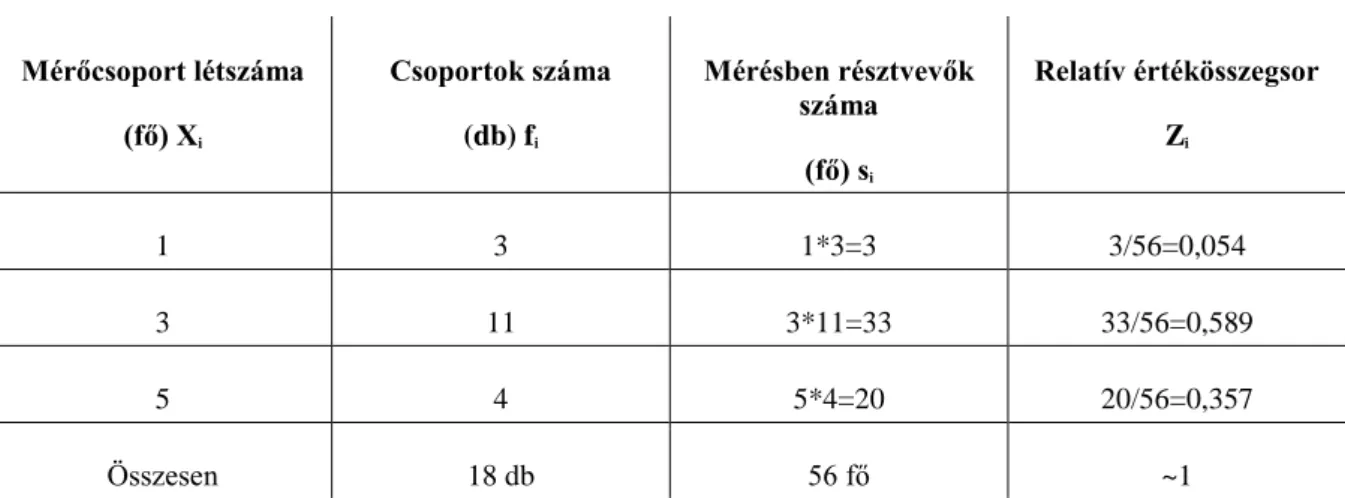
Egy terepi mérés során 1; 3 és 5 fős mérőcsoportokat küldtek ki. A csoportok száma rendre 3; 11 és 4 darab volt.
Melyik létszámú mérőcsoportban mekkora összlétszám dolgozott? Mi volt a csoportokban dolgozók egymáshoz viszonyított aránya? Melyik a legnagyobb súlyú csoport?
3.10. táblázat - Mérőcsoportok
Mérőcsoport létszáma (fő) Xi
Csoportok száma (db) fi
Mérésben résztvevők száma
(fő) si
Relatív értékösszegsor Zi
1 3 1*3=3 3/56=0,054
3 11 3*11=33 33/56=0,589
5 4 5*4=20 20/56=0,357
Összesen 18 db 56 fő ~1
A fenti feladatot mind MS Excel mind LibreOffice táblázatkezelő rendszerben a következő módon oldhatjuk meg:
3.11. táblázat - Értékösszegsor számítása.
A B C D
1 Mérőcsoport
létszáma (fő) Xi
Csoportok száma (db) fi
Mérésben résztvevők száma (fő) si
Relatív értékösszegsor
Zi
2 1 3 =A2*B2 =C2/$C$5
3 3 11 =A3*B3 =C3/$C$5
4 5 4 =A4*B4 =C4/$C$5
5 Összesen 18 db =SZUM(C2:C4) 1
A példa kérdésére a válasz: A legnagyobb súlyú csoport (58,9%-os részesedéssel) a három mérőszemélyből álló mérőcsoport.
3.2. Kvantilisek
A kvantiliseknek nagyon jelentős szerepük van a környezetvédelmi gyakorlatban. A kvantilisek módszere az egyenlő gyakoriságú osztályközök képzése, amely az értékek elhelyezkedéséről gyors tájékoztatást ad. Típusait az osztályközök száma alapján határozzuk meg. Ezek közül többet a gyakori használat miatt nevesítve, egyedi jelöléssel is használunk:
3.12. táblázat - Kvantilisek.
Osztályközök száma (k) Elnevezés Jelölés Lehetséges kvantilisek
2 4 5 10
Medián Kvartilis Kvintilis Decilis
Me Qi Ki Di
Me Q1, Q2, Q3 K1,K2,K3,K4 D1,D2,..,D9
Osztályközök száma (k) Elnevezés Jelölés Lehetséges kvantilisek
100 Percentilis Pi P1,P2,..,P99
A kvantilis meghatározása a következő: Az (i. k-ad rendű kvantilis szám az a szám, amelynél az összes előforduló ismérvérték -ad része kisebb, -ad része nagyobb ( és i=1,2,…,k-1). Az hányadost p- vel jelöljük,míg a Yp kvantilis neve p-ed rendű kvantilis. A kvantilis értékek nem feltétlenül léteztek a sorban korábban, ebben az esetben a kvantilis értékei innentől beletartoznak a sorba.
A számítás menete a következő:
1) Első lépésben meg kell határoznunk a kvantilis osztópontját (sorszámát).
Az osztópontok száma gyakorlatilag az osztályközök számánál eggyel kisebb, azaz a medián esetén 1, kvartilis esetén 3. Ennek oka, hogy ezek a pontok határozzák meg az osztályközök töréspontjait. Fontos kiemelni, hogy ezek nem valóságos sorszámok (ezért is hívjuk őket osztópontoknak), hanem csak segédértékek. Így nem okoz gondot, hogy az esetek nagy részében ezek értéke nem egész szám.
Példa: Az „Osztályközös gyakoriság számításának lépései” fejezetnél megismert példában szereplő 24 minta esetén a kvartilis osztópontok számítása a következő:
2) Ha meghatároztuk az osztópontok értékeit, akkor ki kell számolni, hogy ezek az osztópontok milyen konkrét értékekhez tartoznak, azaz mekkorák a kvantilis értékei:
Ezek az értékek az esetek többségében nem voltak meg az eredeti értéksorban, de kiszámításuk után már részei lesznek (azaz megnövelik a sor darabszámát).
Példa:
Az „Osztályközös gyakoriság számításának lépései” fejezetnél megismert példában szereplő adatokból az előbb kiszámolt három kvartilis osztópont adatait felhasználva az osztópontok értékei a következők:
Az eredeti adattábla a következő:
3.13. táblázat - Kvantilisek meghatározásához kiindulási adattábla.
i Yi i Yi i Yi
1 35 9 43 17 56
2 36 10 45 18 57
3 36 11 45 19 67
i Yi i Yi i Yi
4 38 12 45 20 76
5 39 13 46 21 89
6 39 14 51 22 92
7 40 15 54 23 93
8 43 16 56 24 98
Az osztópontok a következőek:
Ebből a kvantilisek:
Jelentése: Mivel kvantilisről, azaz négy felé osztásról van szó, így a három kvantilis rendre -e, -e és -e a teljes sornak. Így a Q1 esetében a minták 25%-a kisebb koncentrációjú, mint 39,25. (Azaz 75%-nak nagyobb a koncentrációja ennél.)
Jelentése: A minták 50%-a kisebb koncentrációjú, mint 45,50. (Azaz 50%-nak nagyobb a koncentrációja ennél.)
Jelentése: A minták 75%-a kisebb koncentrációjú, mint 64,50. (Azaz 25%-nak nagyobb a koncentrációja ennél.)
3.3. Középérték
A környezetvédelmi adatok elemzése során sokszor kerülünk olyan probléma elé, hogy meg kell határozni egy adatsor középértékét. Ez számtalan esetben nem a matematikai átlagértéket jelenti, hanem valamilyen szempont szerinti középpontot. A leggyakrabban használt középértékek a következőek:
Helyzeti középértékek:
• Medián (Me)
• Módusz (Mo)
Átlagok (súlyozott és súlyozatlan, a súlyok gyakran a relatív gyakoriságok):
• Számtani átlag ( vagy )
• Mértani (geometriai) átlag ( vagy )
• Harmonikus átlag ( vagy )
• Négyzetes átlag ( vagy ;)
3.3.1. Medián (Me)
Az az ismérvérték, amelynél az összes ismérvérték fele kisebb, fele pedig nagyobb. Ez gyakorlatilag a klasszikus középérték, azaz amikor a számok súlypontját keressük.
Több féle módon is számíthatjuk. Lehetőség van rangsor, kumulált gyakoriság és osztályközös gyakoriság alapján történő meghatározására.
Ha a számítás a rangsor alapján történik, különböző módon, attól függően, hogy a rangsorban lévő adatok darabszáma páratlan vagy páros:
Példa:
Az „Osztályközös gyakoriság számításának lépései” fejezetnél megismert példában szereplő adatokból (24 darab adat) számítva:
; Azaz az adatok pont fele kisebb (illetve nagyobb), mint 45,5.
Ha a számítás a kumulált gyakoriság ismerete esetén történik, akkor a következő képletet használjuk:
Ahol: me: mediánt magába foglaló osztályköz alsó határa
: mediánt megelőző osztályköz kumulált gyakorisága : medián osztályközének kumulált gyakorisága
h: medián osztályközének hossza Példa:
A „Kumulálás (halmozott összeadás)” fejezetnél megismert példában szereplő adatokból számítva:
3.14. táblázat - Medián számítás alapadatai felfelé kumulált gyakorisággal
Yi0 Yi1 Xi fi felfelé kumulált
gyakoriság (f’i)
35 47 41 13 13
48 60 54 5 13+5=18
61 73 67 1 13+5+1=19
74 86 80 1 13+5+1+1=20
87 99 93 4 13+5+1+1+4=24
Ha a számítás a relatív gyakoriság ismerete esetén:
;
Ahol: me: mediánt magába foglaló osztályköz alsó határa
: mediánt megelőző osztályköz kumulált relatív gyakorisága : medián osztályközének kumulált relatív gyakorisága
h: medián osztályközének hossza Példa:
A „Kumulálás (halmozott összeadás)” fejezetnél megismert példában szereplő adatokból számítva:
3.15. táblázat - Medián számítás alapadatai relatív kumulált gyakorisággal
Yi0 Yi1 Xi gi felfelé kumulált
relatív gyakoriság (g’i)
lefelé kumulált relatív gyakoriság (g’i)
35 47 41 ~0,54 0,54 1,00
48 60 54 ~0,21 0,54+0,21=0,75 1,00-0,54=0,46
61 73 67 ~0,04 0,54+0,21+0,04=0,
79
1,00-0,54- 0,21=0,25
74 86 80 ~0,04 0,54+0,21+0,04+0,
04=0,83
1,00-0,54-0,21- 0,04=0,21
87 99 93 ~0,17 0,54+0,21+0,04+0,
04+0,17=1,00
1,00-0,54-0,21- 0,04-0,04=0,17
A három medián érték jelenleg a következő értéket veszi fel:
rangsorból: 45,5 < kumulált relatív gyakoriságból: 46,1 < kumulált gyakoriságból: 46,63
Ez a sorrend csak most alakult így, de nem feltétlenül így fog alakulni a sorrend, ha más kiindulási adatokkal dolgozunk!
3.3.2. Módusz (Mo)
Módusznak a legtipikusabb, leggyakrabban előforduló ismérvet nevezzük. Két típus fordul elő: diszkrét esetben (amikor az adatok önálló, egymástól független értékeket vesznek fel), a leggyakoribb ismérvértéket, míg folytonos esetben (amikor az adatokat egy görbe írja le), akkor a görbe legnagyobb pontjához tartozó érték a módusz. Ez utóbbi esetben a legtöbbször új ismérvérték jön létre, ami részévé válik a sornak.
Példa:
3.16. táblázat - Módusz meghatározásának lépései
Rangsor megszámoljuk az előfordulást
→
Ismérvérték Előfordulás sorba rendezzük
→
Ismérvérték Előfordulás
35 35 1 45 3
36 36 2 36 2
36 38 1 39 2
38 39 2 43 2
39 40 1 56 2
39 43 2 35 1
40 45 3 38 1
43 46 1 40 1
43 51 1 46 1
45 54 1 51 1
45 56 2 54 1
45 57 1 57 1
46 67 1 67 1
51 76 1 76 1
54 89 1 89 1
56 92 1 92 1
56 93 1 93 1
57 98 1 98 1
67 76 89 92 93 98
A számítás eredményét ábrázolva (2.4. ábra) vizuálisan is elkülöníthető a módusz. Ha nem akarjuk ábrázolni, akkor a számolás eredményének sorba rendezésével kapjuk meg az eredményt. A módusz kézi számítása nagyon időigényes folyamat, így célszerűbb táblázatkezelő rendszerre bízni annak kiszámítását.
3.5. ábra - Módusz kiemelése a sokaságból
Módusz számítása táblázatkezelő rendszerben két úton lehetséges. Ha megelégszünk a legtöbbször előforduló értékek közül a legkisebbel (azaz ha például a 39 és a 45 is háromszor fordul elő, akkor csak a 39-et fogjuk megkapni), akkor:
• MS Excel esetében a =MÓDUSZ.EGY(tartomány) utasítással tudjuk elvégezni a számítást. (A tartomány helyébe mindig az adatokat tartalmazó mezőket kell megadni. Például: „=MÓDUSZ.EGY(A2:A25)”)
• LibreOffice esetében a =MÓDUSZ(tartomány) utasítással tudunk eljárni.
Ez a módszer alkalmazása bár kényelmes és gyors, sokszor vezethet tévútra illetve hamis elemzéshez, ami a kézi módszernél sokkal nehezebben fordulhat csak elő. Például vegyük egy város éves óránkénti NOx töménység értékének az adatsorát (24*365=8760 adat). A táblázatkezelő által kiírt módusz érték 10 mg/m3. Ha kézzel végezzük el a számítást, akkor kiderül, hogy valóban a tízes érték fordul elő leggyakrabban az adatsorban (107-szer), de a 45-ös (103-szor) és a 44-es (98-szor) érték szorosan követi a gyakorisági sorban (a következő 19-es érték már csak 37-szer fordult elő). Ha valaki csak a táblázatkezelő értéke alapján dönt, akkor – ahogy sajnos számtalanszor előfordult már – megnyugodva közölheti: a városban leggyakrabban nagyon tiszta a levegő. Ha viszont veszi a fáradságot és elvégzi a teljes elemzést, akkor viszont gyorsan kiderül, hogy a szennyezett értékek száma jóval magasabb, mint a tízes értéké csak – például a műszer mérési jellegzetessége miatt – megoszlik két mérési érték között. Természetesen van kényelmes feloldása a gyors és esetleg félrevezető és a fáradságos, de értékesebb számítás kérdésének. Ez pedig a makro. A táblázatkezelők makro nyelvével gyorsan és hatékonyan elvégezhetjük a számítást. (A makro nyelv ismertetése nem célja ezen anyagnak, de számos kiváló forrásanyag segítheti az elsajátítását.)
A feladat megoldása makro nyelv használatával:
3.17. táblázat - Módusz meghatározása makróval.
A B C D
1 Ismérvek Értékek Előfordulás (db)
2 35 35* 1*
A B C D
3 36 36* 2*
4 36 38* 1*
5 38 39* 2*
6 39 40* 1*
7 39 43* 2*
8 40 45* 3*
9 43 46* 1*
10 43 51* 1*
11 45 54* 1*
12 45 56* 2*
13 45 57* 1*
14 46 67* 1*
15 51 76* 1*
16 54 89* 1*
17 56 92* 1*
18 56 93* 1*
19 57 98* 1*
20 67
21 76
22 89
23 92
24 93
25 98
* A csillaggal jelzett számokat a makro írta be.
Megjegyzés: A makrót korlátlan számú ismérvre le lehet futtatni.
'
'Módusz '
'(C)2011 Dr. Domokos Endre '
Sub Módusz()
Dim t, r, s As Integer Dim Van As Boolean t = 2
r = 2
Do Until Cells(t, 1) = ""
Van = False For s = 2 To r
If Cells(t, 1) = Cells(s, 3) Then Cells(s, 4) = Cells(s, 4) + 1 Van = True
Exit For End If Next s
If Van = False Then Cells(r, 3) = Cells(t, 1) Cells(r, 4) = 1
r = r + 1 End If t = t + 1 Loop End Sub
4. Statisztikai mutatók
A statisztikai mutatók feladata, hogy számszerűen, pontosan megmutassa egy adatsor jellemző értékeit. Míg a grafikonokon alapuló elemzéseket jellemzően az adatsorok gyors áttekintésére, emberi felhasználók számára történő látványos megjelenítésre használjuk a környezetvédelem területén, számos esetben szükségünk lehet továbbszámításokhoz használható, számszaki adatokra. Az erre szolgáló számos módszer közül terjedelmeket és a momentumokat ismertetjük részletesen.
4.1. Terjedelem
A terjedelem mutató meghatározza, hogy az adott adatsor mekkora tartományt ölel fel, azaz mekkora a legkisebb és legnagyobb értéke.
A terjedelem meghatározásával gyorsan megállapítható például egy mérés-sorozatról, hogy annak valamelyik eleme átlépte-e a határértéket, vagy sem. A terjedelemnek két fő típusát különböztetjük meg:
• amikor a teljes adatsorra vonatkoztatunk, akkor a „rendes” terjedelmet nézzük (jellemzően nem teszünk megkülönböztető jelzőt a megnevezés elé),
• amikor viszont csak egy kisebb részét vizsgáljuk az egésznek (jellemzően egy vagy több kvantilist), akkor interkvantilis vagy nyesett terjedelemről beszélünk.
4.1.1. (Rendes) terjedelem
Példa: Az „Osztályközös gyakoriság számításának lépései” fejezetnél megismert példában szereplő 24 minta esetén, mind MS Office-ban mind LiberOffice-ban azonosan tudjuk megoldani:
3.18. táblázat - Terjedelem meghatározása.
A B C
1 Érték Terjedelem
2 40 Legkisebb =MIN(A2:A25)
3 45 Legnagyobb =MAX(A2:A25)
4 43
5 36
6 39
7 46
8 51
9 57
10 93
11 98
12 67
13 56
14 45
15 56
16 35
17 76
A B C
18 89
19 92
20 54
21 45
22 43
23 38
24 39
25 36
A meghatározás eredményeképpen megtudjuk, hogy a terjedelem 35 és 98 között van.
4.1.2. Interkvantilis (nyesett) terjedelem
Az interkvantilis terjedelem meghatározása során egyszerűen vesszük a kiválasztott kvantilisek két szélső darabját és azok értéke lesz a terjedelem.
A leggyakrabban használt két interkvantilis terjedelem a decilisből (a középső 80%-ot szokták így meghatározni), illetve a kvartilisből képzett (így pedig a középső 50%-ot lehet meghatározni). A kvartilisből képzett értéket nagyon gyakran Box-and-whiskers módszernek is hívják.
Példa: Ábrázoljuk az „Osztályközös gyakoriság számításának lépései” fejezetnél megismert példában szereplő 24 minta esetén a Box-and-whiskers értéket a mediánhoz képest.
Vegyük a „Kvantilisek” fejezetben meghatározott kvartilis értékek kvantilisét:
Q1 = 39,25 Q2 = 45,50 Q3 = 64,50
Ezután vegyük az első és a harmadik kvartilis kvantilis értéket, majd ábrázoljuk azt egy számegyenesen:
3.6. ábra - Vizsgált adatsor jellemzői számegyenesen
3.7. ábra - Vizsgált adatsor jellemzői
A példa jól megmutatja, hogy ha:
• csak a teljes terjedelemre elemzünk, akkor úgy vélhetnénk, hogy nagyon szélsőséges értékek között mozog (35-98)
• ha már a medián értékét is figyelembe vesszük (Me=45,5), akkor sokkal jobb rálátásunk lesz az adatsorra, mivel kiderül, hogy az adatok a tartomány alsóbb régiójában összpontosulnak,
• végül – anélkül, hogy túlzottan bele kellene mélyedni az adatokba – a box-and-whiskers értékkel egészen pontosan be tudjuk határolni, hogy a jellemző mérési értékek a 39 és 65 közötti tartományban találhatóak.
4.2. Statisztikai momentumok
A statisztikai momentumok közül az átlag és a szóródás információt nyújtanak az adatsor tekintetében a hely és a változékonyság (terjedés, megoszlás) kérdésében és ez által, megközelítő tájékoztatást nyújtanak azok eloszlásáról (mint azt például egy fényképről készült hisztogram esetében). Az átlag és a szóródás az első két statisztikai momentum, míg a harmadik és a negyedik momentumok tájékoztatást nyújtanak az eloszlás alakjáról és változékonyságáról.
Ezek az információk elsődleges célja a gyors, és hatékony adat-áttekinthetőség elérése. Ezek közül a környezetvédelemben a szóródás a leggyakrabban használt művelet.
4.2.1. Szóródás (σ)
A szóródás az átlagtól történő eltérést mutatja meg. Mérőszáma a szórás. A szórás értéke tájékoztatást ad arról, hogy mennyire egységes az adatállomány. Kifejezetten fontos érték, ha egy mérőműszer pontosságáról, egy mérés megbízhatóságáról kívánunk tudást szerezni.
Számítása súlyozott és súlyozatlan úton lehetséges. Az utóbbi módszer használata gyakoribb a mérési módszer ellenőrzésekor. Az előbbit alkalmazzuk például hatástanulmányok esetében, amikor a környezet több elemének változásának átlagos eltérésére vagyunk kíváncsiak, de a környezeti elemeket nem egyenlő súllyal kívánjuk figyelembe venni (például a vizet érintő változásokat kiemelten kívánjuk kezelni).
A számítás során gyakorlatilag az egyedi értékeket hasonlítjuk össze az átlaggal, majd negatív értékek elkerülése érdekében négyzetre emeljük és a végén az átlagból gyököt vonunk.
Súlyozatlan esetben a számítás:
Súlyozott esetben a számítás:
Példa:
Egy 15 km hosszú védett folyó-területen, 1 km-ként mérték fel a fajgazdagságot (hány féle fajt találtak az adott területen), illetve meghatározták a folyó vízminőségi kategóriáját. Kérdés milyen szórást mutat a folyó vízminőségi kategóriája, illetve milyen súlyozott szórást mutat ez az érték, ha figyelembe vesszük a fajgazdagságot is.
Súlyozatlan esetben, mind MS Office-ban mind LiberOffice-ban megbízható függvényt tudunk használni.
3.19. táblázat - Szórás meghatározása.
A
1 Kategória
A
2 5
3 5
4 4
5 3
6 4
7 5
8 5
9 4
10 5
11 5
12 4
13 3
14 2
15 4
16 5
17 0,909*
* MS Office esetében: =SZÓR.S(A2:A16)
* LiberOffice esetében: =SZÓRÁSP(A2:A16)
Súlyozott esetben sem a MS Office-ban sem a LiberOffice-ban nem találunk függvényt a megoldásra, így a példában szereplő 15 minta esetén, a következő képletrendszerrel tudjuk elvégezni a számítást (mindkét esetben azonos képletekkel).
3.20. táblázat - Súlyozott szórás meghatározása.
A B C D
1 Kategória Fajgazdagság Segédoszlop
2 5 104 =F2*HATVÁNY((A
2-$D$3);2)
Átlag:
3 5 97 =F2*HATVÁNY((A
3-$D$3);2)
=ÁTLAG(A2:A16)
A B C D
1 Kategória Fajgazdagság Segédoszlop
4 4 117 =F2*HATVÁNY((A
4-$D$3);2)
5 3 110 =F2*HATVÁNY((A
5-$D$3);2)
=SZUM(B2:B16)
6 4 76 =F2*HATVÁNY((A
6-$D$3);2)
Segédátlag
7 5 140 =F2*HATVÁNY((A
7-$D$3);2)
=ÁTLAG(C2:C16)
8 5 131 =F2*HATVÁNY((A
8-$D$3);2)
Szórás
9 4 132 =F2*HATVÁNY((A
9-$D$3);2)
=GYÖK(D7/D5)
10 5 107 =F2*HATVÁNY((A
10-$D$3);2)
11 5 119 =F2*HATVÁNY((A
11-$D$3);2)
12 4 96 =F2*HATVÁNY((A
12-$D$3);2)
13 3 103 =F2*HATVÁNY((A
13-$D$3);2)
14 2 89 =F2*HATVÁNY((A
14-$D$3);2)
15 4 108 =F2*HATVÁNY((A
15-$D$3);2)
16 5 110 =F2*HATVÁNY((A
16-$E$3);2)
4.2.2. Relatív szóródás
Sok esetben a szóródás önmagában nem segít a valós helyzet felmérésben, ami számos félreértelmezéshez vezethet. Amikor kijelentjük egy mérésről, hogy a szóródása 19,62 mg/m3, az számos esetben nem ad elég tájékozódási alapot. Sok ez az érték? Kevés ez az érték? Ha például a mérés 100 000 mg/m3 nagyságrendű, akkor a szóródás kiváló mérési pontosságot takar, de ha a mérés 100 mg/m3 nagyságrendű, akkor komoly fenntartásaink lehetnek a méréssel kapcsolatban.
Ezt a bizonytalanságot csökkenti a relatív szóródás kiszámítása, ami százalékos formában adja meg a szórás és az számtani átlag hányadosát.
Számítása:
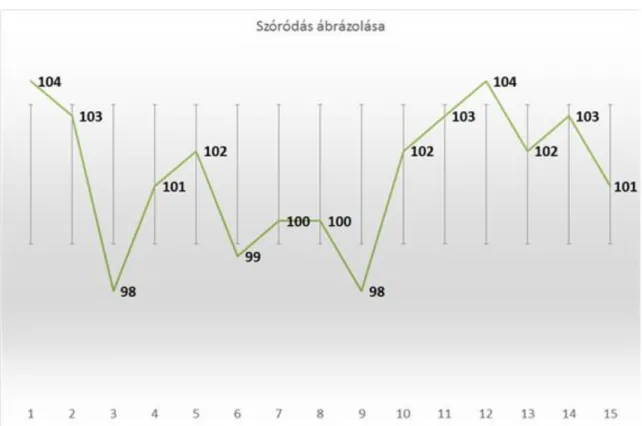
Példa:
Egy kalibrációs mérési sorozat eredményei alapján határozzuk meg a szóródást és a relatív szóródást. A megoldás mind MS Office-ban mind LiberOffice-ban beépített függvények segítségével lehetséges.
3.21. táblázat - Relatív szóródás meghatározása.
A B
1 Mért érték
(mg/l)
2 104
3 103
4 98
5 101
6 102
7 99
8 100
9 100
10 98
11 102
12 103
13 104
14 102
15 103
16 101
17 Szóródás 1,92* mg/l
18 Relatív szóródás 1,90** %
* MS Office esetében: =SZÓR.S(B2:B16)
* LiberOffice esetében: =SZÓRÁSP(B2:B16)
** MS Office és LiberOffice esetében: =100*(B18/ÁTLAG(B3:B17)) A standard deviancia ábrázolása a fenti adatsorra:
3.8. ábra - A standard deviancia ábrázolása
4.2.3. Általános (abszolút) különbség
A szóródás vizsgálatának egy másik elve, amelyet Corrado Gini alkotott meg, azt vizsgálja, hogy az ismérvek mennyire különböznek egymástól. Ezt a vizsgálatot általános vagy abszolút különbségnek hívjuk. Az elemzés kifejezetten hasznos, ha a szélsőségekre szeretnénk választ kapni. Ennél a vizsgálati módszernél már néhány, az átlagtól kiugróan eltérő ismérv is jelentősen megemeli a különbség értékét.
Lehetséges súlyozott és súlyozatlan módon is számolni. Képlet a következő:
Súlyozatlan:
Súlyozott:
Példa:
A „Szóródás (δ)” fejezetben megismert példán számítsuk ki az átlagos különbség súlyozatlan és súlyozott értékét.
A feladatot kényelmesen MS Office-ban és LibreOffice-ban is csak makro nyelven tudjuk megoldani. A makró forráskódja a következő:
3.22. táblázat - Különbség számításához alapadatok
A B
1 Kategória Fajgazdagság
2 5 104
3 5 97
4 4 117
5 3 110
6 4 76
7 5 140
8 5 131
9 4 132
10 5 107
11 5 119
12 4 96
13 3 103
14 2 89
15 4 108
16 5 110
17 Átlagos különbség
18 Súlyozatlan 1,00952381*
19 Súlyozott 11554,01905*
* A csillaggal jelzett számokat a makro írta be.
'
'Átlagos különbség számítása '
'(C)2011 Dr. Domokos Endre '
Sub Súlyozatlan() Dim r, t, N As Integer Dim Különbség, G As Double N = 15
Különbség = 0 For t = 2 To N + 1 For r = 2 To N + 1
Különbség = Különbség + Abs(Cells(t, 1) - Cells(r, 1)) Next r
Next t
G = (1 / (N * (N - 1))) * Különbség Cells(N + 3, 2) = G
End Sub Sub Súlyozott()
Dim r, t, N As Integer Dim Különbség, G As Double N = 15
Különbség = 0 For t = 2 To N + 1 For r = 2 To N + 1
Különbség = Különbség + (Cells(t, 2) * Cells(r, 2) * Abs(Cells(t, 1) - Cells(r, 1))) Next r
Next t
G = (1 / (N * (N - 1))) * Különbség Cells(N + 4, 2) = G
End Sub
4.2.4. Momentum
A szóródások egy különleges fajtája a momentum képzés, amelynek során a szóródást egy tetszőlegesen kiválasztott (akár az ismérvek között nem szereplő) értékhez viszonyítjuk. Kiválóan lehet használni e módszert műszerek teljes pontosságának meghatározására, amikor egy ismert (beállító) érték mérése során mért értékeket viszonyítunk a beállító értékhez.
Gyakorlatban a momentum képzés az átlagok és a szórások általános felírása. Általános megfogalmazása a következő: Y ismérv vagy gyakorisági eloszlás A körüli r-ed rendű momentumai.
Számítása súlyozatlan esetben:
Súlyozott esetben:
Néhány nevezetes momentum:
Számtani átlag (r=1, A=0):
Négyzetes átlag négyzete (r=2, A=0):
Variancia (r=2, ):
Megbízhatóság (r=2, A =beállító érték)
Példa:
A „Relatív szóródás” fejezetben megismert példa során a mérést 100 mg/l-es sűrűségű mintával végeztük.
Számítsuk ki a megbízhatóságát a berendezésnek.
3.23. táblázat - Momentum számítás (berendezés megbízhatósága)
A B C D
1 Mért érték
(mg/l)
Segédoszlop Beállító
sűrűség
2 104 =HATVÁNY(B2-
$D$2;2)
100
3 103 =HATVÁNY(B3-
$D$2;2)
mg/l
4 98 =HATVÁNY(B4-
$D$2;2)
5 101 =HATVÁNY(B5-
$D$2;2)
6 102 =HATVÁNY(B6-